Annotab Studio 2.0.0 is now live
Data Splitting: The Secret Key for Accurate AI Models
Data Splitting: The Secret Key for Accurate AI Models
Data Splitting: The Secret Key for Accurate AI Models
Data Splitting: The Secret Key for Accurate AI Models
Published by

Dao Pham
on
Nov 10, 2023
under
Machine Learning
Published by
Dao Pham
on
Nov 10, 2023
under
Machine Learning
Published by
Dao Pham
on
Nov 10, 2023
under
Machine Learning
Published by
Dao Pham
on
Nov 10, 2023
under
Machine Learning
ON THIS PAGE
Tl;dr
In the realm of data science, meticulous data splitting not only validates a model's prowess but serves as a compass towards optimal performance. In this article, let's dive deep into data splitting.
Tl;dr
In the realm of data science, meticulous data splitting not only validates a model's prowess but serves as a compass towards optimal performance. In this article, let's dive deep into data splitting.
Tl;dr
In the realm of data science, meticulous data splitting not only validates a model's prowess but serves as a compass towards optimal performance. In this article, let's dive deep into data splitting.
Tl;dr
In the realm of data science, meticulous data splitting not only validates a model's prowess but serves as a compass towards optimal performance. In this article, let's dive deep into data splitting.

Introduction
In the AI field, data splitting is a fundamental step that often goes unnoticed but plays a pivotal role in the model's propriety and performance. In this scenario, we'll delve into the importance of data splitting and explore the practices for mastering this essential aspect.
Introduction
In the AI field, data splitting is a fundamental step that often goes unnoticed but plays a pivotal role in the model's propriety and performance. In this scenario, we'll delve into the importance of data splitting and explore the practices for mastering this essential aspect.
Introduction
In the AI field, data splitting is a fundamental step that often goes unnoticed but plays a pivotal role in the model's propriety and performance. In this scenario, we'll delve into the importance of data splitting and explore the practices for mastering this essential aspect.
Introduction
In the AI field, data splitting is a fundamental step that often goes unnoticed but plays a pivotal role in the model's propriety and performance. In this scenario, we'll delve into the importance of data splitting and explore the practices for mastering this essential aspect.
What is data splitting?
Data splitting is the practice of dividing a dataset into n main subsets (the number n is based on your purpose). The popular and recommended of n is 3. In this case we have 3 subsets: The training set, the validation set, and the testing set. Each of these sets serves a distinct purpose in the model development process. Now, let’s explore!

Figure 1: Visualization for training, validation and testing set
Each set consists of a collection of data points, often referred to as observations or samples, which typically include both input data and their corresponding output or target values.
Training set
This is the largest portion of a dataset. It is a subset used to train an AI model, meaning the model is fed data to learn its patterns.
The quality and representativeness of the training set are crucial for the success of an AI model. A well-constructed training set should encompass a wide range of observations and cover various scenarios in the dataset. This helps the model free from biases that could adversely affect the model's learning process and performance.
Validation set
This subset is reserved for model evaluation and is not used in training. It allows us to assess the model's performance on unseen data, helping identify potential issues such as underfitting, overfitting or aligning with our goals. Additionally, decisions based on the model's capabilities are crucial:
Model selection: Selecting the optimal combination of hyperparameters that yield the best performance according to your specified metric (such as accuracy, F1-score, or lowest loss) on the validation set. This metric is aligned with your specific criteria.
Early stopping:
+ Early stopping refers to halting the training of a machine learning model under certain conditions.
+ Typically, the loss in the validation set serves as the criterion for early stopping, assessing the model's performance on a validation dataset. Training concludes when the validation loss ceases to improve.
+ For instance, if the loss begins to increase on the validation set and continues to rise for a specified number of epochs (denoted as 'x,' where 'x' is the patience—a hyperparameter determining how long training persists without improvement in the validation metric before triggering early stopping).
