Annotab Studio 2.0.0 is now live
Retrieval Augmented Generation
Retrieval Augmented Generation
Retrieval Augmented Generation
Retrieval Augmented Generation
Published by

Osama Akhlaq
on
Jan 15, 2024
under
Machine Learning
Published by
Osama Akhlaq
on
Jan 15, 2024
under
Machine Learning
Published by
Osama Akhlaq
on
Jan 15, 2024
under
Machine Learning
Published by
Osama Akhlaq
on
Jan 15, 2024
under
Machine Learning
ON THIS PAGE
Tl;dr
Recent advancements have illustrated that large pre-trained language models effectively encapsulate information within their parameters, achieving leading-edge performance in various NLP tasks through fine-tuning. Despite these advancements, their proficiency in handling knowledge-intensive charges remains somewhat constrained, trailing behind architectures designed for such tasks. To address these limitations, there should be pre-trained models that employ a different mechanism to access an explicit and non-parametric memory source, a method primarily explored in extractive tasks up until now. This article revolves around the emerging field of Retrieval-Augmented Generation (RAG), an innovative approach in natural language processing that integrates traditional language models with real-time information retrieval.
Tl;dr
Recent advancements have illustrated that large pre-trained language models effectively encapsulate information within their parameters, achieving leading-edge performance in various NLP tasks through fine-tuning. Despite these advancements, their proficiency in handling knowledge-intensive charges remains somewhat constrained, trailing behind architectures designed for such tasks. To address these limitations, there should be pre-trained models that employ a different mechanism to access an explicit and non-parametric memory source, a method primarily explored in extractive tasks up until now. This article revolves around the emerging field of Retrieval-Augmented Generation (RAG), an innovative approach in natural language processing that integrates traditional language models with real-time information retrieval.
Tl;dr
Recent advancements have illustrated that large pre-trained language models effectively encapsulate information within their parameters, achieving leading-edge performance in various NLP tasks through fine-tuning. Despite these advancements, their proficiency in handling knowledge-intensive charges remains somewhat constrained, trailing behind architectures designed for such tasks. To address these limitations, there should be pre-trained models that employ a different mechanism to access an explicit and non-parametric memory source, a method primarily explored in extractive tasks up until now. This article revolves around the emerging field of Retrieval-Augmented Generation (RAG), an innovative approach in natural language processing that integrates traditional language models with real-time information retrieval.
Tl;dr
Recent advancements have illustrated that large pre-trained language models effectively encapsulate information within their parameters, achieving leading-edge performance in various NLP tasks through fine-tuning. Despite these advancements, their proficiency in handling knowledge-intensive charges remains somewhat constrained, trailing behind architectures designed for such tasks. To address these limitations, there should be pre-trained models that employ a different mechanism to access an explicit and non-parametric memory source, a method primarily explored in extractive tasks up until now. This article revolves around the emerging field of Retrieval-Augmented Generation (RAG), an innovative approach in natural language processing that integrates traditional language models with real-time information retrieval.

Introduction
Natural Language Processing (NLP) has witnessed a significant change with the arrival of sophisticated language models like BERT (Bidirectional Encoder Representations from Transformers). These models, trained on extensive collections of textual data, have revolutionized our approach to understanding and generating human language. With its deep knowledge of language context, BERT has set new standards in a range of NLP applications. However, despite these remarkable advancements, these models encounter significant challenges, particularly in tasks that demand extensive, specific knowledge.
One noteworthy issue with these advanced language models is their inherent limitation in accessing and precisely applying the wealth of information they theoretically hold. Although they have significantly advanced the capabilities of NLP systems, they often need to catch up against specialized architectures in handling tasks that require deep, specific knowledge. This limitation is rooted in their computational design and the fundamental approach to language processing and generation inherent in these models. Moreover, the models face challenges in providing clear explanations for their outputs and updating their knowledge base in an ever-changing world. This is a critical aspect, as it touches upon the reliability and trustworthiness of AI systems. Traditional parametric models like BERT are constrained by their training data, which can quickly become outdated, limiting their real-world applicability.
In response to these limitations, there is an increasing focus on models that blend the robustness of pre-trained parametric models with dynamic, external, non-parametric memory sources. This approach is gaining traction as it offers a blend of stability and adaptability, leveraging the strengths of both parametric and non-parametric systems. Although initially explored in the context of extractive tasks, this methodology is now being extended to broader NLP applications.
This article explores the exciting world of Retrieval-Augmented Generation (RAG) models, a groundbreaking technique that blends well-trained parametric memory, like that found in models such as BERT, with a non-parametric memory element. This non-parametric part is characterized by a detailed vector index of Wikipedia, accessed using an advanced neural retrieval system.
Introduction
Natural Language Processing (NLP) has witnessed a significant change with the arrival of sophisticated language models like BERT (Bidirectional Encoder Representations from Transformers). These models, trained on extensive collections of textual data, have revolutionized our approach to understanding and generating human language. With its deep knowledge of language context, BERT has set new standards in a range of NLP applications. However, despite these remarkable advancements, these models encounter significant challenges, particularly in tasks that demand extensive, specific knowledge.
One noteworthy issue with these advanced language models is their inherent limitation in accessing and precisely applying the wealth of information they theoretically hold. Although they have significantly advanced the capabilities of NLP systems, they often need to catch up against specialized architectures in handling tasks that require deep, specific knowledge. This limitation is rooted in their computational design and the fundamental approach to language processing and generation inherent in these models. Moreover, the models face challenges in providing clear explanations for their outputs and updating their knowledge base in an ever-changing world. This is a critical aspect, as it touches upon the reliability and trustworthiness of AI systems. Traditional parametric models like BERT are constrained by their training data, which can quickly become outdated, limiting their real-world applicability.
In response to these limitations, there is an increasing focus on models that blend the robustness of pre-trained parametric models with dynamic, external, non-parametric memory sources. This approach is gaining traction as it offers a blend of stability and adaptability, leveraging the strengths of both parametric and non-parametric systems. Although initially explored in the context of extractive tasks, this methodology is now being extended to broader NLP applications.
This article explores the exciting world of Retrieval-Augmented Generation (RAG) models, a groundbreaking technique that blends well-trained parametric memory, like that found in models such as BERT, with a non-parametric memory element. This non-parametric part is characterized by a detailed vector index of Wikipedia, accessed using an advanced neural retrieval system.
Introduction
Natural Language Processing (NLP) has witnessed a significant change with the arrival of sophisticated language models like BERT (Bidirectional Encoder Representations from Transformers). These models, trained on extensive collections of textual data, have revolutionized our approach to understanding and generating human language. With its deep knowledge of language context, BERT has set new standards in a range of NLP applications. However, despite these remarkable advancements, these models encounter significant challenges, particularly in tasks that demand extensive, specific knowledge.
One noteworthy issue with these advanced language models is their inherent limitation in accessing and precisely applying the wealth of information they theoretically hold. Although they have significantly advanced the capabilities of NLP systems, they often need to catch up against specialized architectures in handling tasks that require deep, specific knowledge. This limitation is rooted in their computational design and the fundamental approach to language processing and generation inherent in these models. Moreover, the models face challenges in providing clear explanations for their outputs and updating their knowledge base in an ever-changing world. This is a critical aspect, as it touches upon the reliability and trustworthiness of AI systems. Traditional parametric models like BERT are constrained by their training data, which can quickly become outdated, limiting their real-world applicability.
In response to these limitations, there is an increasing focus on models that blend the robustness of pre-trained parametric models with dynamic, external, non-parametric memory sources. This approach is gaining traction as it offers a blend of stability and adaptability, leveraging the strengths of both parametric and non-parametric systems. Although initially explored in the context of extractive tasks, this methodology is now being extended to broader NLP applications.
This article explores the exciting world of Retrieval-Augmented Generation (RAG) models, a groundbreaking technique that blends well-trained parametric memory, like that found in models such as BERT, with a non-parametric memory element. This non-parametric part is characterized by a detailed vector index of Wikipedia, accessed using an advanced neural retrieval system.
Introduction
Natural Language Processing (NLP) has witnessed a significant change with the arrival of sophisticated language models like BERT (Bidirectional Encoder Representations from Transformers). These models, trained on extensive collections of textual data, have revolutionized our approach to understanding and generating human language. With its deep knowledge of language context, BERT has set new standards in a range of NLP applications. However, despite these remarkable advancements, these models encounter significant challenges, particularly in tasks that demand extensive, specific knowledge.
One noteworthy issue with these advanced language models is their inherent limitation in accessing and precisely applying the wealth of information they theoretically hold. Although they have significantly advanced the capabilities of NLP systems, they often need to catch up against specialized architectures in handling tasks that require deep, specific knowledge. This limitation is rooted in their computational design and the fundamental approach to language processing and generation inherent in these models. Moreover, the models face challenges in providing clear explanations for their outputs and updating their knowledge base in an ever-changing world. This is a critical aspect, as it touches upon the reliability and trustworthiness of AI systems. Traditional parametric models like BERT are constrained by their training data, which can quickly become outdated, limiting their real-world applicability.
In response to these limitations, there is an increasing focus on models that blend the robustness of pre-trained parametric models with dynamic, external, non-parametric memory sources. This approach is gaining traction as it offers a blend of stability and adaptability, leveraging the strengths of both parametric and non-parametric systems. Although initially explored in the context of extractive tasks, this methodology is now being extended to broader NLP applications.
This article explores the exciting world of Retrieval-Augmented Generation (RAG) models, a groundbreaking technique that blends well-trained parametric memory, like that found in models such as BERT, with a non-parametric memory element. This non-parametric part is characterized by a detailed vector index of Wikipedia, accessed using an advanced neural retrieval system.
Retrieval-Augmented Generation: An Overview
Retrieval-augmented generation (RAG) represents a novel approach to natural language processing, merging the strengths of generative language models with external information retrieval systems. The essence of RAG lies in its ability to dynamically augment the language generation process with information retrieved in real-time from a vast external database, such as Wikipedia. This approach allows RAG models to produce contextually relevant responses rich in factual details and current information.
The RAG system essentially consists of two main components:
Generative language model
Information retrieval (IR) subsystem.
The generative model, similar to traditional language models, is responsible for the primary task of text generation. However, unlike conventional models that rely solely on their pre-trained knowledge, RAG models consult the IR component to fetch relevant external information during the generation process. This integration enables RAG models to generate responses beyond the scope of their initial training data.
