Annotab Studio 2.0.0 is now live
The Ultimate Guide to Semi-Supervised Learning
The Ultimate Guide to Semi-Supervised Learning
The Ultimate Guide to Semi-Supervised Learning
The Ultimate Guide to Semi-Supervised Learning
Published by

Abirami Vina
on
Jan 2, 2024
under
Computer Vision
Published by
Abirami Vina
on
Jan 2, 2024
under
Computer Vision
Published by
Abirami Vina
on
Jan 2, 2024
under
Computer Vision
Published by
Abirami Vina
on
Jan 2, 2024
under
Computer Vision
ON THIS PAGE
Tl;dr
Tired of labeling endless data sets? Craving powerful AI models without breaking the bank? Look no further than semi-supervised learning, the game-changer that leverages both labeled and unlabeled data for exceptional results. This comprehensive guide dives deep into the world of semi-supervised learning, allowing you to master the fundamentals and explore its applications.
Tl;dr
Tired of labeling endless data sets? Craving powerful AI models without breaking the bank? Look no further than semi-supervised learning, the game-changer that leverages both labeled and unlabeled data for exceptional results. This comprehensive guide dives deep into the world of semi-supervised learning, allowing you to master the fundamentals and explore its applications.
Tl;dr
Tired of labeling endless data sets? Craving powerful AI models without breaking the bank? Look no further than semi-supervised learning, the game-changer that leverages both labeled and unlabeled data for exceptional results. This comprehensive guide dives deep into the world of semi-supervised learning, allowing you to master the fundamentals and explore its applications.
Tl;dr
Tired of labeling endless data sets? Craving powerful AI models without breaking the bank? Look no further than semi-supervised learning, the game-changer that leverages both labeled and unlabeled data for exceptional results. This comprehensive guide dives deep into the world of semi-supervised learning, allowing you to master the fundamentals and explore its applications.

Introduction
Machine learning applications like self-driving cars and virtual assistants are all around us. Innovations enabled by machine learning make our day-to-day lives easier and open doors to new possibilities. But what exactly is machine learning? Simply put, machine learning is a branch of artificial intelligence that analyzes vast amounts of data to find patterns and insights we can't easily see.
There are three main types of machine learning: supervised, unsupervised, and semi-supervised learning. In supervised learning, models learn from labeled data. You can think of it as having a teacher who can show the student actual examples. In unsupervised learning, patterns are recognized from unlabeled data. It is similar to learning without a teacher and examples of the correct answers. Semi-supervised learning is especially interesting because it uses both labeled and unlabeled data to train a model.
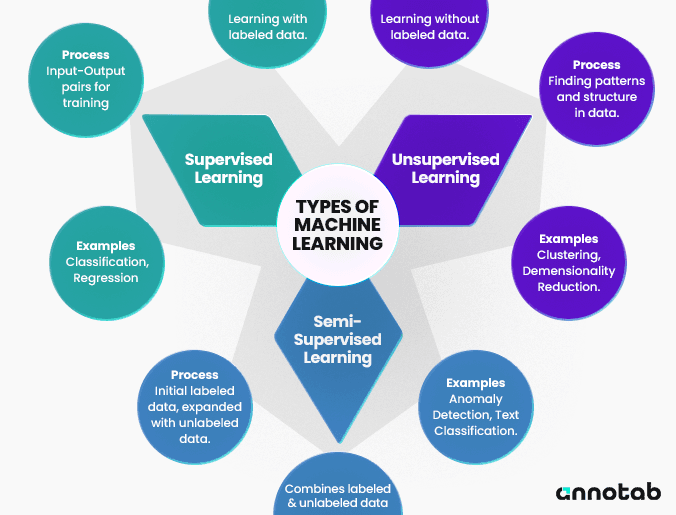
A mind map illustrating different types of machine learning.
When you develop a machine learning solution, finding or creating a fully labeled dataset is often tricky. This is where semi-supervised learning becomes useful. The training process of semi-supervised learning begins with a small amount of labeled data to teach the model the basic patterns. Then, it applies this understanding to the more significant amount of unlabeled data. The model is further improved and refined as it uncovers more information. It's a cost-effective and efficient machine learning method when data labeling resources are limited. However, it’s important to remember that proper data annotation is crucial to ensure that the initial labeled data sets the right foundation for the model's learning and efficiency.
Next, let’s dive into the details of semi-supervised learning and understand how it works from end to end. We’ll also take a look at how semi-supervised learning can be applied, the related challenges, best practices, and the future.
Introduction
Machine learning applications like self-driving cars and virtual assistants are all around us. Innovations enabled by machine learning make our day-to-day lives easier and open doors to new possibilities. But what exactly is machine learning? Simply put, machine learning is a branch of artificial intelligence that analyzes vast amounts of data to find patterns and insights we can't easily see.
There are three main types of machine learning: supervised, unsupervised, and semi-supervised learning. In supervised learning, models learn from labeled data. You can think of it as having a teacher who can show the student actual examples. In unsupervised learning, patterns are recognized from unlabeled data. It is similar to learning without a teacher and examples of the correct answers. Semi-supervised learning is especially interesting because it uses both labeled and unlabeled data to train a model.
A mind map illustrating different types of machine learning.
When you develop a machine learning solution, finding or creating a fully labeled dataset is often tricky. This is where semi-supervised learning becomes useful. The training process of semi-supervised learning begins with a small amount of labeled data to teach the model the basic patterns. Then, it applies this understanding to the more significant amount of unlabeled data. The model is further improved and refined as it uncovers more information. It's a cost-effective and efficient machine learning method when data labeling resources are limited. However, it’s important to remember that proper data annotation is crucial to ensure that the initial labeled data sets the right foundation for the model's learning and efficiency.
Next, let’s dive into the details of semi-supervised learning and understand how it works from end to end. We’ll also take a look at how semi-supervised learning can be applied, the related challenges, best practices, and the future.
Introduction
Machine learning applications like self-driving cars and virtual assistants are all around us. Innovations enabled by machine learning make our day-to-day lives easier and open doors to new possibilities. But what exactly is machine learning? Simply put, machine learning is a branch of artificial intelligence that analyzes vast amounts of data to find patterns and insights we can't easily see.
There are three main types of machine learning: supervised, unsupervised, and semi-supervised learning. In supervised learning, models learn from labeled data. You can think of it as having a teacher who can show the student actual examples. In unsupervised learning, patterns are recognized from unlabeled data. It is similar to learning without a teacher and examples of the correct answers. Semi-supervised learning is especially interesting because it uses both labeled and unlabeled data to train a model.
A mind map illustrating different types of machine learning.
When you develop a machine learning solution, finding or creating a fully labeled dataset is often tricky. This is where semi-supervised learning becomes useful. The training process of semi-supervised learning begins with a small amount of labeled data to teach the model the basic patterns. Then, it applies this understanding to the more significant amount of unlabeled data. The model is further improved and refined as it uncovers more information. It's a cost-effective and efficient machine learning method when data labeling resources are limited. However, it’s important to remember that proper data annotation is crucial to ensure that the initial labeled data sets the right foundation for the model's learning and efficiency.
Next, let’s dive into the details of semi-supervised learning and understand how it works from end to end. We’ll also take a look at how semi-supervised learning can be applied, the related challenges, best practices, and the future.
Introduction
Machine learning applications like self-driving cars and virtual assistants are all around us. Innovations enabled by machine learning make our day-to-day lives easier and open doors to new possibilities. But what exactly is machine learning? Simply put, machine learning is a branch of artificial intelligence that analyzes vast amounts of data to find patterns and insights we can't easily see.
There are three main types of machine learning: supervised, unsupervised, and semi-supervised learning. In supervised learning, models learn from labeled data. You can think of it as having a teacher who can show the student actual examples. In unsupervised learning, patterns are recognized from unlabeled data. It is similar to learning without a teacher and examples of the correct answers. Semi-supervised learning is especially interesting because it uses both labeled and unlabeled data to train a model.
A mind map illustrating different types of machine learning.
When you develop a machine learning solution, finding or creating a fully labeled dataset is often tricky. This is where semi-supervised learning becomes useful. The training process of semi-supervised learning begins with a small amount of labeled data to teach the model the basic patterns. Then, it applies this understanding to the more significant amount of unlabeled data. The model is further improved and refined as it uncovers more information. It's a cost-effective and efficient machine learning method when data labeling resources are limited. However, it’s important to remember that proper data annotation is crucial to ensure that the initial labeled data sets the right foundation for the model's learning and efficiency.