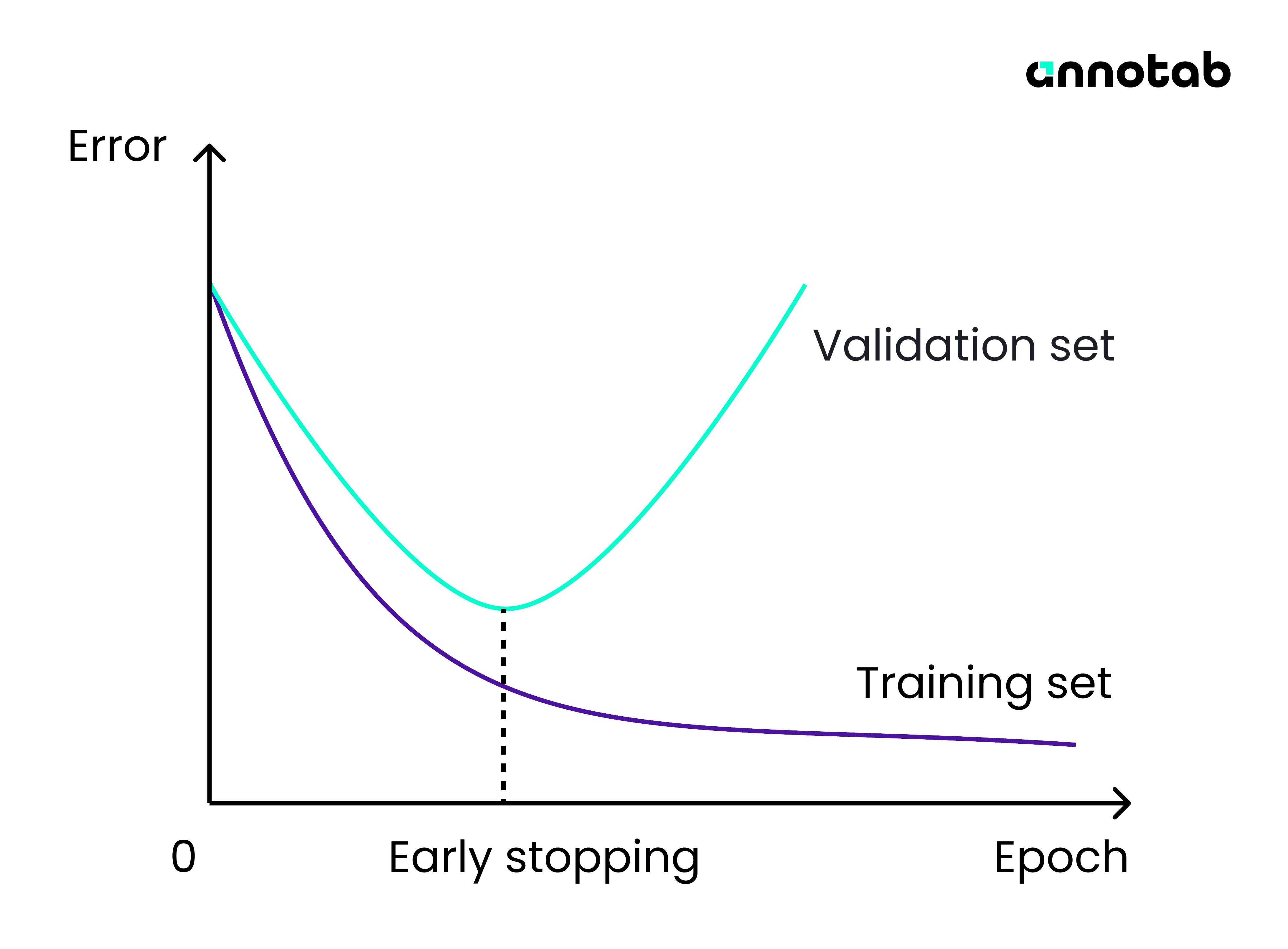
Figure 2: Training and Validation Curves based on loss
This visualization illustrates the model's performance, as measured by the loss function, on both the training and validation datasets across epochs. Analyzing these curves aids in identifying optimal points to trigger early stopping during the training process.