Background
Evolution of NLP and Language Models:
The journey of Natural Language Processing (NLP) has been marked by continuous growth, from the early days of rule-based systems to the current era of machine learning and deep learning models. This change reflects the overall development of artificial intelligence. It has shifted from systems based on strict rules and small amounts of data to more advanced models that can learn from large datasets. Creating models such as LSTM (Long Short-Term Memory) and the Transformer architecture were necessary steps forward, making it possible for machines to understand and produce language more complexly.
The Rise of Transformer-based Models:
Introduced in 2017, the Transformer architecture transformed the field of natural language processing. It's known for effectively managing sequences of data and its streamlined training approach. This architecture is a critical component of models such as BERT and GPT, which are initially trained on large amounts of text and further refined for specific uses. BERT stands out for its unique bidirectional training, which provides a more thorough grasp of a language’s context and subtle aspects.
Challenges with Traditional Models:
Despite their impressive capabilities, these models have inherent limitations, especially when it comes to tasks that require extensive, specific knowledge. In functions that require a lot of knowledge, these models often fall short compared to more specialized structures. Also, since these models are parametric, they are confined to the information they were trained with and need help to adapt to new data after their training. This limitation becomes a challenge in environments that are constantly changing.
Information Retrieval in Computing:
Information retrieval has been a critical component in computing, dealing with the organization, storage, retrieval, and evaluation of information. Traditional information retrieval systems have been integral in various applications, from search engines to recommendation systems. However, their integration into NLP models for enhancing language understanding and generation is relatively recent.
Need for Advanced Integration:
The difficulty that traditional language models face in dealing with fast-changing, knowledge-heavy tasks has sparked interest in models that combine the strength of pre-trained language models with the flexibility of external, non-parametric memory. This combination is crucial for addressing the issues with fixed knowledge bases and the models' lack of real-time learning and adaptation.
How RAG Models Differ from Traditional Language Models
Traditional language models, such as BERT or GPT, generate text based on patterns and information learned during their training phase. Their knowledge is static and limited to the dataset they were trained on. As a result, while they excel in understanding and generating language based on learned contexts, their ability to provide up-to-date information or details not covered in their training could be improved.
In contrast, RAG models introduce an element of dynamism and adaptability. By leveraging an IR system, they can access a broader and more current knowledge base, which is not confined to their training data. This capability benefits tasks requiring detailed, specific, and current information.
The Architecture and Workflow of RAG Models
The architecture of a RAG model integrates the neural network-based language model with a separate retrieval component. The retrieval component is typically a dense vector space where documents or information snippets are stored as vectors. When the RAG model generates text, it queries this vector space based on the input context or the partially caused response. The retrieval system then returns the most relevant documents or information snippets, which the language model uses to inform the next part of its text generation.
This process involves a seamless interaction between the generative model and the retrieval system. As the model generates text, it may repeatedly query the retrieval system to refine or expand upon the information it generates. This iterative process continues until the generation task is complete, ensuring the output is contextually coherent and enriched with the most relevant and current information from the external data source.

Figure 1- Architecture of RAG
Retrieval-Augmented Generation: An Overview
Retrieval-augmented generation (RAG) represents a novel approach to natural language processing, merging the strengths of generative language models with external information retrieval systems. The essence of RAG lies in its ability to dynamically augment the language generation process with information retrieved in real-time from a vast external database, such as Wikipedia. This approach allows RAG models to produce contextually relevant responses rich in factual details and current information.
The RAG system essentially consists of two main components:
Generative language model
Information retrieval (IR) subsystem.
The generative model, similar to traditional language models, is responsible for the primary task of text generation. However, unlike conventional models that rely solely on their pre-trained knowledge, RAG models consult the IR component to fetch relevant external information during the generation process. This integration enables RAG models to generate responses beyond the scope of their initial training data.
Background
Evolution of NLP and Language Models:
The journey of Natural Language Processing (NLP) has been marked by continuous growth, from the early days of rule-based systems to the current era of machine learning and deep learning models. This change reflects the overall development of artificial intelligence. It has shifted from systems based on strict rules and small amounts of data to more advanced models that can learn from large datasets. Creating models such as LSTM (Long Short-Term Memory) and the Transformer architecture were necessary steps forward, making it possible for machines to understand and produce language more complexly.
The Rise of Transformer-based Models:
Introduced in 2017, the Transformer architecture transformed the field of natural language processing. It's known for effectively managing sequences of data and its streamlined training approach. This architecture is a critical component of models such as BERT and GPT, which are initially trained on large amounts of text and further refined for specific uses. BERT stands out for its unique bidirectional training, which provides a more thorough grasp of a language’s context and subtle aspects.
Challenges with Traditional Models:
Despite their impressive capabilities, these models have inherent limitations, especially when it comes to tasks that require extensive, specific knowledge. In functions that require a lot of knowledge, these models often fall short compared to more specialized structures. Also, since these models are parametric, they are confined to the information they were trained with and need help to adapt to new data after their training. This limitation becomes a challenge in environments that are constantly changing.
Information Retrieval in Computing:
Information retrieval has been a critical component in computing, dealing with the organization, storage, retrieval, and evaluation of information. Traditional information retrieval systems have been integral in various applications, from search engines to recommendation systems. However, their integration into NLP models for enhancing language understanding and generation is relatively recent.
Need for Advanced Integration:
The difficulty that traditional language models face in dealing with fast-changing, knowledge-heavy tasks has sparked interest in models that combine the strength of pre-trained language models with the flexibility of external, non-parametric memory. This combination is crucial for addressing the issues with fixed knowledge bases and the models' lack of real-time learning and adaptation.
How RAG Models Differ from Traditional Language Models
Traditional language models, such as BERT or GPT, generate text based on patterns and information learned during their training phase. Their knowledge is static and limited to the dataset they were trained on. As a result, while they excel in understanding and generating language based on learned contexts, their ability to provide up-to-date information or details not covered in their training could be improved.
In contrast, RAG models introduce an element of dynamism and adaptability. By leveraging an IR system, they can access a broader and more current knowledge base, which is not confined to their training data. This capability benefits tasks requiring detailed, specific, and current information.
The Architecture and Workflow of RAG Models
The architecture of a RAG model integrates the neural network-based language model with a separate retrieval component. The retrieval component is typically a dense vector space where documents or information snippets are stored as vectors. When the RAG model generates text, it queries this vector space based on the input context or the partially caused response. The retrieval system then returns the most relevant documents or information snippets, which the language model uses to inform the next part of its text generation.
This process involves a seamless interaction between the generative model and the retrieval system. As the model generates text, it may repeatedly query the retrieval system to refine or expand upon the information it generates. This iterative process continues until the generation task is complete, ensuring the output is contextually coherent and enriched with the most relevant and current information from the external data source.
Figure 1- Architecture of RAG
Retrieval-Augmented Generation: An Overview
Retrieval-augmented generation (RAG) represents a novel approach to natural language processing, merging the strengths of generative language models with external information retrieval systems. The essence of RAG lies in its ability to dynamically augment the language generation process with information retrieved in real-time from a vast external database, such as Wikipedia. This approach allows RAG models to produce contextually relevant responses rich in factual details and current information.
The RAG system essentially consists of two main components:
Generative language model
Information retrieval (IR) subsystem.
The generative model, similar to traditional language models, is responsible for the primary task of text generation. However, unlike conventional models that rely solely on their pre-trained knowledge, RAG models consult the IR component to fetch relevant external information during the generation process. This integration enables RAG models to generate responses beyond the scope of their initial training data.
Background
Evolution of NLP and Language Models:
The journey of Natural Language Processing (NLP) has been marked by continuous growth, from the early days of rule-based systems to the current era of machine learning and deep learning models. This change reflects the overall development of artificial intelligence. It has shifted from systems based on strict rules and small amounts of data to more advanced models that can learn from large datasets. Creating models such as LSTM (Long Short-Term Memory) and the Transformer architecture were necessary steps forward, making it possible for machines to understand and produce language more complexly.
The Rise of Transformer-based Models:
Introduced in 2017, the Transformer architecture transformed the field of natural language processing. It's known for effectively managing sequences of data and its streamlined training approach. This architecture is a critical component of models such as BERT and GPT, which are initially trained on large amounts of text and further refined for specific uses. BERT stands out for its unique bidirectional training, which provides a more thorough grasp of a language’s context and subtle aspects.
Challenges with Traditional Models:
Despite their impressive capabilities, these models have inherent limitations, especially when it comes to tasks that require extensive, specific knowledge. In functions that require a lot of knowledge, these models often fall short compared to more specialized structures. Also, since these models are parametric, they are confined to the information they were trained with and need help to adapt to new data after their training. This limitation becomes a challenge in environments that are constantly changing.
Information Retrieval in Computing:
Information retrieval has been a critical component in computing, dealing with the organization, storage, retrieval, and evaluation of information. Traditional information retrieval systems have been integral in various applications, from search engines to recommendation systems. However, their integration into NLP models for enhancing language understanding and generation is relatively recent.
Need for Advanced Integration:
The difficulty that traditional language models face in dealing with fast-changing, knowledge-heavy tasks has sparked interest in models that combine the strength of pre-trained language models with the flexibility of external, non-parametric memory. This combination is crucial for addressing the issues with fixed knowledge bases and the models' lack of real-time learning and adaptation.
How RAG Models Differ from Traditional Language Models
Traditional language models, such as BERT or GPT, generate text based on patterns and information learned during their training phase. Their knowledge is static and limited to the dataset they were trained on. As a result, while they excel in understanding and generating language based on learned contexts, their ability to provide up-to-date information or details not covered in their training could be improved.
In contrast, RAG models introduce an element of dynamism and adaptability. By leveraging an IR system, they can access a broader and more current knowledge base, which is not confined to their training data. This capability benefits tasks requiring detailed, specific, and current information.
The Architecture and Workflow of RAG Models
The architecture of a RAG model integrates the neural network-based language model with a separate retrieval component. The retrieval component is typically a dense vector space where documents or information snippets are stored as vectors. When the RAG model generates text, it queries this vector space based on the input context or the partially caused response. The retrieval system then returns the most relevant documents or information snippets, which the language model uses to inform the next part of its text generation.