Next, let’s dive into the details of semi-supervised learning and understand how it works from end to end. We’ll also take a look at how semi-supervised learning can be applied, the related challenges, best practices, and the future.
Understanding Semi-Supervised Learning
There are special techniques under the hood of semi-supervised learning that enable the model to use limited labeled data effectively. One of those techniques is pseudo-labeling.
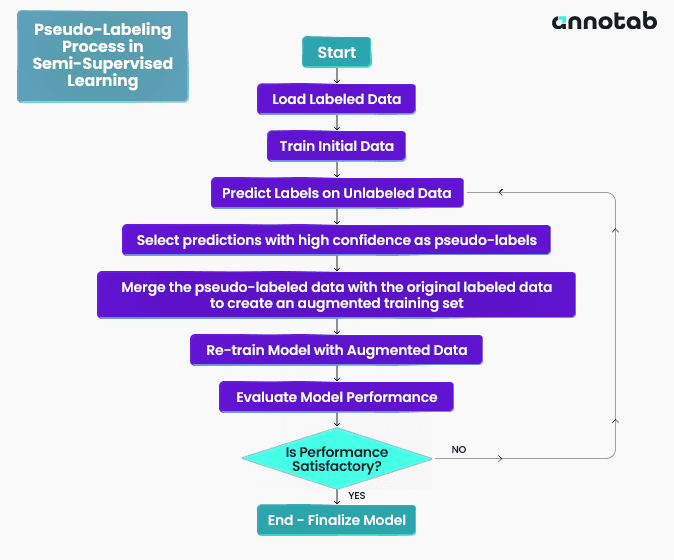
A process flowchart for pseudo-labeling in semi-supervised learning.
Pseudo-labeling involves using the model’s current understanding (from the initial labeled data) to assign labels to the unlabeled data. These pseudo-labels are not true labels but are the model's best guess based on its current state. The pseudo-labeled data is then added to the training set. The model retrains on this augmented dataset (which now includes both the original labeled data and the pseudo-labeled data). This process is iterative. With each cycle, the model retrains on a dataset that gradually grows and hopefully becomes more representative of the actual data distribution. As the model's predictions improve, the quality of the pseudo-labels also improves, leading to a more effective learning process.
Another important technique is consistency regularization. Consistency regularization ensures the model's predictions don't change drastically for small variations in the input data. If two data points are similar, the model should ideally produce similar predictions for both. Consistency regularization can be done using data augmentation. A single data point can be slightly modified (for example, by adding noise or applying a rotation) to create a similar but not identical data point. The model should predict the same output for the original and augmented data. Consistency regularization helps prevent overfitting. It learns to focus on the more general patterns that persist despite minor changes in the data, leading to better generalization on new, unseen data. However, too much regularization can lead to underfitting, so it’s important to have a good balance.
Other than these techniques, there are also various essential assumptions related to the data that is used to train a model using semi-supervised learning. These assumptions guide the semi-supervised learning process in identifying patterns and establishing decision boundaries. For example, it is assumed that data points near each other most likely share the same label, and this is called the Continuity Assumption. Similarly, the Cluster Assumption is that discrete data can form clusters, and data in the same cluster most likely has the same label.

A mind map showcasing key assumptions in semi-supervised learning.
In the case the data is high-dimensional, the Manifold Assumption comes into play. It assumes that complex data structures like images and audio can be represented in a simpler, lower-dimensional manifold. Additionally, some models operate on the Semi-supervised Disentanglement Assumption, where using both labeled and unlabeled data means that the model will be able to unravel the differences in the data more easily and lead to better feature representation and generalization.
Now that we’ve understood the different technical intricacies involved in semi-supervised learning. Let’s explore where semi-supervised learning can be applied in the real world.
Understanding Semi-Supervised Learning
There are special techniques under the hood of semi-supervised learning that enable the model to use limited labeled data effectively. One of those techniques is pseudo-labeling.
A process flowchart for pseudo-labeling in semi-supervised learning.
Pseudo-labeling involves using the model’s current understanding (from the initial labeled data) to assign labels to the unlabeled data. These pseudo-labels are not true labels but are the model's best guess based on its current state. The pseudo-labeled data is then added to the training set. The model retrains on this augmented dataset (which now includes both the original labeled data and the pseudo-labeled data). This process is iterative. With each cycle, the model retrains on a dataset that gradually grows and hopefully becomes more representative of the actual data distribution. As the model's predictions improve, the quality of the pseudo-labels also improves, leading to a more effective learning process.
Another important technique is consistency regularization. Consistency regularization ensures the model's predictions don't change drastically for small variations in the input data. If two data points are similar, the model should ideally produce similar predictions for both. Consistency regularization can be done using data augmentation. A single data point can be slightly modified (for example, by adding noise or applying a rotation) to create a similar but not identical data point. The model should predict the same output for the original and augmented data. Consistency regularization helps prevent overfitting. It learns to focus on the more general patterns that persist despite minor changes in the data, leading to better generalization on new, unseen data. However, too much regularization can lead to underfitting, so it’s important to have a good balance.
Other than these techniques, there are also various essential assumptions related to the data that is used to train a model using semi-supervised learning. These assumptions guide the semi-supervised learning process in identifying patterns and establishing decision boundaries. For example, it is assumed that data points near each other most likely share the same label, and this is called the Continuity Assumption. Similarly, the Cluster Assumption is that discrete data can form clusters, and data in the same cluster most likely has the same label.
A mind map showcasing key assumptions in semi-supervised learning.
In the case the data is high-dimensional, the Manifold Assumption comes into play. It assumes that complex data structures like images and audio can be represented in a simpler, lower-dimensional manifold. Additionally, some models operate on the Semi-supervised Disentanglement Assumption, where using both labeled and unlabeled data means that the model will be able to unravel the differences in the data more easily and lead to better feature representation and generalization.
Now that we’ve understood the different technical intricacies involved in semi-supervised learning. Let’s explore where semi-supervised learning can be applied in the real world.
Understanding Semi-Supervised Learning
There are special techniques under the hood of semi-supervised learning that enable the model to use limited labeled data effectively. One of those techniques is pseudo-labeling.
A process flowchart for pseudo-labeling in semi-supervised learning.
Pseudo-labeling involves using the model’s current understanding (from the initial labeled data) to assign labels to the unlabeled data. These pseudo-labels are not true labels but are the model's best guess based on its current state. The pseudo-labeled data is then added to the training set. The model retrains on this augmented dataset (which now includes both the original labeled data and the pseudo-labeled data). This process is iterative. With each cycle, the model retrains on a dataset that gradually grows and hopefully becomes more representative of the actual data distribution. As the model's predictions improve, the quality of the pseudo-labels also improves, leading to a more effective learning process.
Another important technique is consistency regularization. Consistency regularization ensures the model's predictions don't change drastically for small variations in the input data. If two data points are similar, the model should ideally produce similar predictions for both. Consistency regularization can be done using data augmentation. A single data point can be slightly modified (for example, by adding noise or applying a rotation) to create a similar but not identical data point. The model should predict the same output for the original and augmented data. Consistency regularization helps prevent overfitting. It learns to focus on the more general patterns that persist despite minor changes in the data, leading to better generalization on new, unseen data. However, too much regularization can lead to underfitting, so it’s important to have a good balance.
Other than these techniques, there are also various essential assumptions related to the data that is used to train a model using semi-supervised learning. These assumptions guide the semi-supervised learning process in identifying patterns and establishing decision boundaries. For example, it is assumed that data points near each other most likely share the same label, and this is called the Continuity Assumption. Similarly, the Cluster Assumption is that discrete data can form clusters, and data in the same cluster most likely has the same label.
A mind map showcasing key assumptions in semi-supervised learning.
In the case the data is high-dimensional, the Manifold Assumption comes into play. It assumes that complex data structures like images and audio can be represented in a simpler, lower-dimensional manifold. Additionally, some models operate on the Semi-supervised Disentanglement Assumption, where using both labeled and unlabeled data means that the model will be able to unravel the differences in the data more easily and lead to better feature representation and generalization.
Now that we’ve understood the different technical intricacies involved in semi-supervised learning. Let’s explore where semi-supervised learning can be applied in the real world.
Understanding Semi-Supervised Learning
There are special techniques under the hood of semi-supervised learning that enable the model to use limited labeled data effectively. One of those techniques is pseudo-labeling.
A process flowchart for pseudo-labeling in semi-supervised learning.