Test set
Once the training process, utilizing the training set, has led to the selection of the best-performing model on the validation set, the testing set—representative of real-world data expectations—is employed for final evaluation. This step assesses the model's ability to generalize to unseen data, providing a crucial measure of its performance in practical scenarios. Additionally, the testing set serves as the benchmark for comparing the performance of different models or algorithms, aiding in the determination of the most suitable approach for your specific task.
What is data splitting?
Data splitting is the practice of dividing a dataset into n main subsets (the number n is based on your purpose). The popular and recommended of n is 3. In this case we have 3 subsets: The training set, the validation set, and the testing set. Each of these sets serves a distinct purpose in the model development process. Now, let’s explore!
Figure 1: Visualization for training, validation and testing set
Each set consists of a collection of data points, often referred to as observations or samples, which typically include both input data and their corresponding output or target values.
Training set
This is the largest portion of a dataset. It is a subset used to train an AI model, meaning the model is fed data to learn its patterns.
The quality and representativeness of the training set are crucial for the success of an AI model. A well-constructed training set should encompass a wide range of observations and cover various scenarios in the dataset. This helps the model free from biases that could adversely affect the model's learning process and performance.
Validation set
This subset is reserved for model evaluation and is not used in training. It allows us to assess the model's performance on unseen data, helping identify potential issues such as underfitting, overfitting or aligning with our goals. Additionally, decisions based on the model's capabilities are crucial:
Model selection: Selecting the optimal combination of hyperparameters that yield the best performance according to your specified metric (such as accuracy, F1-score, or lowest loss) on the validation set. This metric is aligned with your specific criteria.
Early stopping:
+ Early stopping refers to halting the training of a machine learning model under certain conditions.
+ Typically, the loss in the validation set serves as the criterion for early stopping, assessing the model's performance on a validation dataset. Training concludes when the validation loss ceases to improve.
+ For instance, if the loss begins to increase on the validation set and continues to rise for a specified number of epochs (denoted as 'x,' where 'x' is the patience—a hyperparameter determining how long training persists without improvement in the validation metric before triggering early stopping).
Figure 2: Training and Validation Curves based on loss
This visualization illustrates the model's performance, as measured by the loss function, on both the training and validation datasets across epochs. Analyzing these curves aids in identifying optimal points to trigger early stopping during the training process.
Test set
Once the training process, utilizing the training set, has led to the selection of the best-performing model on the validation set, the testing set—representative of real-world data expectations—is employed for final evaluation. This step assesses the model's ability to generalize to unseen data, providing a crucial measure of its performance in practical scenarios. Additionally, the testing set serves as the benchmark for comparing the performance of different models or algorithms, aiding in the determination of the most suitable approach for your specific task.
What is data splitting?
Data splitting is the practice of dividing a dataset into n main subsets (the number n is based on your purpose). The popular and recommended of n is 3. In this case we have 3 subsets: The training set, the validation set, and the testing set. Each of these sets serves a distinct purpose in the model development process. Now, let’s explore!
Figure 1: Visualization for training, validation and testing set
Each set consists of a collection of data points, often referred to as observations or samples, which typically include both input data and their corresponding output or target values.
Training set
This is the largest portion of a dataset. It is a subset used to train an AI model, meaning the model is fed data to learn its patterns.
The quality and representativeness of the training set are crucial for the success of an AI model. A well-constructed training set should encompass a wide range of observations and cover various scenarios in the dataset. This helps the model free from biases that could adversely affect the model's learning process and performance.
Validation set
This subset is reserved for model evaluation and is not used in training. It allows us to assess the model's performance on unseen data, helping identify potential issues such as underfitting, overfitting or aligning with our goals. Additionally, decisions based on the model's capabilities are crucial:
Model selection: Selecting the optimal combination of hyperparameters that yield the best performance according to your specified metric (such as accuracy, F1-score, or lowest loss) on the validation set. This metric is aligned with your specific criteria.