This process involves a seamless interaction between the generative model and the retrieval system. As the model generates text, it may repeatedly query the retrieval system to refine or expand upon the information it generates. This iterative process continues until the generation task is complete, ensuring the output is contextually coherent and enriched with the most relevant and current information from the external data source.
Figure 1- Architecture of RAG
Retrieval-Augmented Generation: An Overview
Retrieval-augmented generation (RAG) represents a novel approach to natural language processing, merging the strengths of generative language models with external information retrieval systems. The essence of RAG lies in its ability to dynamically augment the language generation process with information retrieved in real-time from a vast external database, such as Wikipedia. This approach allows RAG models to produce contextually relevant responses rich in factual details and current information.
The RAG system essentially consists of two main components:
Generative language model
Information retrieval (IR) subsystem.
The generative model, similar to traditional language models, is responsible for the primary task of text generation. However, unlike conventional models that rely solely on their pre-trained knowledge, RAG models consult the IR component to fetch relevant external information during the generation process. This integration enables RAG models to generate responses beyond the scope of their initial training data.
Background
Evolution of NLP and Language Models:
The journey of Natural Language Processing (NLP) has been marked by continuous growth, from the early days of rule-based systems to the current era of machine learning and deep learning models. This change reflects the overall development of artificial intelligence. It has shifted from systems based on strict rules and small amounts of data to more advanced models that can learn from large datasets. Creating models such as LSTM (Long Short-Term Memory) and the Transformer architecture were necessary steps forward, making it possible for machines to understand and produce language more complexly.
The Rise of Transformer-based Models:
Introduced in 2017, the Transformer architecture transformed the field of natural language processing. It's known for effectively managing sequences of data and its streamlined training approach. This architecture is a critical component of models such as BERT and GPT, which are initially trained on large amounts of text and further refined for specific uses. BERT stands out for its unique bidirectional training, which provides a more thorough grasp of a language’s context and subtle aspects.
Challenges with Traditional Models:
Despite their impressive capabilities, these models have inherent limitations, especially when it comes to tasks that require extensive, specific knowledge. In functions that require a lot of knowledge, these models often fall short compared to more specialized structures. Also, since these models are parametric, they are confined to the information they were trained with and need help to adapt to new data after their training. This limitation becomes a challenge in environments that are constantly changing.
Information Retrieval in Computing:
Information retrieval has been a critical component in computing, dealing with the organization, storage, retrieval, and evaluation of information. Traditional information retrieval systems have been integral in various applications, from search engines to recommendation systems. However, their integration into NLP models for enhancing language understanding and generation is relatively recent.
Need for Advanced Integration:
The difficulty that traditional language models face in dealing with fast-changing, knowledge-heavy tasks has sparked interest in models that combine the strength of pre-trained language models with the flexibility of external, non-parametric memory. This combination is crucial for addressing the issues with fixed knowledge bases and the models' lack of real-time learning and adaptation.
How RAG Models Differ from Traditional Language Models
Traditional language models, such as BERT or GPT, generate text based on patterns and information learned during their training phase. Their knowledge is static and limited to the dataset they were trained on. As a result, while they excel in understanding and generating language based on learned contexts, their ability to provide up-to-date information or details not covered in their training could be improved.
In contrast, RAG models introduce an element of dynamism and adaptability. By leveraging an IR system, they can access a broader and more current knowledge base, which is not confined to their training data. This capability benefits tasks requiring detailed, specific, and current information.
The Architecture and Workflow of RAG Models
The architecture of a RAG model integrates the neural network-based language model with a separate retrieval component. The retrieval component is typically a dense vector space where documents or information snippets are stored as vectors. When the RAG model generates text, it queries this vector space based on the input context or the partially caused response. The retrieval system then returns the most relevant documents or information snippets, which the language model uses to inform the next part of its text generation.
This process involves a seamless interaction between the generative model and the retrieval system. As the model generates text, it may repeatedly query the retrieval system to refine or expand upon the information it generates. This iterative process continues until the generation task is complete, ensuring the output is contextually coherent and enriched with the most relevant and current information from the external data source.
Figure 1- Architecture of RAG
Technical Exploration of Retrieval-Augmented
Retrieval-augmented generation (RAG) models combine high-level natural language processing methods and complex information retrieval systems. Essentially, they use the capabilities of big, pre-trained language models similar to those in BERT or GPT. But RAG models go a step further by adding a retrieval component. This component accesses an outside, non-parametric database like Wikipedia, allowing the models to pull in a wide range of information.
The technical brilliance of RAG lies in its ability to perform real-time searches within this external database, fetching relevant information that directly informs and enhances the language generation process. This process is not just a simple lookup; it involves complex algorithms that determine the relevance of external information to the current context of the text being generated.
Parametric vs. Non-Parametric Memory
To understand RAG models, it's crucial to differentiate between parametric and non-parametric memory. Parametric memory refers to the knowledge embedded within the model parameters. This is the kind of memory traditional language models use – knowledge gained from training data encoded within the model's neural network structure. It is static, limited to what the model learned during its training phase.
Non-parametric memory, on the other hand, is external to the model. It is not fixed or limited by the model's training. Instead, it can be seen as a vast, dynamic repository of information the model can query to supplement its knowledge. This type of memory is crucial for tasks that require up-to-date information or expertise beyond what is available in the training data.
Integration of Retrieval Mechanisms in RAG
The integration of retrieval mechanisms into RAG models is a sophisticated process. When an RAG model receives an input or generates a response, it activates its retrieval component. This component works by translating the context or query into a format understandable by the external database – often into a vector representation using techniques similar to those in semantic search.
Once the query is formulated, the retrieval system searches its database for the most relevant information. This retrieval is based on the similarity between the query vector and the vectors representing the information in the database. The most pertinent information is then fed back into the language model.
The language model uses this retrieved information to guide its generation process. It doesn't simply regurgitate the retrieved text; instead, it intelligently integrates this information, combining it with its pre-trained knowledge to generate a coherent, informed, and contextually relevant response.
Technical Exploration of Retrieval-Augmented
Retrieval-augmented generation (RAG) models combine high-level natural language processing methods and complex information retrieval systems. Essentially, they use the capabilities of big, pre-trained language models similar to those in BERT or GPT. But RAG models go a step further by adding a retrieval component. This component accesses an outside, non-parametric database like Wikipedia, allowing the models to pull in a wide range of information.
The technical brilliance of RAG lies in its ability to perform real-time searches within this external database, fetching relevant information that directly informs and enhances the language generation process. This process is not just a simple lookup; it involves complex algorithms that determine the relevance of external information to the current context of the text being generated.
Parametric vs. Non-Parametric Memory
To understand RAG models, it's crucial to differentiate between parametric and non-parametric memory. Parametric memory refers to the knowledge embedded within the model parameters. This is the kind of memory traditional language models use – knowledge gained from training data encoded within the model's neural network structure. It is static, limited to what the model learned during its training phase.
Non-parametric memory, on the other hand, is external to the model. It is not fixed or limited by the model's training. Instead, it can be seen as a vast, dynamic repository of information the model can query to supplement its knowledge. This type of memory is crucial for tasks that require up-to-date information or expertise beyond what is available in the training data.
Integration of Retrieval Mechanisms in RAG
The integration of retrieval mechanisms into RAG models is a sophisticated process. When an RAG model receives an input or generates a response, it activates its retrieval component. This component works by translating the context or query into a format understandable by the external database – often into a vector representation using techniques similar to those in semantic search.
Once the query is formulated, the retrieval system searches its database for the most relevant information. This retrieval is based on the similarity between the query vector and the vectors representing the information in the database. The most pertinent information is then fed back into the language model.
The language model uses this retrieved information to guide its generation process. It doesn't simply regurgitate the retrieved text; instead, it intelligently integrates this information, combining it with its pre-trained knowledge to generate a coherent, informed, and contextually relevant response.
Technical Exploration of Retrieval-Augmented
Retrieval-augmented generation (RAG) models combine high-level natural language processing methods and complex information retrieval systems. Essentially, they use the capabilities of big, pre-trained language models similar to those in BERT or GPT. But RAG models go a step further by adding a retrieval component. This component accesses an outside, non-parametric database like Wikipedia, allowing the models to pull in a wide range of information.
The technical brilliance of RAG lies in its ability to perform real-time searches within this external database, fetching relevant information that directly informs and enhances the language generation process. This process is not just a simple lookup; it involves complex algorithms that determine the relevance of external information to the current context of the text being generated.
Parametric vs. Non-Parametric Memory
To understand RAG models, it's crucial to differentiate between parametric and non-parametric memory. Parametric memory refers to the knowledge embedded within the model parameters. This is the kind of memory traditional language models use – knowledge gained from training data encoded within the model's neural network structure. It is static, limited to what the model learned during its training phase.
Non-parametric memory, on the other hand, is external to the model. It is not fixed or limited by the model's training. Instead, it can be seen as a vast, dynamic repository of information the model can query to supplement its knowledge. This type of memory is crucial for tasks that require up-to-date information or expertise beyond what is available in the training data.
Integration of Retrieval Mechanisms in RAG
The integration of retrieval mechanisms into RAG models is a sophisticated process. When an RAG model receives an input or generates a response, it activates its retrieval component. This component works by translating the context or query into a format understandable by the external database – often into a vector representation using techniques similar to those in semantic search.
Once the query is formulated, the retrieval system searches its database for the most relevant information. This retrieval is based on the similarity between the query vector and the vectors representing the information in the database. The most pertinent information is then fed back into the language model.
The language model uses this retrieved information to guide its generation process. It doesn't simply regurgitate the retrieved text; instead, it intelligently integrates this information, combining it with its pre-trained knowledge to generate a coherent, informed, and contextually relevant response.
Technical Exploration of Retrieval-Augmented
Retrieval-augmented generation (RAG) models combine high-level natural language processing methods and complex information retrieval systems. Essentially, they use the capabilities of big, pre-trained language models similar to those in BERT or GPT. But RAG models go a step further by adding a retrieval component. This component accesses an outside, non-parametric database like Wikipedia, allowing the models to pull in a wide range of information.
The technical brilliance of RAG lies in its ability to perform real-time searches within this external database, fetching relevant information that directly informs and enhances the language generation process. This process is not just a simple lookup; it involves complex algorithms that determine the relevance of external information to the current context of the text being generated.