Pseudo-labeling involves using the model’s current understanding (from the initial labeled data) to assign labels to the unlabeled data. These pseudo-labels are not true labels but are the model's best guess based on its current state. The pseudo-labeled data is then added to the training set. The model retrains on this augmented dataset (which now includes both the original labeled data and the pseudo-labeled data). This process is iterative. With each cycle, the model retrains on a dataset that gradually grows and hopefully becomes more representative of the actual data distribution. As the model's predictions improve, the quality of the pseudo-labels also improves, leading to a more effective learning process.
Another important technique is consistency regularization. Consistency regularization ensures the model's predictions don't change drastically for small variations in the input data. If two data points are similar, the model should ideally produce similar predictions for both. Consistency regularization can be done using data augmentation. A single data point can be slightly modified (for example, by adding noise or applying a rotation) to create a similar but not identical data point. The model should predict the same output for the original and augmented data. Consistency regularization helps prevent overfitting. It learns to focus on the more general patterns that persist despite minor changes in the data, leading to better generalization on new, unseen data. However, too much regularization can lead to underfitting, so it’s important to have a good balance.
Other than these techniques, there are also various essential assumptions related to the data that is used to train a model using semi-supervised learning. These assumptions guide the semi-supervised learning process in identifying patterns and establishing decision boundaries. For example, it is assumed that data points near each other most likely share the same label, and this is called the Continuity Assumption. Similarly, the Cluster Assumption is that discrete data can form clusters, and data in the same cluster most likely has the same label.
A mind map showcasing key assumptions in semi-supervised learning.
In the case the data is high-dimensional, the Manifold Assumption comes into play. It assumes that complex data structures like images and audio can be represented in a simpler, lower-dimensional manifold. Additionally, some models operate on the Semi-supervised Disentanglement Assumption, where using both labeled and unlabeled data means that the model will be able to unravel the differences in the data more easily and lead to better feature representation and generalization.
Now that we’ve understood the different technical intricacies involved in semi-supervised learning. Let’s explore where semi-supervised learning can be applied in the real world.
Applying Semi-Supervised Learning
Semi-supervised learning is a machine learning technique that we come in contact with regularly. We might not notice it, but it works in the background - silently helping make important decisions in different applications.
This technology has applications in industries like healthcare. It can assist with diagnostic processes by analyzing medical images and patient data and help professionals make informed decisions. Semi-supervised learning can also be used in social media to help filter out inappropriate content and recommend relevant posts to users. In the automotive industry, semi-supervised learning is used to develop self-driving car technologies. It helps vehicles understand their environment and make safe driving decisions. Retail and e-commerce platforms use it to analyze customer behavior and preferences and provide personalized recommendations to improve customers' shopping experience. These applications illustrate how semi-supervised learning can be used across various sectors. Now, let’s discuss some fascinating case studies.
Amazon Alexa
One of the popular companies using semi-supervised learning is Amazon. They are using semi-supervised learning to enhance Alexa’s (their intelligent assistant) capabilities. Amazon’s AI Alexa research division is exploring applying semi-supervised and unsupervised learning techniques to give Alexa a better understanding of user queries and more human-like responses. This approach allows models to make conclusions from contextual clues.

A comic showing an improvement in Alexa’s abilities due to semi-supervised learning.
An example is when Alexa assists users by suggesting corrections in commands, such as correcting the name of a controlled device. This improvement comes from Alexa's ability to learn from the context and user interactions over time. Using these techniques, the assistant becomes more intuitive and responsive.
Netflix
Netflix is another company that is using semi-supervised learning in its operations. According to one of their research publications, Netflix has developed a fraud and abuse detection framework for its streaming services. This framework models user streaming behavior to identify anomalous and suspicious activities using semi-supervised and supervised methods.
This is done by feeding the model with authenticated, non-fraudulent user behavior data. This training phase is crucial as it enables the model to learn and understand the standard patterns and behaviors of users on the platform. It establishes a baseline of what is considered 'normal' activity. Once the model can recognize regular user interactions, it applies this knowledge to identify deviations or anomalies. These anomalies are behaviors that are quite different from the established norm. Such deviations could be potential fraudulent or abusive activities on the platform.
Google Search
Google has also been using semi-supervised learning to improve its search engine performance. Semi-supervised learning can especially be helpful when the search engine is trying to understand and process language queries. This advancement is thanks to their development and application of Semi-Supervised Distillation (SSD), a method that simplifies and extends the capabilities of their earlier semi-supervised learning approach, Noisy Student.
SSD is good at mixing a little bit of labeled data with a lot of unlabeled data. This ability is very useful for Google Search. Every day, Google Search deals with a huge variety of different queries. SSD helps manage this big and varied set of search questions. The success of SSD in Google Search shows how powerful semi-supervised learning can be.
The Importance of Data Quality
As powerful as semi-supervised learning can be, it is only as good as the data that is fed into it. Data quality is crucial for success. The accuracy of the small amount of labeled data and the relevance of the larger volume of unlabeled data determine the effectiveness of this approach. High-quality data ensures that the model learns correctly and can generalize well to new scenarios. Without careful attention to data quality, the models may learn from flawed data, leading to inaccurate outcomes. Maintaining high data quality is essential in semi-supervised learning, especially in applications where precision is critical.
Applying Semi-Supervised Learning
Semi-supervised learning is a machine learning technique that we come in contact with regularly. We might not notice it, but it works in the background - silently helping make important decisions in different applications.
This technology has applications in industries like healthcare. It can assist with diagnostic processes by analyzing medical images and patient data and help professionals make informed decisions. Semi-supervised learning can also be used in social media to help filter out inappropriate content and recommend relevant posts to users. In the automotive industry, semi-supervised learning is used to develop self-driving car technologies. It helps vehicles understand their environment and make safe driving decisions. Retail and e-commerce platforms use it to analyze customer behavior and preferences and provide personalized recommendations to improve customers' shopping experience. These applications illustrate how semi-supervised learning can be used across various sectors. Now, let’s discuss some fascinating case studies.
Amazon Alexa
One of the popular companies using semi-supervised learning is Amazon. They are using semi-supervised learning to enhance Alexa’s (their intelligent assistant) capabilities. Amazon’s AI Alexa research division is exploring applying semi-supervised and unsupervised learning techniques to give Alexa a better understanding of user queries and more human-like responses. This approach allows models to make conclusions from contextual clues.
A comic showing an improvement in Alexa’s abilities due to semi-supervised learning.
An example is when Alexa assists users by suggesting corrections in commands, such as correcting the name of a controlled device. This improvement comes from Alexa's ability to learn from the context and user interactions over time. Using these techniques, the assistant becomes more intuitive and responsive.
Netflix
Netflix is another company that is using semi-supervised learning in its operations. According to one of their research publications, Netflix has developed a fraud and abuse detection framework for its streaming services. This framework models user streaming behavior to identify anomalous and suspicious activities using semi-supervised and supervised methods.
This is done by feeding the model with authenticated, non-fraudulent user behavior data. This training phase is crucial as it enables the model to learn and understand the standard patterns and behaviors of users on the platform. It establishes a baseline of what is considered 'normal' activity. Once the model can recognize regular user interactions, it applies this knowledge to identify deviations or anomalies. These anomalies are behaviors that are quite different from the established norm. Such deviations could be potential fraudulent or abusive activities on the platform.
Google Search
Google has also been using semi-supervised learning to improve its search engine performance. Semi-supervised learning can especially be helpful when the search engine is trying to understand and process language queries. This advancement is thanks to their development and application of Semi-Supervised Distillation (SSD), a method that simplifies and extends the capabilities of their earlier semi-supervised learning approach, Noisy Student.
SSD is good at mixing a little bit of labeled data with a lot of unlabeled data. This ability is very useful for Google Search. Every day, Google Search deals with a huge variety of different queries. SSD helps manage this big and varied set of search questions. The success of SSD in Google Search shows how powerful semi-supervised learning can be.
The Importance of Data Quality
As powerful as semi-supervised learning can be, it is only as good as the data that is fed into it. Data quality is crucial for success. The accuracy of the small amount of labeled data and the relevance of the larger volume of unlabeled data determine the effectiveness of this approach. High-quality data ensures that the model learns correctly and can generalize well to new scenarios. Without careful attention to data quality, the models may learn from flawed data, leading to inaccurate outcomes. Maintaining high data quality is essential in semi-supervised learning, especially in applications where precision is critical.
Applying Semi-Supervised Learning
Semi-supervised learning is a machine learning technique that we come in contact with regularly. We might not notice it, but it works in the background - silently helping make important decisions in different applications.