Early stopping:
+ Early stopping refers to halting the training of a machine learning model under certain conditions.
+ Typically, the loss in the validation set serves as the criterion for early stopping, assessing the model's performance on a validation dataset. Training concludes when the validation loss ceases to improve.
+ For instance, if the loss begins to increase on the validation set and continues to rise for a specified number of epochs (denoted as 'x,' where 'x' is the patience—a hyperparameter determining how long training persists without improvement in the validation metric before triggering early stopping).
Figure 2: Training and Validation Curves based on loss
This visualization illustrates the model's performance, as measured by the loss function, on both the training and validation datasets across epochs. Analyzing these curves aids in identifying optimal points to trigger early stopping during the training process.
Test set
Once the training process, utilizing the training set, has led to the selection of the best-performing model on the validation set, the testing set—representative of real-world data expectations—is employed for final evaluation. This step assesses the model's ability to generalize to unseen data, providing a crucial measure of its performance in practical scenarios. Additionally, the testing set serves as the benchmark for comparing the performance of different models or algorithms, aiding in the determination of the most suitable approach for your specific task.
What is data splitting?
Data splitting is the practice of dividing a dataset into n main subsets (the number n is based on your purpose). The popular and recommended of n is 3. In this case we have 3 subsets: The training set, the validation set, and the testing set. Each of these sets serves a distinct purpose in the model development process. Now, let’s explore!
Figure 1: Visualization for training, validation and testing set
Each set consists of a collection of data points, often referred to as observations or samples, which typically include both input data and their corresponding output or target values.
Training set
This is the largest portion of a dataset. It is a subset used to train an AI model, meaning the model is fed data to learn its patterns.
The quality and representativeness of the training set are crucial for the success of an AI model. A well-constructed training set should encompass a wide range of observations and cover various scenarios in the dataset. This helps the model free from biases that could adversely affect the model's learning process and performance.
Validation set
This subset is reserved for model evaluation and is not used in training. It allows us to assess the model's performance on unseen data, helping identify potential issues such as underfitting, overfitting or aligning with our goals. Additionally, decisions based on the model's capabilities are crucial:
Model selection: Selecting the optimal combination of hyperparameters that yield the best performance according to your specified metric (such as accuracy, F1-score, or lowest loss) on the validation set. This metric is aligned with your specific criteria.
Early stopping:
+ Early stopping refers to halting the training of a machine learning model under certain conditions.
+ Typically, the loss in the validation set serves as the criterion for early stopping, assessing the model's performance on a validation dataset. Training concludes when the validation loss ceases to improve.
+ For instance, if the loss begins to increase on the validation set and continues to rise for a specified number of epochs (denoted as 'x,' where 'x' is the patience—a hyperparameter determining how long training persists without improvement in the validation metric before triggering early stopping).
Figure 2: Training and Validation Curves based on loss
This visualization illustrates the model's performance, as measured by the loss function, on both the training and validation datasets across epochs. Analyzing these curves aids in identifying optimal points to trigger early stopping during the training process.
Test set
Once the training process, utilizing the training set, has led to the selection of the best-performing model on the validation set, the testing set—representative of real-world data expectations—is employed for final evaluation. This step assesses the model's ability to generalize to unseen data, providing a crucial measure of its performance in practical scenarios. Additionally, the testing set serves as the benchmark for comparing the performance of different models or algorithms, aiding in the determination of the most suitable approach for your specific task.
How to split the dataset correctly?
To ensure accuracy in data splitting, two fundamental principles must be remembered: Same Distribution and No Leakage. Now let's discuss in details.
Same Distribution
Ensuring the same distribution across the training, validation, and testing sets is the primary requirement. This means that the data in all three sets should be representative of the same population or source, with similar statistical properties. Maintaining the same distribution is critical because any AI model is designed to learn patterns from the training data. If the distributions differ, the model may struggle to generalize well to validation and testing data, leading to poor real-world performance.