Parametric vs. Non-Parametric Memory
To understand RAG models, it's crucial to differentiate between parametric and non-parametric memory. Parametric memory refers to the knowledge embedded within the model parameters. This is the kind of memory traditional language models use – knowledge gained from training data encoded within the model's neural network structure. It is static, limited to what the model learned during its training phase.
Non-parametric memory, on the other hand, is external to the model. It is not fixed or limited by the model's training. Instead, it can be seen as a vast, dynamic repository of information the model can query to supplement its knowledge. This type of memory is crucial for tasks that require up-to-date information or expertise beyond what is available in the training data.
Integration of Retrieval Mechanisms in RAG
The integration of retrieval mechanisms into RAG models is a sophisticated process. When an RAG model receives an input or generates a response, it activates its retrieval component. This component works by translating the context or query into a format understandable by the external database – often into a vector representation using techniques similar to those in semantic search.
Once the query is formulated, the retrieval system searches its database for the most relevant information. This retrieval is based on the similarity between the query vector and the vectors representing the information in the database. The most pertinent information is then fed back into the language model.
The language model uses this retrieved information to guide its generation process. It doesn't simply regurgitate the retrieved text; instead, it intelligently integrates this information, combining it with its pre-trained knowledge to generate a coherent, informed, and contextually relevant response.
Use Cases and Real-world Applications
Retrieval-augmented generation (RAG) models, with their unique blend of generative language processing and dynamic information retrieval, find applications in various fields. These models are theoretical constructs and have practical implications in industries ranging from customer service to academic research. Some real-world applications are:
Customer Service and Chatbots
In customer service, chatbots powered by RAG models have significantly enhanced the quality of automated customer interactions. Traditional chatbots, relying solely on pre-trained responses, often need help with complex or specific customer queries that fall outside their training data. RAG models address this limitation by retrieving up-to-date information from external databases.
For example, a customer asking a RAG-powered chatbot about a company's latest policies or offers can receive real-time, accurate information. This capability is especially beneficial for banking, telecommunications, and e-commerce sectors, where procedures and products frequently change.
Academic Research and Information Retrieval
RAG models have revolutionized the way researchers access information. In academic settings, these models assist in literature review and data gathering by quickly pulling relevant information from various published papers and databases. Unlike conventional search engines, which offer a selection of documents, RAG models can generate concise summaries or answer specific questions.
For instance, a researcher can query a RAG-powered system about the latest findings in a particular field of study. The model can then retrieve and synthesize information from recent publications to provide a comprehensive answer, saving the researcher valuable time.
Journalism
In journalism, RAG models generate informative, accurate, and up-to-date content. Journalists and content creators often use these models to quickly gather background information on a topic, ensuring their articles include the most recent and relevant data.
A practical application can be seen in the generation of news summaries. A RAG model can pull in the latest information about a developing story from various news sources and generate a summary that provides a comprehensive overview of the event.
Educational Tools and E-Learning Platforms
Automated Tutoring System Example: Imagine a RAG-based system that can assist students in understanding complex physics concepts. When a student asks about quantum mechanics, it will retrieve current research, explanations, and educational content to provide a tailored, understandable description.
Legal and Compliance Research
Legal Document Analysis Example: A legal research tool can employ RAG to analyze a vast database of legal documents. When a lawyer searches for precedent cases related to intellectual property, it will retrieve and summarize relevant issues, saving hours of manual research.
Integration of RAG in Large Language Models (LLMs)
Several leading platforms and AI research entities have incorporated Retrieval-Augmented Generation (RAG) into their large language models (LLMs), enhancing their capabilities to generate accurate and contextually relevant responses. Here's how some of them have integrated RAG:
ChatGPT Retrieval Plugin:
OpenAI has developed a retrieval plugin specifically for ChatGPT. This plugin allows ChatGPT to access a database of documents, using retrieval algorithms to find and incorporate relevant information into its responses, thereby enhancing the richness and accuracy of its output.
IBM Watsonx.ai:
IBM's Watsonx.ai has been configured to deploy the RAG pattern, enabling it to produce contextually appropriate and precise outputs, leveraging its vast data processing capabilities.
Azure Machine Learning:
Microsoft's Azure Machine Learning platform offers the capability to integrate RAG into AI models. This can be done through Azure AI Studio for a more visual approach or by writing code for customized implementations using Azure Machine Learning pipelines.
HuggingFace Transformer Plugin:
Known for its extensive work in the field of NLP, HuggingFace offers a transformer plugin designed to facilitate the creation and deployment of RAG models. This tool allows developers to generate models that efficiently blend language generation with information retrieval.
Meta AI (Formerly Facebook Research):
Meta AI Research has developed a unique framework that combines retrieval and generation processes seamlessly. This framework is particularly tailored for tasks requiring extracting specific information from large data repositories and generating coherent, context-aware responses.
These integrations ca be visualized as follows:
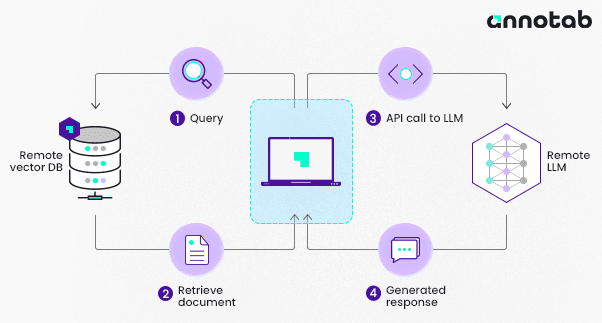
Figure 2-Integration of RAG in LLM
Use Cases and Real-world Applications
Retrieval-augmented generation (RAG) models, with their unique blend of generative language processing and dynamic information retrieval, find applications in various fields. These models are theoretical constructs and have practical implications in industries ranging from customer service to academic research. Some real-world applications are:
Customer Service and Chatbots
In customer service, chatbots powered by RAG models have significantly enhanced the quality of automated customer interactions. Traditional chatbots, relying solely on pre-trained responses, often need help with complex or specific customer queries that fall outside their training data. RAG models address this limitation by retrieving up-to-date information from external databases.
For example, a customer asking a RAG-powered chatbot about a company's latest policies or offers can receive real-time, accurate information. This capability is especially beneficial for banking, telecommunications, and e-commerce sectors, where procedures and products frequently change.
Academic Research and Information Retrieval
RAG models have revolutionized the way researchers access information. In academic settings, these models assist in literature review and data gathering by quickly pulling relevant information from various published papers and databases. Unlike conventional search engines, which offer a selection of documents, RAG models can generate concise summaries or answer specific questions.
For instance, a researcher can query a RAG-powered system about the latest findings in a particular field of study. The model can then retrieve and synthesize information from recent publications to provide a comprehensive answer, saving the researcher valuable time.
Journalism
In journalism, RAG models generate informative, accurate, and up-to-date content. Journalists and content creators often use these models to quickly gather background information on a topic, ensuring their articles include the most recent and relevant data.
A practical application can be seen in the generation of news summaries. A RAG model can pull in the latest information about a developing story from various news sources and generate a summary that provides a comprehensive overview of the event.
Educational Tools and E-Learning Platforms
Automated Tutoring System Example: Imagine a RAG-based system that can assist students in understanding complex physics concepts. When a student asks about quantum mechanics, it will retrieve current research, explanations, and educational content to provide a tailored, understandable description.
Legal and Compliance Research
Legal Document Analysis Example: A legal research tool can employ RAG to analyze a vast database of legal documents. When a lawyer searches for precedent cases related to intellectual property, it will retrieve and summarize relevant issues, saving hours of manual research.
Integration of RAG in Large Language Models (LLMs)
Several leading platforms and AI research entities have incorporated Retrieval-Augmented Generation (RAG) into their large language models (LLMs), enhancing their capabilities to generate accurate and contextually relevant responses. Here's how some of them have integrated RAG:
ChatGPT Retrieval Plugin:
OpenAI has developed a retrieval plugin specifically for ChatGPT. This plugin allows ChatGPT to access a database of documents, using retrieval algorithms to find and incorporate relevant information into its responses, thereby enhancing the richness and accuracy of its output.
IBM Watsonx.ai:
IBM's Watsonx.ai has been configured to deploy the RAG pattern, enabling it to produce contextually appropriate and precise outputs, leveraging its vast data processing capabilities.
Azure Machine Learning:
Microsoft's Azure Machine Learning platform offers the capability to integrate RAG into AI models. This can be done through Azure AI Studio for a more visual approach or by writing code for customized implementations using Azure Machine Learning pipelines.
HuggingFace Transformer Plugin:
Known for its extensive work in the field of NLP, HuggingFace offers a transformer plugin designed to facilitate the creation and deployment of RAG models. This tool allows developers to generate models that efficiently blend language generation with information retrieval.
Meta AI (Formerly Facebook Research):
Meta AI Research has developed a unique framework that combines retrieval and generation processes seamlessly. This framework is particularly tailored for tasks requiring extracting specific information from large data repositories and generating coherent, context-aware responses.
These integrations ca be visualized as follows:
Figure 2-Integration of RAG in LLM
Use Cases and Real-world Applications
Retrieval-augmented generation (RAG) models, with their unique blend of generative language processing and dynamic information retrieval, find applications in various fields. These models are theoretical constructs and have practical implications in industries ranging from customer service to academic research. Some real-world applications are:
Customer Service and Chatbots
In customer service, chatbots powered by RAG models have significantly enhanced the quality of automated customer interactions. Traditional chatbots, relying solely on pre-trained responses, often need help with complex or specific customer queries that fall outside their training data. RAG models address this limitation by retrieving up-to-date information from external databases.
For example, a customer asking a RAG-powered chatbot about a company's latest policies or offers can receive real-time, accurate information. This capability is especially beneficial for banking, telecommunications, and e-commerce sectors, where procedures and products frequently change.
Academic Research and Information Retrieval
RAG models have revolutionized the way researchers access information. In academic settings, these models assist in literature review and data gathering by quickly pulling relevant information from various published papers and databases. Unlike conventional search engines, which offer a selection of documents, RAG models can generate concise summaries or answer specific questions.
For instance, a researcher can query a RAG-powered system about the latest findings in a particular field of study. The model can then retrieve and synthesize information from recent publications to provide a comprehensive answer, saving the researcher valuable time.