This technology has applications in industries like healthcare. It can assist with diagnostic processes by analyzing medical images and patient data and help professionals make informed decisions. Semi-supervised learning can also be used in social media to help filter out inappropriate content and recommend relevant posts to users. In the automotive industry, semi-supervised learning is used to develop self-driving car technologies. It helps vehicles understand their environment and make safe driving decisions. Retail and e-commerce platforms use it to analyze customer behavior and preferences and provide personalized recommendations to improve customers' shopping experience. These applications illustrate how semi-supervised learning can be used across various sectors. Now, let’s discuss some fascinating case studies.
Amazon Alexa
One of the popular companies using semi-supervised learning is Amazon. They are using semi-supervised learning to enhance Alexa’s (their intelligent assistant) capabilities. Amazon’s AI Alexa research division is exploring applying semi-supervised and unsupervised learning techniques to give Alexa a better understanding of user queries and more human-like responses. This approach allows models to make conclusions from contextual clues.
A comic showing an improvement in Alexa’s abilities due to semi-supervised learning.
An example is when Alexa assists users by suggesting corrections in commands, such as correcting the name of a controlled device. This improvement comes from Alexa's ability to learn from the context and user interactions over time. Using these techniques, the assistant becomes more intuitive and responsive.
Netflix
Netflix is another company that is using semi-supervised learning in its operations. According to one of their research publications, Netflix has developed a fraud and abuse detection framework for its streaming services. This framework models user streaming behavior to identify anomalous and suspicious activities using semi-supervised and supervised methods.
This is done by feeding the model with authenticated, non-fraudulent user behavior data. This training phase is crucial as it enables the model to learn and understand the standard patterns and behaviors of users on the platform. It establishes a baseline of what is considered 'normal' activity. Once the model can recognize regular user interactions, it applies this knowledge to identify deviations or anomalies. These anomalies are behaviors that are quite different from the established norm. Such deviations could be potential fraudulent or abusive activities on the platform.
Google Search
Google has also been using semi-supervised learning to improve its search engine performance. Semi-supervised learning can especially be helpful when the search engine is trying to understand and process language queries. This advancement is thanks to their development and application of Semi-Supervised Distillation (SSD), a method that simplifies and extends the capabilities of their earlier semi-supervised learning approach, Noisy Student.
SSD is good at mixing a little bit of labeled data with a lot of unlabeled data. This ability is very useful for Google Search. Every day, Google Search deals with a huge variety of different queries. SSD helps manage this big and varied set of search questions. The success of SSD in Google Search shows how powerful semi-supervised learning can be.
The Importance of Data Quality
As powerful as semi-supervised learning can be, it is only as good as the data that is fed into it. Data quality is crucial for success. The accuracy of the small amount of labeled data and the relevance of the larger volume of unlabeled data determine the effectiveness of this approach. High-quality data ensures that the model learns correctly and can generalize well to new scenarios. Without careful attention to data quality, the models may learn from flawed data, leading to inaccurate outcomes. Maintaining high data quality is essential in semi-supervised learning, especially in applications where precision is critical.
Applying Semi-Supervised Learning
Semi-supervised learning is a machine learning technique that we come in contact with regularly. We might not notice it, but it works in the background - silently helping make important decisions in different applications.
This technology has applications in industries like healthcare. It can assist with diagnostic processes by analyzing medical images and patient data and help professionals make informed decisions. Semi-supervised learning can also be used in social media to help filter out inappropriate content and recommend relevant posts to users. In the automotive industry, semi-supervised learning is used to develop self-driving car technologies. It helps vehicles understand their environment and make safe driving decisions. Retail and e-commerce platforms use it to analyze customer behavior and preferences and provide personalized recommendations to improve customers' shopping experience. These applications illustrate how semi-supervised learning can be used across various sectors. Now, let’s discuss some fascinating case studies.
Amazon Alexa
One of the popular companies using semi-supervised learning is Amazon. They are using semi-supervised learning to enhance Alexa’s (their intelligent assistant) capabilities. Amazon’s AI Alexa research division is exploring applying semi-supervised and unsupervised learning techniques to give Alexa a better understanding of user queries and more human-like responses. This approach allows models to make conclusions from contextual clues.
A comic showing an improvement in Alexa’s abilities due to semi-supervised learning.
An example is when Alexa assists users by suggesting corrections in commands, such as correcting the name of a controlled device. This improvement comes from Alexa's ability to learn from the context and user interactions over time. Using these techniques, the assistant becomes more intuitive and responsive.
Netflix
Netflix is another company that is using semi-supervised learning in its operations. According to one of their research publications, Netflix has developed a fraud and abuse detection framework for its streaming services. This framework models user streaming behavior to identify anomalous and suspicious activities using semi-supervised and supervised methods.
This is done by feeding the model with authenticated, non-fraudulent user behavior data. This training phase is crucial as it enables the model to learn and understand the standard patterns and behaviors of users on the platform. It establishes a baseline of what is considered 'normal' activity. Once the model can recognize regular user interactions, it applies this knowledge to identify deviations or anomalies. These anomalies are behaviors that are quite different from the established norm. Such deviations could be potential fraudulent or abusive activities on the platform.
Google Search
Google has also been using semi-supervised learning to improve its search engine performance. Semi-supervised learning can especially be helpful when the search engine is trying to understand and process language queries. This advancement is thanks to their development and application of Semi-Supervised Distillation (SSD), a method that simplifies and extends the capabilities of their earlier semi-supervised learning approach, Noisy Student.
SSD is good at mixing a little bit of labeled data with a lot of unlabeled data. This ability is very useful for Google Search. Every day, Google Search deals with a huge variety of different queries. SSD helps manage this big and varied set of search questions. The success of SSD in Google Search shows how powerful semi-supervised learning can be.
The Importance of Data Quality
As powerful as semi-supervised learning can be, it is only as good as the data that is fed into it. Data quality is crucial for success. The accuracy of the small amount of labeled data and the relevance of the larger volume of unlabeled data determine the effectiveness of this approach. High-quality data ensures that the model learns correctly and can generalize well to new scenarios. Without careful attention to data quality, the models may learn from flawed data, leading to inaccurate outcomes. Maintaining high data quality is essential in semi-supervised learning, especially in applications where precision is critical.
The Role of Image Annotation in Semi-supervised Learning
The quality of labeled data, especially in the context of image-based models, can be significantly improved with high-quality image annotation. Image annotation involves labeling or marking images with relevant information that helps machine learning models understand and interpret visual data. This process can include identifying objects, marking their locations, shapes, and sizes, or even categorizing entire scenes. Properly annotated images lay the groundwork for more accurate and reliable semi-supervised learning models by providing clear, well-defined, labeled data that guides the learning process.
There are different types of image annotations depending on the task that they are meant for. Bounding boxes involve drawing rectangles around objects in an image to aid in object detection and localization. Segmentation offers a more detailed approach by outlining the exact shape of an object for applications requiring precise object outlines.

A mind map of the different types of image annotations.
Landmark annotation focuses on identifying specific points in an image, like facial features in portraits used for facial recognition. Polyline annotation is used for marking paths or roads in images meant for autonomous vehicle navigation systems. Also, text annotation involves identifying and transcribing text present within images.
Annotab Studio: Your Go-To Image Annotation Tool
High-quality image annotation enhances semi-supervised learning models. Precise and detailed annotations give semi-supervised learning models clear examples to learn from and improve their ability to generalize this knowledge to unlabeled data. Annotab Studio is an ideal choice for those looking to enhance their semi-supervised learning models with high-quality image annotations.
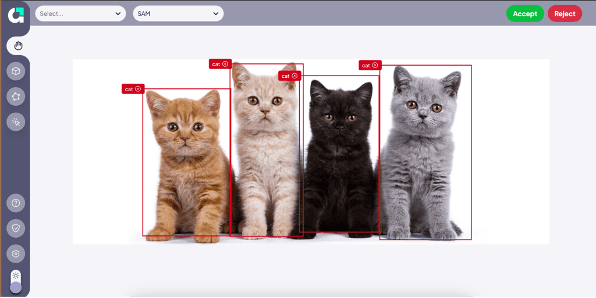
You can easily review annotations on Annotab Studio.
It offers a user-friendly platform that simplifies the process of creating precise and detailed annotations, and it’s suitable for a wide range of applications. With its versatile annotation capabilities, Annotab Studio ensures that your semi-supervised learning models are trained on well-defined and accurate data. Choosing Annotab Studio means equipping your models with the best possible data foundation for superior performance and accuracy.