For instance, using an example of predicting flowers, if image resolutions vary significantly between subsets, the model's performance may be compromised. Common solutions in this scenario include:
- Mixing and shuffling data from 3 subsets and splitting them into 3 subsets. Note that the ratio of high-resolution to low-resolution images in the three subsets should be the same (It's not necessary to be precise in the ratio, but it should be closed or nearly closed).
Let's now consider a numerical example in this case:
+ Initially, you have 110,000 high-resolution flower images in the training set and 11,000 low-resolution flower images in the validation and testing sets, with each set containing an equal number of images (5,500 in the validation set and 5,500 in the testing set). The ratio of train-validation-testing is 10:0.5:0.5.
+ After shuffling them and following the ratio mentioned above, you can split them as follows:
Training set: 100000 high-solution images and 10000 low-solution images
Validation set: 5000 high-solution images and 500 low-solution images
Test set: 5000 high-solution images and 500 low-solution images
- Consider finding a way to improve the quality of images in the validation and testing sets or reduce the quality of images in the training set. The decision is up to you.
Another funny example: You can not use the dog detector for detecting cats. Why? Just because the data patterns for dogs and cats are dissimilar! (Difference in distribution).
No leakage
Preventing data leakage is vital for accurate model assessment. Leakage occurs when information from the training set is inappropriately included in validation or testing sets, skewing performance metrics. Common scenarios include leakage via feature engineering or target leakage:
Data leakage via Feature Engineering: Feature engineering involves creating new features or transforming existing ones to improve model performance. Suppose feature engineering is done on the entire dataset (including both the training, validation, and testing sets) before splitting them. In that case, the model may inadvertently learn information from the validation and testing set, leading to leakage. So, make sure the pre-process step or feature engineering is done in the training set first, and then do the same in the validation and testing set.
Target leakage occurs when information from the target variable (the variable you're trying to predict) is used to engineer features or some tasks during the training phase. This can lead to a model that appears highly accurate during training but fails to predict well on new data.
How to split the dataset correctly?
To ensure accuracy in data splitting, two fundamental principles must be remembered: Same Distribution and No Leakage. Now let's discuss in details.
Same Distribution
Ensuring the same distribution across the training, validation, and testing sets is the primary requirement. This means that the data in all three sets should be representative of the same population or source, with similar statistical properties. Maintaining the same distribution is critical because any AI model is designed to learn patterns from the training data. If the distributions differ, the model may struggle to generalize well to validation and testing data, leading to poor real-world performance.
For instance, using an example of predicting flowers, if image resolutions vary significantly between subsets, the model's performance may be compromised. Common solutions in this scenario include:
- Mixing and shuffling data from 3 subsets and splitting them into 3 subsets. Note that the ratio of high-resolution to low-resolution images in the three subsets should be the same (It's not necessary to be precise in the ratio, but it should be closed or nearly closed).
Let's now consider a numerical example in this case:
+ Initially, you have 110,000 high-resolution flower images in the training set and 11,000 low-resolution flower images in the validation and testing sets, with each set containing an equal number of images (5,500 in the validation set and 5,500 in the testing set). The ratio of train-validation-testing is 10:0.5:0.5.
+ After shuffling them and following the ratio mentioned above, you can split them as follows:
Training set: 100000 high-solution images and 10000 low-solution images
Validation set: 5000 high-solution images and 500 low-solution images
Test set: 5000 high-solution images and 500 low-solution images
- Consider finding a way to improve the quality of images in the validation and testing sets or reduce the quality of images in the training set. The decision is up to you.
Another funny example: You can not use the dog detector for detecting cats. Why? Just because the data patterns for dogs and cats are dissimilar! (Difference in distribution).