Journalism
In journalism, RAG models generate informative, accurate, and up-to-date content. Journalists and content creators often use these models to quickly gather background information on a topic, ensuring their articles include the most recent and relevant data.
A practical application can be seen in the generation of news summaries. A RAG model can pull in the latest information about a developing story from various news sources and generate a summary that provides a comprehensive overview of the event.
Educational Tools and E-Learning Platforms
Automated Tutoring System Example: Imagine a RAG-based system that can assist students in understanding complex physics concepts. When a student asks about quantum mechanics, it will retrieve current research, explanations, and educational content to provide a tailored, understandable description.
Legal and Compliance Research
Legal Document Analysis Example: A legal research tool can employ RAG to analyze a vast database of legal documents. When a lawyer searches for precedent cases related to intellectual property, it will retrieve and summarize relevant issues, saving hours of manual research.
Integration of RAG in Large Language Models (LLMs)
Several leading platforms and AI research entities have incorporated Retrieval-Augmented Generation (RAG) into their large language models (LLMs), enhancing their capabilities to generate accurate and contextually relevant responses. Here's how some of them have integrated RAG:
ChatGPT Retrieval Plugin:
OpenAI has developed a retrieval plugin specifically for ChatGPT. This plugin allows ChatGPT to access a database of documents, using retrieval algorithms to find and incorporate relevant information into its responses, thereby enhancing the richness and accuracy of its output.
IBM Watsonx.ai:
IBM's Watsonx.ai has been configured to deploy the RAG pattern, enabling it to produce contextually appropriate and precise outputs, leveraging its vast data processing capabilities.
Azure Machine Learning:
Microsoft's Azure Machine Learning platform offers the capability to integrate RAG into AI models. This can be done through Azure AI Studio for a more visual approach or by writing code for customized implementations using Azure Machine Learning pipelines.
HuggingFace Transformer Plugin:
Known for its extensive work in the field of NLP, HuggingFace offers a transformer plugin designed to facilitate the creation and deployment of RAG models. This tool allows developers to generate models that efficiently blend language generation with information retrieval.
Meta AI (Formerly Facebook Research):
Meta AI Research has developed a unique framework that combines retrieval and generation processes seamlessly. This framework is particularly tailored for tasks requiring extracting specific information from large data repositories and generating coherent, context-aware responses.
These integrations ca be visualized as follows:
Figure 2-Integration of RAG in LLM
Use Cases and Real-world Applications
Retrieval-augmented generation (RAG) models, with their unique blend of generative language processing and dynamic information retrieval, find applications in various fields. These models are theoretical constructs and have practical implications in industries ranging from customer service to academic research. Some real-world applications are:
Customer Service and Chatbots
In customer service, chatbots powered by RAG models have significantly enhanced the quality of automated customer interactions. Traditional chatbots, relying solely on pre-trained responses, often need help with complex or specific customer queries that fall outside their training data. RAG models address this limitation by retrieving up-to-date information from external databases.
For example, a customer asking a RAG-powered chatbot about a company's latest policies or offers can receive real-time, accurate information. This capability is especially beneficial for banking, telecommunications, and e-commerce sectors, where procedures and products frequently change.
Academic Research and Information Retrieval
RAG models have revolutionized the way researchers access information. In academic settings, these models assist in literature review and data gathering by quickly pulling relevant information from various published papers and databases. Unlike conventional search engines, which offer a selection of documents, RAG models can generate concise summaries or answer specific questions.
For instance, a researcher can query a RAG-powered system about the latest findings in a particular field of study. The model can then retrieve and synthesize information from recent publications to provide a comprehensive answer, saving the researcher valuable time.
Journalism
In journalism, RAG models generate informative, accurate, and up-to-date content. Journalists and content creators often use these models to quickly gather background information on a topic, ensuring their articles include the most recent and relevant data.
A practical application can be seen in the generation of news summaries. A RAG model can pull in the latest information about a developing story from various news sources and generate a summary that provides a comprehensive overview of the event.
Educational Tools and E-Learning Platforms
Automated Tutoring System Example: Imagine a RAG-based system that can assist students in understanding complex physics concepts. When a student asks about quantum mechanics, it will retrieve current research, explanations, and educational content to provide a tailored, understandable description.
Legal and Compliance Research
Legal Document Analysis Example: A legal research tool can employ RAG to analyze a vast database of legal documents. When a lawyer searches for precedent cases related to intellectual property, it will retrieve and summarize relevant issues, saving hours of manual research.
Integration of RAG in Large Language Models (LLMs)
Several leading platforms and AI research entities have incorporated Retrieval-Augmented Generation (RAG) into their large language models (LLMs), enhancing their capabilities to generate accurate and contextually relevant responses. Here's how some of them have integrated RAG:
ChatGPT Retrieval Plugin:
OpenAI has developed a retrieval plugin specifically for ChatGPT. This plugin allows ChatGPT to access a database of documents, using retrieval algorithms to find and incorporate relevant information into its responses, thereby enhancing the richness and accuracy of its output.
IBM Watsonx.ai:
IBM's Watsonx.ai has been configured to deploy the RAG pattern, enabling it to produce contextually appropriate and precise outputs, leveraging its vast data processing capabilities.
Azure Machine Learning:
Microsoft's Azure Machine Learning platform offers the capability to integrate RAG into AI models. This can be done through Azure AI Studio for a more visual approach or by writing code for customized implementations using Azure Machine Learning pipelines.
HuggingFace Transformer Plugin:
Known for its extensive work in the field of NLP, HuggingFace offers a transformer plugin designed to facilitate the creation and deployment of RAG models. This tool allows developers to generate models that efficiently blend language generation with information retrieval.
Meta AI (Formerly Facebook Research):
Meta AI Research has developed a unique framework that combines retrieval and generation processes seamlessly. This framework is particularly tailored for tasks requiring extracting specific information from large data repositories and generating coherent, context-aware responses.
These integrations ca be visualized as follows:
Figure 2-Integration of RAG in LLM
Pros and Cons of RAG
Pros
RAG systems can pull in a wealth of external information, significantly enriching language generation with detailed real-world context and facts.
RAG systems are more adept at responding to unusual or out-of-distribution queries than traditional models that have been fine-tuned on specific datasets.
RAG models benefit from using pre-trained language models, which lessens their reliance on large volumes of fine-tuning data, a process that can often be resource-heavy.
Cons
Due to their dual mechanism of language generation and information retrieval, RAG models demand significant computational resources. This might limit their use for smaller entities or individual users with limited computing power.
When incorporating external data sources, data privacy and security issues arise, especially if sensitive or personal information is involved in the retrieval process.
The accuracy and reliability of a RAG model rely significantly on the reliability of the external data source. Biased or inaccurate data can lead to flawed outputs, posing a challenge in ensuring the integrity of the information retrieved.
Setting up and maintaining a RAG system involves a complex integration of different components. This complexity can pose a challenge regarding the technical expertise required and ongoing system maintenance.
The process of retrieving information from an external source can introduce latency, impacting the response time of the RAG model, which is a critical factor in real-time applications like interactive chatbots.
Pros and Cons of RAG
Pros
RAG systems can pull in a wealth of external information, significantly enriching language generation with detailed real-world context and facts.
RAG systems are more adept at responding to unusual or out-of-distribution queries than traditional models that have been fine-tuned on specific datasets.
RAG models benefit from using pre-trained language models, which lessens their reliance on large volumes of fine-tuning data, a process that can often be resource-heavy.
Cons
Due to their dual mechanism of language generation and information retrieval, RAG models demand significant computational resources. This might limit their use for smaller entities or individual users with limited computing power.
When incorporating external data sources, data privacy and security issues arise, especially if sensitive or personal information is involved in the retrieval process.
The accuracy and reliability of a RAG model rely significantly on the reliability of the external data source. Biased or inaccurate data can lead to flawed outputs, posing a challenge in ensuring the integrity of the information retrieved.
Setting up and maintaining a RAG system involves a complex integration of different components. This complexity can pose a challenge regarding the technical expertise required and ongoing system maintenance.
The process of retrieving information from an external source can introduce latency, impacting the response time of the RAG model, which is a critical factor in real-time applications like interactive chatbots.
Pros and Cons of RAG
Pros
RAG systems can pull in a wealth of external information, significantly enriching language generation with detailed real-world context and facts.
RAG systems are more adept at responding to unusual or out-of-distribution queries than traditional models that have been fine-tuned on specific datasets.
RAG models benefit from using pre-trained language models, which lessens their reliance on large volumes of fine-tuning data, a process that can often be resource-heavy.
Cons
Due to their dual mechanism of language generation and information retrieval, RAG models demand significant computational resources. This might limit their use for smaller entities or individual users with limited computing power.
When incorporating external data sources, data privacy and security issues arise, especially if sensitive or personal information is involved in the retrieval process.
The accuracy and reliability of a RAG model rely significantly on the reliability of the external data source. Biased or inaccurate data can lead to flawed outputs, posing a challenge in ensuring the integrity of the information retrieved.
Setting up and maintaining a RAG system involves a complex integration of different components. This complexity can pose a challenge regarding the technical expertise required and ongoing system maintenance.
The process of retrieving information from an external source can introduce latency, impacting the response time of the RAG model, which is a critical factor in real-time applications like interactive chatbots.
Pros and Cons of RAG
Pros
RAG systems can pull in a wealth of external information, significantly enriching language generation with detailed real-world context and facts.
RAG systems are more adept at responding to unusual or out-of-distribution queries than traditional models that have been fine-tuned on specific datasets.
RAG models benefit from using pre-trained language models, which lessens their reliance on large volumes of fine-tuning data, a process that can often be resource-heavy.
Cons
Due to their dual mechanism of language generation and information retrieval, RAG models demand significant computational resources. This might limit their use for smaller entities or individual users with limited computing power.
When incorporating external data sources, data privacy and security issues arise, especially if sensitive or personal information is involved in the retrieval process.
The accuracy and reliability of a RAG model rely significantly on the reliability of the external data source. Biased or inaccurate data can lead to flawed outputs, posing a challenge in ensuring the integrity of the information retrieved.
Setting up and maintaining a RAG system involves a complex integration of different components. This complexity can pose a challenge regarding the technical expertise required and ongoing system maintenance.