The Role of Image Annotation in Semi-supervised Learning
The quality of labeled data, especially in the context of image-based models, can be significantly improved with high-quality image annotation. Image annotation involves labeling or marking images with relevant information that helps machine learning models understand and interpret visual data. This process can include identifying objects, marking their locations, shapes, and sizes, or even categorizing entire scenes. Properly annotated images lay the groundwork for more accurate and reliable semi-supervised learning models by providing clear, well-defined, labeled data that guides the learning process.
There are different types of image annotations depending on the task that they are meant for. Bounding boxes involve drawing rectangles around objects in an image to aid in object detection and localization. Segmentation offers a more detailed approach by outlining the exact shape of an object for applications requiring precise object outlines.
A mind map of the different types of image annotations.
Landmark annotation focuses on identifying specific points in an image, like facial features in portraits used for facial recognition. Polyline annotation is used for marking paths or roads in images meant for autonomous vehicle navigation systems. Also, text annotation involves identifying and transcribing text present within images.
Annotab Studio: Your Go-To Image Annotation Tool
High-quality image annotation enhances semi-supervised learning models. Precise and detailed annotations give semi-supervised learning models clear examples to learn from and improve their ability to generalize this knowledge to unlabeled data. Annotab Studio is an ideal choice for those looking to enhance their semi-supervised learning models with high-quality image annotations.
You can easily review annotations on Annotab Studio.
It offers a user-friendly platform that simplifies the process of creating precise and detailed annotations, and it’s suitable for a wide range of applications. With its versatile annotation capabilities, Annotab Studio ensures that your semi-supervised learning models are trained on well-defined and accurate data. Choosing Annotab Studio means equipping your models with the best possible data foundation for superior performance and accuracy.
The Role of Image Annotation in Semi-supervised Learning
The quality of labeled data, especially in the context of image-based models, can be significantly improved with high-quality image annotation. Image annotation involves labeling or marking images with relevant information that helps machine learning models understand and interpret visual data. This process can include identifying objects, marking their locations, shapes, and sizes, or even categorizing entire scenes. Properly annotated images lay the groundwork for more accurate and reliable semi-supervised learning models by providing clear, well-defined, labeled data that guides the learning process.
There are different types of image annotations depending on the task that they are meant for. Bounding boxes involve drawing rectangles around objects in an image to aid in object detection and localization. Segmentation offers a more detailed approach by outlining the exact shape of an object for applications requiring precise object outlines.
A mind map of the different types of image annotations.
Landmark annotation focuses on identifying specific points in an image, like facial features in portraits used for facial recognition. Polyline annotation is used for marking paths or roads in images meant for autonomous vehicle navigation systems. Also, text annotation involves identifying and transcribing text present within images.
Annotab Studio: Your Go-To Image Annotation Tool
High-quality image annotation enhances semi-supervised learning models. Precise and detailed annotations give semi-supervised learning models clear examples to learn from and improve their ability to generalize this knowledge to unlabeled data. Annotab Studio is an ideal choice for those looking to enhance their semi-supervised learning models with high-quality image annotations.
You can easily review annotations on Annotab Studio.
It offers a user-friendly platform that simplifies the process of creating precise and detailed annotations, and it’s suitable for a wide range of applications. With its versatile annotation capabilities, Annotab Studio ensures that your semi-supervised learning models are trained on well-defined and accurate data. Choosing Annotab Studio means equipping your models with the best possible data foundation for superior performance and accuracy.
The Role of Image Annotation in Semi-supervised Learning
The quality of labeled data, especially in the context of image-based models, can be significantly improved with high-quality image annotation. Image annotation involves labeling or marking images with relevant information that helps machine learning models understand and interpret visual data. This process can include identifying objects, marking their locations, shapes, and sizes, or even categorizing entire scenes. Properly annotated images lay the groundwork for more accurate and reliable semi-supervised learning models by providing clear, well-defined, labeled data that guides the learning process.
There are different types of image annotations depending on the task that they are meant for. Bounding boxes involve drawing rectangles around objects in an image to aid in object detection and localization. Segmentation offers a more detailed approach by outlining the exact shape of an object for applications requiring precise object outlines.
A mind map of the different types of image annotations.
Landmark annotation focuses on identifying specific points in an image, like facial features in portraits used for facial recognition. Polyline annotation is used for marking paths or roads in images meant for autonomous vehicle navigation systems. Also, text annotation involves identifying and transcribing text present within images.
Annotab Studio: Your Go-To Image Annotation Tool
High-quality image annotation enhances semi-supervised learning models. Precise and detailed annotations give semi-supervised learning models clear examples to learn from and improve their ability to generalize this knowledge to unlabeled data. Annotab Studio is an ideal choice for those looking to enhance their semi-supervised learning models with high-quality image annotations.
You can easily review annotations on Annotab Studio.
It offers a user-friendly platform that simplifies the process of creating precise and detailed annotations, and it’s suitable for a wide range of applications. With its versatile annotation capabilities, Annotab Studio ensures that your semi-supervised learning models are trained on well-defined and accurate data. Choosing Annotab Studio means equipping your models with the best possible data foundation for superior performance and accuracy.
Challenges and Solutions in Semi-Supervised Learning
Semi-supervised learning faces several common challenges that can impact the effectiveness of the models. One challenge is ensuring data quality. Annotab’s image annotation tool is designed to help overcome this challenge. It offers a range of annotation types to suit different data requirements, ensuring that the labeled dataset is as informative and representative as possible.
Another challenge is model complexity. Semi-supervised learning models often need to understand and learn from complex data structures. This can be difficult, especially when the labeled data is sparse or incomplete. One solution to this is to improve the algorithm's ability to extract meaningful patterns from limited labeled data. This involves improving the model's architecture or using advanced techniques like feature extraction and dimensionality reduction to help the model better interpret and learn from the data. Additionally, more robust and adaptive learning algorithms can enable semi-supervised learning models to understand and make sense of complex data patterns more effectively.
Challenges and Solutions in Semi-Supervised Learning
Semi-supervised learning faces several common challenges that can impact the effectiveness of the models. One challenge is ensuring data quality. Annotab’s image annotation tool is designed to help overcome this challenge. It offers a range of annotation types to suit different data requirements, ensuring that the labeled dataset is as informative and representative as possible.
Another challenge is model complexity. Semi-supervised learning models often need to understand and learn from complex data structures. This can be difficult, especially when the labeled data is sparse or incomplete. One solution to this is to improve the algorithm's ability to extract meaningful patterns from limited labeled data. This involves improving the model's architecture or using advanced techniques like feature extraction and dimensionality reduction to help the model better interpret and learn from the data. Additionally, more robust and adaptive learning algorithms can enable semi-supervised learning models to understand and make sense of complex data patterns more effectively.
Challenges and Solutions in Semi-Supervised Learning
Semi-supervised learning faces several common challenges that can impact the effectiveness of the models. One challenge is ensuring data quality. Annotab’s image annotation tool is designed to help overcome this challenge. It offers a range of annotation types to suit different data requirements, ensuring that the labeled dataset is as informative and representative as possible.
Another challenge is model complexity. Semi-supervised learning models often need to understand and learn from complex data structures. This can be difficult, especially when the labeled data is sparse or incomplete. One solution to this is to improve the algorithm's ability to extract meaningful patterns from limited labeled data. This involves improving the model's architecture or using advanced techniques like feature extraction and dimensionality reduction to help the model better interpret and learn from the data. Additionally, more robust and adaptive learning algorithms can enable semi-supervised learning models to understand and make sense of complex data patterns more effectively.
Challenges and Solutions in Semi-Supervised Learning
Semi-supervised learning faces several common challenges that can impact the effectiveness of the models. One challenge is ensuring data quality. Annotab’s image annotation tool is designed to help overcome this challenge. It offers a range of annotation types to suit different data requirements, ensuring that the labeled dataset is as informative and representative as possible.
Another challenge is model complexity. Semi-supervised learning models often need to understand and learn from complex data structures. This can be difficult, especially when the labeled data is sparse or incomplete. One solution to this is to improve the algorithm's ability to extract meaningful patterns from limited labeled data. This involves improving the model's architecture or using advanced techniques like feature extraction and dimensionality reduction to help the model better interpret and learn from the data. Additionally, more robust and adaptive learning algorithms can enable semi-supervised learning models to understand and make sense of complex data patterns more effectively.
Best Practices in Semi-Supervised Learning
Other than using high-quality, well-labeled data, there are several other good practices to follow when working with semi-supervised learning to ensure your efforts create a fruitful model.