The process of retrieving information from an external source can introduce latency, impacting the response time of the RAG model, which is a critical factor in real-time applications like interactive chatbots.
RAG in Action: Coding Examples
Implementing a Retrieval-Augmented Generation (RAG) model can be complex. Still, the following pseudocode and Python code snippet using Hugging Face's Transformers library provide a basic illustration of how RAG can be implemented.
Pseudocode for RAG Implementation:
Load Pre-Trained Models:
Load a pre-trained seq2seq model (e.g., BART, T5) for language generation.
Load a pre-trained retriever model (e.g., DPR) for information retrieval.
Process User Input:
Receive an input query or prompt from the user.
Retrieve Relevant Information:
Use the retriever model to fetch relevant documents or information snippets based on the user input.
Rank and select the top documents based on relevance.
Generate Response with Context:
Combine the user input and retrieved documents to form an extended context.
Use the seq2seq model to generate a response based on this comprehensive context.
Output the Response:
Present the generated response to the user.
Python Code Snippet Using Hugging Face's Transformer:
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration, RagSequenceForGeneration
# Initialize tokenizer and models
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
# Process user input
input_query = "What is the capital of France?"
input_ids = tokenizer(input_query, return_tensors="pt").input_ids
# Generate response
generated_ids = model.generate(input_ids)
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Generated response: {generated_text}")The above code includes initializing the tokenizer and models, processing the user input, and then generating a response using the RAG model. The model combines the generative capabilities of a seq2seq model with the information retrieval features of the retriever to generate informed responses.
Integrating Elasticsearch and GPT-2 for RAG-like Functionality:
Another approach to implementing a basic version of Retrieval-Augmented Generation (RAG) functionality, besides using Hugging Face's Transformers library, involves combining separate components for retrieval and generation. For generation, you can use Elasticsearch for information retrieval and a pre-trained language model like GPT-2 from OpenAI. Here's a simplified example:
Pseudocode:
Set Up Elasticsearch for Document Retrieval:
Index a set of documents in Elasticsearch.
When a query is received, search Elasticsearch for the most relevant documents.
Use GPT-2 for Text Generation:
Load a pre-trained GPT-2 model.
Combine the user query with retrieved documents to form an extended context.
Generate a response based on this comprehensive context.
Combine Both for RAG-like Functionality:
Process user input to formulate a query.
Retrieve relevant information from Elasticsearch.
Use the retrieved data and the user query as input to GPT-2 to generate a response.
Python Code Snippet:
This example requires an Elasticsearch server and the Elasticsearch and Transformers Python packages. You need to download and install ElasticSearch before performing the task. Below are the basic steps to start with a single-node Elasticsearch server for testing or development purposes. Consider consulting Elasticsearch documentation or seeking professional assistance for production use or more complex setups.
System Requirements:
Ensure that you have a suitable server or virtual machine to host Elasticsearch. Elasticsearch requires a minimum amount of RAM and CPU power. Refer to the Elasticsearch documentation for specific system requirements.
Install Java:
Elasticsearch is built on Java, so you must install a compatible version of Java on your server. Elasticsearch typically works with OpenJDK or Oracle JDK. Install Java based on your operating system's instructions.
Download Elasticsearch:
Visit the Elasticsearch download page (https://www.elastic.co/downloads/elasticsearch) and download the Elasticsearch distribution that matches your operating system.
Install Elasticsearch:
Extract the downloaded Elasticsearch archive to a directory on your server. You can use tools like tar (Linux) or unzip (Windows).
Configure Elasticsearch:
Navigate to the config directory within the Elasticsearch installation directory. Open the elasticsearch.yml configuration file.
Configure Elasticsearch settings as needed. Standard configurations include specifying cluster and node names, network settings, and data paths.
Start Elasticsearch:
In the Elasticsearch installation directory, run the following command to start Elasticsearch:
elasticsearchMoreover, don’t forget to add its path to environment variables. Elasticsearch should now be running on your server.
Note: If you face an error when signing in to run ElasticSearch, you can use the following command to auto-generate a new password for it:
elasticsearch-setup-passwords autoRun the above command in ElasticSearch installation directory.
Test Elasticsearch:
Open a web browser and access the Elasticsearch REST API at 'http://localhost:9200'. You should see a JSON response indicating that Elasticsearch is running. The response would be as follows:
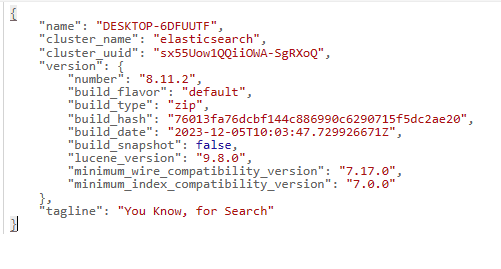
Additional Configuration (Optional):
Depending on your use case, you may need to further configure Elasticsearch for security, index settings, and more. Refer to the Elasticsearch documentation for advanced configurations.
Install Elasticsearch Plugins (Optional):
Elasticsearch supports plugins that provide additional functionality. You can install plugins as needed by following the Elasticsearch plugin installation instructions.
Index Data:
To work with data in Elasticsearch, you'll need to create an index and index documents. You can use tools like Kibana or Elasticsearch's REST API to index and query data.
Monitor and Manage:
Use Elasticsearch monitoring and management tools to monitor the health and performance of your Elasticsearch server.
Security (Important):
For production use, ensure that you have proper security measures, including authentication, access control, and encryption, to protect your Elasticsearch cluster.
from elasticsearch import Elasticsearch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Initialize Elasticsearch client
es = Elasticsearch(['http://locahost:9200'])
es.indices.create(index='my-index', ignore=400)
# Function to retrieve documents from Elasticsearch
def retrieve_documents(query, index="your_index", num_docs=3):
response = es.search(index=index, query={"match": {"content": query}}, size=num_docs)
return [doc['_source']['content'] for doc in response['hits']['hits']]
# Initialize GPT-2 Model and Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# Process user input and retrieve documents
user_query = "What is the capital of France?"
retrieved_docs = retrieve_documents(user_query)
extended_context = user_query + " " + " ".join(retrieved_docs)
# Generate response with GPT-2
inputs = tokenizer.encode(extended_context, return_tensors="pt")
output = model.generate(inputs, max_length=100, num_return_sequences=1)
response = tokenizer.decode(output[0], skip_special_tokens=True)
print(response)In this example, Elasticsearch retrieves relevant documents based on a user query. These documents and the original query are fed into GPT-2 to generate a response. This approach mimics the RAG model's functionality by combining retrieval and generation but with separate systems for each task. Remember, this is a basic illustration, and actual implementations in production environments would require more sophisticated handling and optimization.
Python Code Snippet:
RAG in Action: Coding Examples
Implementing a Retrieval-Augmented Generation (RAG) model can be complex. Still, the following pseudocode and Python code snippet using Hugging Face's Transformers library provide a basic illustration of how RAG can be implemented.
Pseudocode for RAG Implementation:
Load Pre-Trained Models:
Load a pre-trained seq2seq model (e.g., BART, T5) for language generation.
Load a pre-trained retriever model (e.g., DPR) for information retrieval.
Process User Input:
Receive an input query or prompt from the user.
Retrieve Relevant Information:
Use the retriever model to fetch relevant documents or information snippets based on the user input.
Rank and select the top documents based on relevance.
Generate Response with Context:
Combine the user input and retrieved documents to form an extended context.
Use the seq2seq model to generate a response based on this comprehensive context.
Output the Response:
Present the generated response to the user.
Python Code Snippet Using Hugging Face's Transformer:
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration, RagSequenceForGeneration
# Initialize tokenizer and models
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
# Process user input
input_query = "What is the capital of France?"
input_ids = tokenizer(input_query, return_tensors="pt").input_ids
# Generate response
generated_ids = model.generate(input_ids)
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Generated response: {generated_text}")The above code includes initializing the tokenizer and models, processing the user input, and then generating a response using the RAG model. The model combines the generative capabilities of a seq2seq model with the information retrieval features of the retriever to generate informed responses.
Integrating Elasticsearch and GPT-2 for RAG-like Functionality:
Another approach to implementing a basic version of Retrieval-Augmented Generation (RAG) functionality, besides using Hugging Face's Transformers library, involves combining separate components for retrieval and generation. For generation, you can use Elasticsearch for information retrieval and a pre-trained language model like GPT-2 from OpenAI. Here's a simplified example:
Pseudocode:
Set Up Elasticsearch for Document Retrieval:
Index a set of documents in Elasticsearch.
When a query is received, search Elasticsearch for the most relevant documents.
Use GPT-2 for Text Generation:
Load a pre-trained GPT-2 model.
Combine the user query with retrieved documents to form an extended context.
Generate a response based on this comprehensive context.
Combine Both for RAG-like Functionality:
Process user input to formulate a query.
Retrieve relevant information from Elasticsearch.
Use the retrieved data and the user query as input to GPT-2 to generate a response.
Python Code Snippet:
This example requires an Elasticsearch server and the Elasticsearch and Transformers Python packages. You need to download and install ElasticSearch before performing the task. Below are the basic steps to start with a single-node Elasticsearch server for testing or development purposes. Consider consulting Elasticsearch documentation or seeking professional assistance for production use or more complex setups.
System Requirements:
Ensure that you have a suitable server or virtual machine to host Elasticsearch. Elasticsearch requires a minimum amount of RAM and CPU power. Refer to the Elasticsearch documentation for specific system requirements.
Install Java:
Elasticsearch is built on Java, so you must install a compatible version of Java on your server. Elasticsearch typically works with OpenJDK or Oracle JDK. Install Java based on your operating system's instructions.
Download Elasticsearch:
Visit the Elasticsearch download page (https://www.elastic.co/downloads/elasticsearch) and download the Elasticsearch distribution that matches your operating system.
Install Elasticsearch:
Extract the downloaded Elasticsearch archive to a directory on your server. You can use tools like tar (Linux) or unzip (Windows).
Configure Elasticsearch:
Navigate to the config directory within the Elasticsearch installation directory. Open the elasticsearch.yml configuration file.
Configure Elasticsearch settings as needed. Standard configurations include specifying cluster and node names, network settings, and data paths.
Start Elasticsearch:
In the Elasticsearch installation directory, run the following command to start Elasticsearch:
elasticsearchMoreover, don’t forget to add its path to environment variables. Elasticsearch should now be running on your server.
Note: If you face an error when signing in to run ElasticSearch, you can use the following command to auto-generate a new password for it:
elasticsearch-setup-passwords autoRun the above command in ElasticSearch installation directory.
Test Elasticsearch:
Open a web browser and access the Elasticsearch REST API at 'http://localhost:9200'. You should see a JSON response indicating that Elasticsearch is running. The response would be as follows:
Additional Configuration (Optional):
Depending on your use case, you may need to further configure Elasticsearch for security, index settings, and more. Refer to the Elasticsearch documentation for advanced configurations.
Install Elasticsearch Plugins (Optional):
Elasticsearch supports plugins that provide additional functionality. You can install plugins as needed by following the Elasticsearch plugin installation instructions.
Index Data:
To work with data in Elasticsearch, you'll need to create an index and index documents. You can use tools like Kibana or Elasticsearch's REST API to index and query data.
Monitor and Manage:
Use Elasticsearch monitoring and management tools to monitor the health and performance of your Elasticsearch server.
Security (Important):
For production use, ensure that you have proper security measures, including authentication, access control, and encryption, to protect your Elasticsearch cluster.
from elasticsearch import Elasticsearch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Initialize Elasticsearch client
es = Elasticsearch(['http://locahost:9200'])
es.indices.create(index='my-index', ignore=400)
# Function to retrieve documents from Elasticsearch
def retrieve_documents(query, index="your_index", num_docs=3):
response = es.search(index=index, query={"match": {"content": query}}, size=num_docs)
return [doc['_source']['content'] for doc in response['hits']['hits']]
# Initialize GPT-2 Model and Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# Process user input and retrieve documents
user_query = "What is the capital of France?"
retrieved_docs = retrieve_documents(user_query)
extended_context = user_query + " " + " ".join(retrieved_docs)
# Generate response with GPT-2
inputs = tokenizer.encode(extended_context, return_tensors="pt")
output = model.generate(inputs, max_length=100, num_return_sequences=1)
response = tokenizer.decode(output[0], skip_special_tokens=True)
print(response)In this example, Elasticsearch retrieves relevant documents based on a user query. These documents and the original query are fed into GPT-2 to generate a response. This approach mimics the RAG model's functionality by combining retrieval and generation but with separate systems for each task. Remember, this is a basic illustration, and actual implementations in production environments would require more sophisticated handling and optimization.
Python Code Snippet:
RAG in Action: Coding Examples
Implementing a Retrieval-Augmented Generation (RAG) model can be complex. Still, the following pseudocode and Python code snippet using Hugging Face's Transformers library provide a basic illustration of how RAG can be implemented.
Pseudocode for RAG Implementation:
Load Pre-Trained Models:
Load a pre-trained seq2seq model (e.g., BART, T5) for language generation.
Load a pre-trained retriever model (e.g., DPR) for information retrieval.
Process User Input:
Receive an input query or prompt from the user.
Retrieve Relevant Information:
Use the retriever model to fetch relevant documents or information snippets based on the user input.
Rank and select the top documents based on relevance.
Generate Response with Context:
Combine the user input and retrieved documents to form an extended context.
Use the seq2seq model to generate a response based on this comprehensive context.
Output the Response:
Present the generated response to the user.
Python Code Snippet Using Hugging Face's Transformer:
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration, RagSequenceForGeneration
# Initialize tokenizer and models
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
# Process user input
input_query = "What is the capital of France?"
input_ids = tokenizer(input_query, return_tensors="pt").input_ids
# Generate response
generated_ids = model.generate(input_ids)
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Generated response: {generated_text}")The above code includes initializing the tokenizer and models, processing the user input, and then generating a response using the RAG model. The model combines the generative capabilities of a seq2seq model with the information retrieval features of the retriever to generate informed responses.
Integrating Elasticsearch and GPT-2 for RAG-like Functionality:
Another approach to implementing a basic version of Retrieval-Augmented Generation (RAG) functionality, besides using Hugging Face's Transformers library, involves combining separate components for retrieval and generation. For generation, you can use Elasticsearch for information retrieval and a pre-trained language model like GPT-2 from OpenAI. Here's a simplified example:
Pseudocode:
Set Up Elasticsearch for Document Retrieval:
Index a set of documents in Elasticsearch.
When a query is received, search Elasticsearch for the most relevant documents.
Use GPT-2 for Text Generation:
Load a pre-trained GPT-2 model.
Combine the user query with retrieved documents to form an extended context.
Generate a response based on this comprehensive context.
Combine Both for RAG-like Functionality:
Process user input to formulate a query.
Retrieve relevant information from Elasticsearch.
Use the retrieved data and the user query as input to GPT-2 to generate a response.
Python Code Snippet:
This example requires an Elasticsearch server and the Elasticsearch and Transformers Python packages. You need to download and install ElasticSearch before performing the task. Below are the basic steps to start with a single-node Elasticsearch server for testing or development purposes. Consider consulting Elasticsearch documentation or seeking professional assistance for production use or more complex setups.
System Requirements:
Ensure that you have a suitable server or virtual machine to host Elasticsearch. Elasticsearch requires a minimum amount of RAM and CPU power. Refer to the Elasticsearch documentation for specific system requirements.
Install Java:
Elasticsearch is built on Java, so you must install a compatible version of Java on your server. Elasticsearch typically works with OpenJDK or Oracle JDK. Install Java based on your operating system's instructions.
Download Elasticsearch:
Visit the Elasticsearch download page (https://www.elastic.co/downloads/elasticsearch) and download the Elasticsearch distribution that matches your operating system.
Install Elasticsearch:
Extract the downloaded Elasticsearch archive to a directory on your server. You can use tools like tar (Linux) or unzip (Windows).
Configure Elasticsearch:
Navigate to the config directory within the Elasticsearch installation directory. Open the elasticsearch.yml configuration file.
Configure Elasticsearch settings as needed. Standard configurations include specifying cluster and node names, network settings, and data paths.
Start Elasticsearch:
In the Elasticsearch installation directory, run the following command to start Elasticsearch:
elasticsearchMoreover, don’t forget to add its path to environment variables. Elasticsearch should now be running on your server.
Note: If you face an error when signing in to run ElasticSearch, you can use the following command to auto-generate a new password for it:
elasticsearch-setup-passwords autoRun the above command in ElasticSearch installation directory.
Test Elasticsearch:
Open a web browser and access the Elasticsearch REST API at 'http://localhost:9200'. You should see a JSON response indicating that Elasticsearch is running. The response would be as follows:
Additional Configuration (Optional):
Depending on your use case, you may need to further configure Elasticsearch for security, index settings, and more. Refer to the Elasticsearch documentation for advanced configurations.
Install Elasticsearch Plugins (Optional):
Elasticsearch supports plugins that provide additional functionality. You can install plugins as needed by following the Elasticsearch plugin installation instructions.
Index Data:
To work with data in Elasticsearch, you'll need to create an index and index documents. You can use tools like Kibana or Elasticsearch's REST API to index and query data.
Monitor and Manage:
Use Elasticsearch monitoring and management tools to monitor the health and performance of your Elasticsearch server.
Security (Important):
For production use, ensure that you have proper security measures, including authentication, access control, and encryption, to protect your Elasticsearch cluster.
from elasticsearch import Elasticsearch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Initialize Elasticsearch client
es = Elasticsearch(['http://locahost:9200'])
es.indices.create(index='my-index', ignore=400)
# Function to retrieve documents from Elasticsearch
def retrieve_documents(query, index="your_index", num_docs=3):
response = es.search(index=index, query={"match": {"content": query}}, size=num_docs)
return [doc['_source']['content'] for doc in response['hits']['hits']]
# Initialize GPT-2 Model and Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# Process user input and retrieve documents
user_query = "What is the capital of France?"
retrieved_docs = retrieve_documents(user_query)
extended_context = user_query + " " + " ".join(retrieved_docs)
# Generate response with GPT-2
inputs = tokenizer.encode(extended_context, return_tensors="pt")
output = model.generate(inputs, max_length=100, num_return_sequences=1)
response = tokenizer.decode(output[0], skip_special_tokens=True)
print(response)In this example, Elasticsearch retrieves relevant documents based on a user query. These documents and the original query are fed into GPT-2 to generate a response. This approach mimics the RAG model's functionality by combining retrieval and generation but with separate systems for each task. Remember, this is a basic illustration, and actual implementations in production environments would require more sophisticated handling and optimization.
Python Code Snippet:
RAG in Action: Coding Examples
Implementing a Retrieval-Augmented Generation (RAG) model can be complex. Still, the following pseudocode and Python code snippet using Hugging Face's Transformers library provide a basic illustration of how RAG can be implemented.
Pseudocode for RAG Implementation:
Load Pre-Trained Models:
Load a pre-trained seq2seq model (e.g., BART, T5) for language generation.
Load a pre-trained retriever model (e.g., DPR) for information retrieval.
Process User Input:
Receive an input query or prompt from the user.
Retrieve Relevant Information:
Use the retriever model to fetch relevant documents or information snippets based on the user input.
Rank and select the top documents based on relevance.
Generate Response with Context:
Combine the user input and retrieved documents to form an extended context.
Use the seq2seq model to generate a response based on this comprehensive context.
Output the Response:
Present the generated response to the user.
Python Code Snippet Using Hugging Face's Transformer:
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration, RagSequenceForGeneration
# Initialize tokenizer and models
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
# Process user input
input_query = "What is the capital of France?"
input_ids = tokenizer(input_query, return_tensors="pt").input_ids
# Generate response
generated_ids = model.generate(input_ids)
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Generated response: {generated_text}")The above code includes initializing the tokenizer and models, processing the user input, and then generating a response using the RAG model. The model combines the generative capabilities of a seq2seq model with the information retrieval features of the retriever to generate informed responses.
Integrating Elasticsearch and GPT-2 for RAG-like Functionality:
Another approach to implementing a basic version of Retrieval-Augmented Generation (RAG) functionality, besides using Hugging Face's Transformers library, involves combining separate components for retrieval and generation. For generation, you can use Elasticsearch for information retrieval and a pre-trained language model like GPT-2 from OpenAI. Here's a simplified example:
Pseudocode:
Set Up Elasticsearch for Document Retrieval:
Index a set of documents in Elasticsearch.