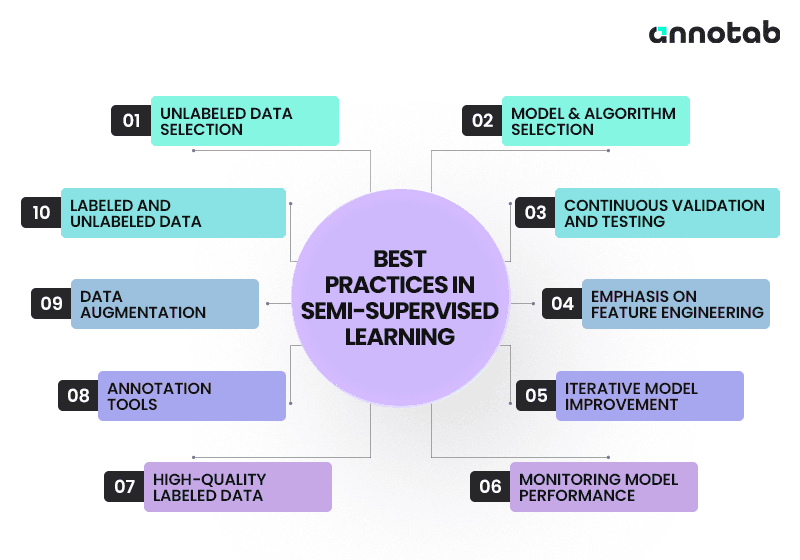
A mind map of the best practices of semi-supervised learning.
Unlabeled Data Selection
Choosing the right unlabeled data can make all the difference in semi-supervised learning. This data should be varied and include different aspects of the problem domain. The more diverse and relevant the unlabeled data, the better the semi-supervised learning model can learn and generalize. It's important to ensure that this data, like the labeled data, is high quality and aligns well with the real-world scenarios the model is expected to handle.
Data Augmentation
Data augmentation can be a powerful technique in semi-supervised learning to increase the diversity of the training set. This can involve modifying existing data or generating synthetic data to provide the model with a broader range of examples. Techniques like rotating, scaling, or altering the color balance of images, or using techniques like SMOTE for tabular data, can increase the robustness of semi-supervised learning models.
Model and Algorithm Selection
Selecting the appropriate model and algorithm is key to the success of a semi-supervised learning project. The choice should align with the data's nature and the application's specific challenges. Some models may be better than others at handling high-dimensional data or complex feature interactions, while others might be more suitable for simpler, structured data.
Continuous Validation and Testing
Continuous validation and testing are key to maintaining the accuracy and reliability of semi-supervised learning models. Regularly testing the model with diverse data sets helps to identify any biases or errors early. It also ensures that the model generalizes well and is effective across different data scenarios.
Emphasis on Feature Engineering
In semi-supervised learning, feature engineering is crucial in boosting model performance. Identifying the most relevant features and transforming them in ways that make them more informative for the model can lead to substantial improvements. This process requires domain knowledge and an understanding about how different features impact the model's predictions.
Iterative Model Improvement
Semi-supervised learning is an iterative process where models are continuously refined based on feedback and performance metrics. This might involve adjusting the model architecture, tuning hyper-parameters, or updating the training data. Iterative improvement helps adapt the model to changing conditions and improve its accuracy over time.
Monitoring Model Performance
Monitoring the performance of semi-supervised learning models can help ensure that they adapt effectively to new data and maintain high performance. Regular monitoring can reveal shifts in data patterns or emerging trends. You can make adjustments to the model before it becomes an issue and make proactive decisions. This practice is a must for applications where models are deployed in dynamic environments.
Balancing Labeled and Unlabeled Data
One of the most important practices in semi-supervised learning is achieving the right balance between labeled and unlabeled data. If there is too little labeled data, the model might not get enough information to learn effectively. On the other hand, if there is too much labeled data, the model might not use the unlabeled data as much as it should. Finding the right mix of labeled and unlabeled data is essential. This balance helps the model use both types of data well. This leads to better learning and the ability of the model to apply what it has learned to new situations. This balance is often domain-specific and may require some experimentation to optimize for different semi-supervised learning applications.
Best Practices in Semi-Supervised Learning
Other than using high-quality, well-labeled data, there are several other good practices to follow when working with semi-supervised learning to ensure your efforts create a fruitful model.
A mind map of the best practices of semi-supervised learning.
Unlabeled Data Selection
Choosing the right unlabeled data can make all the difference in semi-supervised learning. This data should be varied and include different aspects of the problem domain. The more diverse and relevant the unlabeled data, the better the semi-supervised learning model can learn and generalize. It's important to ensure that this data, like the labeled data, is high quality and aligns well with the real-world scenarios the model is expected to handle.
Data Augmentation
Data augmentation can be a powerful technique in semi-supervised learning to increase the diversity of the training set. This can involve modifying existing data or generating synthetic data to provide the model with a broader range of examples. Techniques like rotating, scaling, or altering the color balance of images, or using techniques like SMOTE for tabular data, can increase the robustness of semi-supervised learning models.
Model and Algorithm Selection
Selecting the appropriate model and algorithm is key to the success of a semi-supervised learning project. The choice should align with the data's nature and the application's specific challenges. Some models may be better than others at handling high-dimensional data or complex feature interactions, while others might be more suitable for simpler, structured data.
Continuous Validation and Testing
Continuous validation and testing are key to maintaining the accuracy and reliability of semi-supervised learning models. Regularly testing the model with diverse data sets helps to identify any biases or errors early. It also ensures that the model generalizes well and is effective across different data scenarios.
Emphasis on Feature Engineering
In semi-supervised learning, feature engineering is crucial in boosting model performance. Identifying the most relevant features and transforming them in ways that make them more informative for the model can lead to substantial improvements. This process requires domain knowledge and an understanding about how different features impact the model's predictions.
Iterative Model Improvement
Semi-supervised learning is an iterative process where models are continuously refined based on feedback and performance metrics. This might involve adjusting the model architecture, tuning hyper-parameters, or updating the training data. Iterative improvement helps adapt the model to changing conditions and improve its accuracy over time.
Monitoring Model Performance
Monitoring the performance of semi-supervised learning models can help ensure that they adapt effectively to new data and maintain high performance. Regular monitoring can reveal shifts in data patterns or emerging trends. You can make adjustments to the model before it becomes an issue and make proactive decisions. This practice is a must for applications where models are deployed in dynamic environments.
Balancing Labeled and Unlabeled Data
One of the most important practices in semi-supervised learning is achieving the right balance between labeled and unlabeled data. If there is too little labeled data, the model might not get enough information to learn effectively. On the other hand, if there is too much labeled data, the model might not use the unlabeled data as much as it should. Finding the right mix of labeled and unlabeled data is essential. This balance helps the model use both types of data well. This leads to better learning and the ability of the model to apply what it has learned to new situations. This balance is often domain-specific and may require some experimentation to optimize for different semi-supervised learning applications.
Best Practices in Semi-Supervised Learning
Other than using high-quality, well-labeled data, there are several other good practices to follow when working with semi-supervised learning to ensure your efforts create a fruitful model.
A mind map of the best practices of semi-supervised learning.
Unlabeled Data Selection
Choosing the right unlabeled data can make all the difference in semi-supervised learning. This data should be varied and include different aspects of the problem domain. The more diverse and relevant the unlabeled data, the better the semi-supervised learning model can learn and generalize. It's important to ensure that this data, like the labeled data, is high quality and aligns well with the real-world scenarios the model is expected to handle.
Data Augmentation
Data augmentation can be a powerful technique in semi-supervised learning to increase the diversity of the training set. This can involve modifying existing data or generating synthetic data to provide the model with a broader range of examples. Techniques like rotating, scaling, or altering the color balance of images, or using techniques like SMOTE for tabular data, can increase the robustness of semi-supervised learning models.
Model and Algorithm Selection
Selecting the appropriate model and algorithm is key to the success of a semi-supervised learning project. The choice should align with the data's nature and the application's specific challenges. Some models may be better than others at handling high-dimensional data or complex feature interactions, while others might be more suitable for simpler, structured data.
Continuous Validation and Testing
Continuous validation and testing are key to maintaining the accuracy and reliability of semi-supervised learning models. Regularly testing the model with diverse data sets helps to identify any biases or errors early. It also ensures that the model generalizes well and is effective across different data scenarios.
Emphasis on Feature Engineering
In semi-supervised learning, feature engineering is crucial in boosting model performance. Identifying the most relevant features and transforming them in ways that make them more informative for the model can lead to substantial improvements. This process requires domain knowledge and an understanding about how different features impact the model's predictions.
Iterative Model Improvement
Semi-supervised learning is an iterative process where models are continuously refined based on feedback and performance metrics. This might involve adjusting the model architecture, tuning hyper-parameters, or updating the training data. Iterative improvement helps adapt the model to changing conditions and improve its accuracy over time.
Monitoring Model Performance
Monitoring the performance of semi-supervised learning models can help ensure that they adapt effectively to new data and maintain high performance. Regular monitoring can reveal shifts in data patterns or emerging trends. You can make adjustments to the model before it becomes an issue and make proactive decisions. This practice is a must for applications where models are deployed in dynamic environments.
Balancing Labeled and Unlabeled Data
One of the most important practices in semi-supervised learning is achieving the right balance between labeled and unlabeled data. If there is too little labeled data, the model might not get enough information to learn effectively. On the other hand, if there is too much labeled data, the model might not use the unlabeled data as much as it should. Finding the right mix of labeled and unlabeled data is essential. This balance helps the model use both types of data well. This leads to better learning and the ability of the model to apply what it has learned to new situations. This balance is often domain-specific and may require some experimentation to optimize for different semi-supervised learning applications.
Best Practices in Semi-Supervised Learning
Other than using high-quality, well-labeled data, there are several other good practices to follow when working with semi-supervised learning to ensure your efforts create a fruitful model.
A mind map of the best practices of semi-supervised learning.
Unlabeled Data Selection
Choosing the right unlabeled data can make all the difference in semi-supervised learning. This data should be varied and include different aspects of the problem domain. The more diverse and relevant the unlabeled data, the better the semi-supervised learning model can learn and generalize. It's important to ensure that this data, like the labeled data, is high quality and aligns well with the real-world scenarios the model is expected to handle.
Data Augmentation
Data augmentation can be a powerful technique in semi-supervised learning to increase the diversity of the training set. This can involve modifying existing data or generating synthetic data to provide the model with a broader range of examples. Techniques like rotating, scaling, or altering the color balance of images, or using techniques like SMOTE for tabular data, can increase the robustness of semi-supervised learning models.
Model and Algorithm Selection
Selecting the appropriate model and algorithm is key to the success of a semi-supervised learning project. The choice should align with the data's nature and the application's specific challenges. Some models may be better than others at handling high-dimensional data or complex feature interactions, while others might be more suitable for simpler, structured data.
Continuous Validation and Testing
Continuous validation and testing are key to maintaining the accuracy and reliability of semi-supervised learning models. Regularly testing the model with diverse data sets helps to identify any biases or errors early. It also ensures that the model generalizes well and is effective across different data scenarios.
Emphasis on Feature Engineering
In semi-supervised learning, feature engineering is crucial in boosting model performance. Identifying the most relevant features and transforming them in ways that make them more informative for the model can lead to substantial improvements. This process requires domain knowledge and an understanding about how different features impact the model's predictions.
Iterative Model Improvement
Semi-supervised learning is an iterative process where models are continuously refined based on feedback and performance metrics. This might involve adjusting the model architecture, tuning hyper-parameters, or updating the training data. Iterative improvement helps adapt the model to changing conditions and improve its accuracy over time.
Monitoring Model Performance
Monitoring the performance of semi-supervised learning models can help ensure that they adapt effectively to new data and maintain high performance. Regular monitoring can reveal shifts in data patterns or emerging trends. You can make adjustments to the model before it becomes an issue and make proactive decisions. This practice is a must for applications where models are deployed in dynamic environments.
Balancing Labeled and Unlabeled Data
One of the most important practices in semi-supervised learning is achieving the right balance between labeled and unlabeled data. If there is too little labeled data, the model might not get enough information to learn effectively. On the other hand, if there is too much labeled data, the model might not use the unlabeled data as much as it should. Finding the right mix of labeled and unlabeled data is essential. This balance helps the model use both types of data well. This leads to better learning and the ability of the model to apply what it has learned to new situations. This balance is often domain-specific and may require some experimentation to optimize for different semi-supervised learning applications.
The Future of Semi-Supervised Learning
Semi-supervised learning is shaping up to be an important area in artificial intelligence. Semi-supervised learning is expected to become more sophisticated, and we can expect advancements that allow for improved accuracy and efficiency. This growth will likely influence a wide range of fields, including healthcare, language processing, and autonomous technology. Integrating semi-supervised learning with other machine learning techniques could lead to more powerful and versatile AI systems. As we continue to generate vast amounts of unlabeled data, semi-supervised learning offers a promising method for harnessing this data more effectively.
Emerging Trends in Semi-Supervised Learning
There are a few emerging trends in semi-supervised learning that have great potential for new discoveries in machine learning. One of these trends is the integration of multi-modal learning within semi-supervised learning. This innovative approach involves training models to understand and process various data types like text, vision, speech, and IoT sensor data, all within a single machine-learning framework. An example of this trend is Google DeepMind's Gato. Gato is a multimodal AI system that performs diverse tasks across domains such as visual recognition, language processing, and robotic movements.
Another exciting emerging trend is using semi-supervised learning for automated machine learning, AutoML, to reduce the human efforts required in the labeling industry. AutoML) makes the process of building and deploying machine learning models easier. It automates the time-consuming tasks of selecting the right algorithms and tuning their hyperparameters. AutoML scans through various algorithms, evaluates their performance on a specific dataset, and selects the best-performing model. This speeds up the model development process and makes machine learning more accessible to non-experts. It democratizes the ability to create effective machine-learning models without requiring deep field knowledge. AutoML is particularly useful when rapid model development and deployment are needed or specialized machine learning expertise is limited.
These emerging trends in semi-supervised learning point towards a future where machine learning models are more accurate, flexible, and capable of handling a broader range of tasks across different data types. As research and development in this area continue to progress, we can expect semi-supervised learning to play a role in reshaping the next generation of AI technologies.
The Future of Semi-Supervised Learning
Semi-supervised learning is shaping up to be an important area in artificial intelligence. Semi-supervised learning is expected to become more sophisticated, and we can expect advancements that allow for improved accuracy and efficiency. This growth will likely influence a wide range of fields, including healthcare, language processing, and autonomous technology. Integrating semi-supervised learning with other machine learning techniques could lead to more powerful and versatile AI systems. As we continue to generate vast amounts of unlabeled data, semi-supervised learning offers a promising method for harnessing this data more effectively.
Emerging Trends in Semi-Supervised Learning
There are a few emerging trends in semi-supervised learning that have great potential for new discoveries in machine learning. One of these trends is the integration of multi-modal learning within semi-supervised learning. This innovative approach involves training models to understand and process various data types like text, vision, speech, and IoT sensor data, all within a single machine-learning framework. An example of this trend is Google DeepMind's Gato. Gato is a multimodal AI system that performs diverse tasks across domains such as visual recognition, language processing, and robotic movements.
Another exciting emerging trend is using semi-supervised learning for automated machine learning, AutoML, to reduce the human efforts required in the labeling industry. AutoML) makes the process of building and deploying machine learning models easier. It automates the time-consuming tasks of selecting the right algorithms and tuning their hyperparameters. AutoML scans through various algorithms, evaluates their performance on a specific dataset, and selects the best-performing model. This speeds up the model development process and makes machine learning more accessible to non-experts. It democratizes the ability to create effective machine-learning models without requiring deep field knowledge. AutoML is particularly useful when rapid model development and deployment are needed or specialized machine learning expertise is limited.
These emerging trends in semi-supervised learning point towards a future where machine learning models are more accurate, flexible, and capable of handling a broader range of tasks across different data types. As research and development in this area continue to progress, we can expect semi-supervised learning to play a role in reshaping the next generation of AI technologies.
The Future of Semi-Supervised Learning
Semi-supervised learning is shaping up to be an important area in artificial intelligence. Semi-supervised learning is expected to become more sophisticated, and we can expect advancements that allow for improved accuracy and efficiency. This growth will likely influence a wide range of fields, including healthcare, language processing, and autonomous technology. Integrating semi-supervised learning with other machine learning techniques could lead to more powerful and versatile AI systems. As we continue to generate vast amounts of unlabeled data, semi-supervised learning offers a promising method for harnessing this data more effectively.