When a query is received, search Elasticsearch for the most relevant documents.
Use GPT-2 for Text Generation:
Load a pre-trained GPT-2 model.
Combine the user query with retrieved documents to form an extended context.
Generate a response based on this comprehensive context.
Combine Both for RAG-like Functionality:
Process user input to formulate a query.
Retrieve relevant information from Elasticsearch.
Use the retrieved data and the user query as input to GPT-2 to generate a response.
Python Code Snippet:
This example requires an Elasticsearch server and the Elasticsearch and Transformers Python packages. You need to download and install ElasticSearch before performing the task. Below are the basic steps to start with a single-node Elasticsearch server for testing or development purposes. Consider consulting Elasticsearch documentation or seeking professional assistance for production use or more complex setups.
System Requirements:
Ensure that you have a suitable server or virtual machine to host Elasticsearch. Elasticsearch requires a minimum amount of RAM and CPU power. Refer to the Elasticsearch documentation for specific system requirements.
Install Java:
Elasticsearch is built on Java, so you must install a compatible version of Java on your server. Elasticsearch typically works with OpenJDK or Oracle JDK. Install Java based on your operating system's instructions.
Download Elasticsearch:
Visit the Elasticsearch download page (https://www.elastic.co/downloads/elasticsearch) and download the Elasticsearch distribution that matches your operating system.
Install Elasticsearch:
Extract the downloaded Elasticsearch archive to a directory on your server. You can use tools like tar (Linux) or unzip (Windows).
Configure Elasticsearch:
Navigate to the config directory within the Elasticsearch installation directory. Open the elasticsearch.yml configuration file.
Configure Elasticsearch settings as needed. Standard configurations include specifying cluster and node names, network settings, and data paths.
Start Elasticsearch:
In the Elasticsearch installation directory, run the following command to start Elasticsearch:
elasticsearchMoreover, don’t forget to add its path to environment variables. Elasticsearch should now be running on your server.
Note: If you face an error when signing in to run ElasticSearch, you can use the following command to auto-generate a new password for it:
elasticsearch-setup-passwords autoRun the above command in ElasticSearch installation directory.
Test Elasticsearch:
Open a web browser and access the Elasticsearch REST API at 'http://localhost:9200'. You should see a JSON response indicating that Elasticsearch is running. The response would be as follows:
Additional Configuration (Optional):
Depending on your use case, you may need to further configure Elasticsearch for security, index settings, and more. Refer to the Elasticsearch documentation for advanced configurations.
Install Elasticsearch Plugins (Optional):
Elasticsearch supports plugins that provide additional functionality. You can install plugins as needed by following the Elasticsearch plugin installation instructions.
Index Data:
To work with data in Elasticsearch, you'll need to create an index and index documents. You can use tools like Kibana or Elasticsearch's REST API to index and query data.
Monitor and Manage:
Use Elasticsearch monitoring and management tools to monitor the health and performance of your Elasticsearch server.
Security (Important):
For production use, ensure that you have proper security measures, including authentication, access control, and encryption, to protect your Elasticsearch cluster.
from elasticsearch import Elasticsearch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Initialize Elasticsearch client
es = Elasticsearch(['http://locahost:9200'])
es.indices.create(index='my-index', ignore=400)
# Function to retrieve documents from Elasticsearch
def retrieve_documents(query, index="your_index", num_docs=3):
response = es.search(index=index, query={"match": {"content": query}}, size=num_docs)
return [doc['_source']['content'] for doc in response['hits']['hits']]
# Initialize GPT-2 Model and Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# Process user input and retrieve documents
user_query = "What is the capital of France?"
retrieved_docs = retrieve_documents(user_query)
extended_context = user_query + " " + " ".join(retrieved_docs)
# Generate response with GPT-2
inputs = tokenizer.encode(extended_context, return_tensors="pt")
output = model.generate(inputs, max_length=100, num_return_sequences=1)
response = tokenizer.decode(output[0], skip_special_tokens=True)
print(response)In this example, Elasticsearch retrieves relevant documents based on a user query. These documents and the original query are fed into GPT-2 to generate a response. This approach mimics the RAG model's functionality by combining retrieval and generation but with separate systems for each task. Remember, this is a basic illustration, and actual implementations in production environments would require more sophisticated handling and optimization.
Python Code Snippet:
Future Directions in Retrieval-Augmented Generation
Enhanced Model Efficiency:
Future advancements in RAG may focus on improving computational efficiency, allowing these models to operate faster and with less resource consumption. This could involve optimizing the retrieval process or refining the model architecture.
Advanced Contextual Understanding:
Ongoing research will likely enhance the contextual understanding of RAG models. This involves better integrating retrieved information with the generative process, allowing for more nuanced and contextually rich responses.
Expansion of Knowledge Bases:
Future RAG models may leverage more diverse and expansive knowledge bases, moving beyond text to include multimedia content like images and videos, thereby enriching the scope of their responses.
Improved Handling of Ambiguity and Contradictions:
Advancements may focus on how RAG models handle ambiguous queries and contradictory information, ensuring more reliable and accurate outputs even in complex scenarios.
Personalization and User Adaptation:
Future iterations incorporate user-specific adaptation, where the model learns and tailor its responses based on individual user interactions and preferences.
Future Directions in Retrieval-Augmented Generation
Enhanced Model Efficiency:
Future advancements in RAG may focus on improving computational efficiency, allowing these models to operate faster and with less resource consumption. This could involve optimizing the retrieval process or refining the model architecture.
Advanced Contextual Understanding:
Ongoing research will likely enhance the contextual understanding of RAG models. This involves better integrating retrieved information with the generative process, allowing for more nuanced and contextually rich responses.
Expansion of Knowledge Bases:
Future RAG models may leverage more diverse and expansive knowledge bases, moving beyond text to include multimedia content like images and videos, thereby enriching the scope of their responses.
Improved Handling of Ambiguity and Contradictions:
Advancements may focus on how RAG models handle ambiguous queries and contradictory information, ensuring more reliable and accurate outputs even in complex scenarios.
Personalization and User Adaptation:
Future iterations incorporate user-specific adaptation, where the model learns and tailor its responses based on individual user interactions and preferences.
Future Directions in Retrieval-Augmented Generation
Enhanced Model Efficiency:
Future advancements in RAG may focus on improving computational efficiency, allowing these models to operate faster and with less resource consumption. This could involve optimizing the retrieval process or refining the model architecture.
Advanced Contextual Understanding:
Ongoing research will likely enhance the contextual understanding of RAG models. This involves better integrating retrieved information with the generative process, allowing for more nuanced and contextually rich responses.
Expansion of Knowledge Bases:
Future RAG models may leverage more diverse and expansive knowledge bases, moving beyond text to include multimedia content like images and videos, thereby enriching the scope of their responses.
Improved Handling of Ambiguity and Contradictions:
Advancements may focus on how RAG models handle ambiguous queries and contradictory information, ensuring more reliable and accurate outputs even in complex scenarios.
Personalization and User Adaptation:
Future iterations incorporate user-specific adaptation, where the model learns and tailor its responses based on individual user interactions and preferences.
Future Directions in Retrieval-Augmented Generation
Enhanced Model Efficiency:
Future advancements in RAG may focus on improving computational efficiency, allowing these models to operate faster and with less resource consumption. This could involve optimizing the retrieval process or refining the model architecture.
Advanced Contextual Understanding:
Ongoing research will likely enhance the contextual understanding of RAG models. This involves better integrating retrieved information with the generative process, allowing for more nuanced and contextually rich responses.
Expansion of Knowledge Bases:
Future RAG models may leverage more diverse and expansive knowledge bases, moving beyond text to include multimedia content like images and videos, thereby enriching the scope of their responses.
Improved Handling of Ambiguity and Contradictions:
Advancements may focus on how RAG models handle ambiguous queries and contradictory information, ensuring more reliable and accurate outputs even in complex scenarios.
Personalization and User Adaptation:
Future iterations incorporate user-specific adaptation, where the model learns and tailor its responses based on individual user interactions and preferences.
Conclusion
In summary, Retrieval-Augmented Generation, or RAG, marks a significant advancement in how computers understand and use language. It combines traditional language models with the ability to search for information on the spot, making the responses it generates relevant, rich in detail and accurate. This technology is already promising in areas like customer service and research, helping provide quick and accurate information. However, challenges include the need for much computing power and the complexity of combining these systems. As we move forward, we expect RAG to become more efficient, user-friendly, and adaptable to different languages and cultural contexts. The development of RAG is more than just a technical achievement; it's a step towards creating more intelligent systems that can change how we interact with information and technology.
Conclusion
In summary, Retrieval-Augmented Generation, or RAG, marks a significant advancement in how computers understand and use language. It combines traditional language models with the ability to search for information on the spot, making the responses it generates relevant, rich in detail and accurate. This technology is already promising in areas like customer service and research, helping provide quick and accurate information. However, challenges include the need for much computing power and the complexity of combining these systems. As we move forward, we expect RAG to become more efficient, user-friendly, and adaptable to different languages and cultural contexts. The development of RAG is more than just a technical achievement; it's a step towards creating more intelligent systems that can change how we interact with information and technology.
Conclusion
In summary, Retrieval-Augmented Generation, or RAG, marks a significant advancement in how computers understand and use language. It combines traditional language models with the ability to search for information on the spot, making the responses it generates relevant, rich in detail and accurate. This technology is already promising in areas like customer service and research, helping provide quick and accurate information. However, challenges include the need for much computing power and the complexity of combining these systems. As we move forward, we expect RAG to become more efficient, user-friendly, and adaptable to different languages and cultural contexts. The development of RAG is more than just a technical achievement; it's a step towards creating more intelligent systems that can change how we interact with information and technology.
Conclusion
In summary, Retrieval-Augmented Generation, or RAG, marks a significant advancement in how computers understand and use language. It combines traditional language models with the ability to search for information on the spot, making the responses it generates relevant, rich in detail and accurate. This technology is already promising in areas like customer service and research, helping provide quick and accurate information. However, challenges include the need for much computing power and the complexity of combining these systems. As we move forward, we expect RAG to become more efficient, user-friendly, and adaptable to different languages and cultural contexts. The development of RAG is more than just a technical achievement; it's a step towards creating more intelligent systems that can change how we interact with information and technology.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.