Emerging Trends in Semi-Supervised Learning
There are a few emerging trends in semi-supervised learning that have great potential for new discoveries in machine learning. One of these trends is the integration of multi-modal learning within semi-supervised learning. This innovative approach involves training models to understand and process various data types like text, vision, speech, and IoT sensor data, all within a single machine-learning framework. An example of this trend is Google DeepMind's Gato. Gato is a multimodal AI system that performs diverse tasks across domains such as visual recognition, language processing, and robotic movements.
Another exciting emerging trend is using semi-supervised learning for automated machine learning, AutoML, to reduce the human efforts required in the labeling industry. AutoML) makes the process of building and deploying machine learning models easier. It automates the time-consuming tasks of selecting the right algorithms and tuning their hyperparameters. AutoML scans through various algorithms, evaluates their performance on a specific dataset, and selects the best-performing model. This speeds up the model development process and makes machine learning more accessible to non-experts. It democratizes the ability to create effective machine-learning models without requiring deep field knowledge. AutoML is particularly useful when rapid model development and deployment are needed or specialized machine learning expertise is limited.
These emerging trends in semi-supervised learning point towards a future where machine learning models are more accurate, flexible, and capable of handling a broader range of tasks across different data types. As research and development in this area continue to progress, we can expect semi-supervised learning to play a role in reshaping the next generation of AI technologies.
The Future of Semi-Supervised Learning
Semi-supervised learning is shaping up to be an important area in artificial intelligence. Semi-supervised learning is expected to become more sophisticated, and we can expect advancements that allow for improved accuracy and efficiency. This growth will likely influence a wide range of fields, including healthcare, language processing, and autonomous technology. Integrating semi-supervised learning with other machine learning techniques could lead to more powerful and versatile AI systems. As we continue to generate vast amounts of unlabeled data, semi-supervised learning offers a promising method for harnessing this data more effectively.
Emerging Trends in Semi-Supervised Learning
There are a few emerging trends in semi-supervised learning that have great potential for new discoveries in machine learning. One of these trends is the integration of multi-modal learning within semi-supervised learning. This innovative approach involves training models to understand and process various data types like text, vision, speech, and IoT sensor data, all within a single machine-learning framework. An example of this trend is Google DeepMind's Gato. Gato is a multimodal AI system that performs diverse tasks across domains such as visual recognition, language processing, and robotic movements.
Another exciting emerging trend is using semi-supervised learning for automated machine learning, AutoML, to reduce the human efforts required in the labeling industry. AutoML) makes the process of building and deploying machine learning models easier. It automates the time-consuming tasks of selecting the right algorithms and tuning their hyperparameters. AutoML scans through various algorithms, evaluates their performance on a specific dataset, and selects the best-performing model. This speeds up the model development process and makes machine learning more accessible to non-experts. It democratizes the ability to create effective machine-learning models without requiring deep field knowledge. AutoML is particularly useful when rapid model development and deployment are needed or specialized machine learning expertise is limited.
These emerging trends in semi-supervised learning point towards a future where machine learning models are more accurate, flexible, and capable of handling a broader range of tasks across different data types. As research and development in this area continue to progress, we can expect semi-supervised learning to play a role in reshaping the next generation of AI technologies.
Conclusion
Semi-supervised learning is a machine learning technique that combines labeled and unlabeled data. It's recognized for its efficiency, particularly where labeled data is scarce. Techniques like pseudo-labeling and consistency regularization have proven effective in semi-supervised learning. The success of semi-supervised learning heavily relies on the quality of data. High-quality image annotation is crucial, and providing precise, well-defined data that guides the learning process is important.
Semi-supervised learning's real-world applications are diverse. Amazon uses it to improve Alexa's responses, Netflix to detect fraud in streaming services, and Google to enhance its search engine's language understanding through Semi-Supervised Distillation (SSD). The future of semi-supervised learning is heading towards more advanced innovations. Key trends like multi-modal learning are emerging. As a result, semi-supervised learning is becoming an increasingly important and exciting area with many opportunities for growth and application.
Semi-supervised learning is a versatile and powerful tool that enables more accurate, flexible, and cost-effective models. For those looking to enhance their machine-learning capabilities, exploring tools like Annotab Studio for high-quality image annotation is a step toward harnessing the full potential of semi-supervised learning.
Conclusion
Semi-supervised learning is a machine learning technique that combines labeled and unlabeled data. It's recognized for its efficiency, particularly where labeled data is scarce. Techniques like pseudo-labeling and consistency regularization have proven effective in semi-supervised learning. The success of semi-supervised learning heavily relies on the quality of data. High-quality image annotation is crucial, and providing precise, well-defined data that guides the learning process is important.
Semi-supervised learning's real-world applications are diverse. Amazon uses it to improve Alexa's responses, Netflix to detect fraud in streaming services, and Google to enhance its search engine's language understanding through Semi-Supervised Distillation (SSD). The future of semi-supervised learning is heading towards more advanced innovations. Key trends like multi-modal learning are emerging. As a result, semi-supervised learning is becoming an increasingly important and exciting area with many opportunities for growth and application.
Semi-supervised learning is a versatile and powerful tool that enables more accurate, flexible, and cost-effective models. For those looking to enhance their machine-learning capabilities, exploring tools like Annotab Studio for high-quality image annotation is a step toward harnessing the full potential of semi-supervised learning.
Conclusion
Semi-supervised learning is a machine learning technique that combines labeled and unlabeled data. It's recognized for its efficiency, particularly where labeled data is scarce. Techniques like pseudo-labeling and consistency regularization have proven effective in semi-supervised learning. The success of semi-supervised learning heavily relies on the quality of data. High-quality image annotation is crucial, and providing precise, well-defined data that guides the learning process is important.
Semi-supervised learning's real-world applications are diverse. Amazon uses it to improve Alexa's responses, Netflix to detect fraud in streaming services, and Google to enhance its search engine's language understanding through Semi-Supervised Distillation (SSD). The future of semi-supervised learning is heading towards more advanced innovations. Key trends like multi-modal learning are emerging. As a result, semi-supervised learning is becoming an increasingly important and exciting area with many opportunities for growth and application.
Semi-supervised learning is a versatile and powerful tool that enables more accurate, flexible, and cost-effective models. For those looking to enhance their machine-learning capabilities, exploring tools like Annotab Studio for high-quality image annotation is a step toward harnessing the full potential of semi-supervised learning.
Conclusion
Semi-supervised learning is a machine learning technique that combines labeled and unlabeled data. It's recognized for its efficiency, particularly where labeled data is scarce. Techniques like pseudo-labeling and consistency regularization have proven effective in semi-supervised learning. The success of semi-supervised learning heavily relies on the quality of data. High-quality image annotation is crucial, and providing precise, well-defined data that guides the learning process is important.
Semi-supervised learning's real-world applications are diverse. Amazon uses it to improve Alexa's responses, Netflix to detect fraud in streaming services, and Google to enhance its search engine's language understanding through Semi-Supervised Distillation (SSD). The future of semi-supervised learning is heading towards more advanced innovations. Key trends like multi-modal learning are emerging. As a result, semi-supervised learning is becoming an increasingly important and exciting area with many opportunities for growth and application.
Semi-supervised learning is a versatile and powerful tool that enables more accurate, flexible, and cost-effective models. For those looking to enhance their machine-learning capabilities, exploring tools like Annotab Studio for high-quality image annotation is a step toward harnessing the full potential of semi-supervised learning.
Abirami Vina
Technical Writer
Abirami Vina is a technical content writer and AI engineer. The appeal of AI, especially computer vision, grabbed her attention, and she decided to intertwine it with her love of writing. She often likes to say that she writes because it's the next best thing to Dumbledore's Pensieve, a magical way to sort through thoughts and ideas.
Abirami Vina
Technical Writer
Abirami Vina is a technical content writer and AI engineer. The appeal of AI, especially computer vision, grabbed her attention, and she decided to intertwine it with her love of writing. She often likes to say that she writes because it's the next best thing to Dumbledore's Pensieve, a magical way to sort through thoughts and ideas.
Abirami Vina
Technical Writer
Abirami Vina is a technical content writer and AI engineer. The appeal of AI, especially computer vision, grabbed her attention, and she decided to intertwine it with her love of writing. She often likes to say that she writes because it's the next best thing to Dumbledore's Pensieve, a magical way to sort through thoughts and ideas.
Abirami Vina
Technical Writer
Abirami Vina is a technical content writer and AI engineer. The appeal of AI, especially computer vision, grabbed her attention, and she decided to intertwine it with her love of writing. She often likes to say that she writes because it's the next best thing to Dumbledore's Pensieve, a magical way to sort through thoughts and ideas.