No leakage
Preventing data leakage is vital for accurate model assessment. Leakage occurs when information from the training set is inappropriately included in validation or testing sets, skewing performance metrics. Common scenarios include leakage via feature engineering or target leakage:
Data leakage via Feature Engineering: Feature engineering involves creating new features or transforming existing ones to improve model performance. Suppose feature engineering is done on the entire dataset (including both the training, validation, and testing sets) before splitting them. In that case, the model may inadvertently learn information from the validation and testing set, leading to leakage. So, make sure the pre-process step or feature engineering is done in the training set first, and then do the same in the validation and testing set.
Target leakage occurs when information from the target variable (the variable you're trying to predict) is used to engineer features or some tasks during the training phase. This can lead to a model that appears highly accurate during training but fails to predict well on new data.
How to split the dataset correctly?
To ensure accuracy in data splitting, two fundamental principles must be remembered: Same Distribution and No Leakage. Now let's discuss in details.
Same Distribution
Ensuring the same distribution across the training, validation, and testing sets is the primary requirement. This means that the data in all three sets should be representative of the same population or source, with similar statistical properties. Maintaining the same distribution is critical because any AI model is designed to learn patterns from the training data. If the distributions differ, the model may struggle to generalize well to validation and testing data, leading to poor real-world performance.
For instance, using an example of predicting flowers, if image resolutions vary significantly between subsets, the model's performance may be compromised. Common solutions in this scenario include:
- Mixing and shuffling data from 3 subsets and splitting them into 3 subsets. Note that the ratio of high-resolution to low-resolution images in the three subsets should be the same (It's not necessary to be precise in the ratio, but it should be closed or nearly closed).
Let's now consider a numerical example in this case:
+ Initially, you have 110,000 high-resolution flower images in the training set and 11,000 low-resolution flower images in the validation and testing sets, with each set containing an equal number of images (5,500 in the validation set and 5,500 in the testing set). The ratio of train-validation-testing is 10:0.5:0.5.
+ After shuffling them and following the ratio mentioned above, you can split them as follows:
Training set: 100000 high-solution images and 10000 low-solution images
Validation set: 5000 high-solution images and 500 low-solution images
Test set: 5000 high-solution images and 500 low-solution images
- Consider finding a way to improve the quality of images in the validation and testing sets or reduce the quality of images in the training set. The decision is up to you.
Another funny example: You can not use the dog detector for detecting cats. Why? Just because the data patterns for dogs and cats are dissimilar! (Difference in distribution).
No leakage
Preventing data leakage is vital for accurate model assessment. Leakage occurs when information from the training set is inappropriately included in validation or testing sets, skewing performance metrics. Common scenarios include leakage via feature engineering or target leakage:
Data leakage via Feature Engineering: Feature engineering involves creating new features or transforming existing ones to improve model performance. Suppose feature engineering is done on the entire dataset (including both the training, validation, and testing sets) before splitting them. In that case, the model may inadvertently learn information from the validation and testing set, leading to leakage. So, make sure the pre-process step or feature engineering is done in the training set first, and then do the same in the validation and testing set.
Target leakage occurs when information from the target variable (the variable you're trying to predict) is used to engineer features or some tasks during the training phase. This can lead to a model that appears highly accurate during training but fails to predict well on new data.
How to split the dataset correctly?
To ensure accuracy in data splitting, two fundamental principles must be remembered: Same Distribution and No Leakage. Now let's discuss in details.
Same Distribution
Ensuring the same distribution across the training, validation, and testing sets is the primary requirement. This means that the data in all three sets should be representative of the same population or source, with similar statistical properties. Maintaining the same distribution is critical because any AI model is designed to learn patterns from the training data. If the distributions differ, the model may struggle to generalize well to validation and testing data, leading to poor real-world performance.
For instance, using an example of predicting flowers, if image resolutions vary significantly between subsets, the model's performance may be compromised. Common solutions in this scenario include:
- Mixing and shuffling data from 3 subsets and splitting them into 3 subsets. Note that the ratio of high-resolution to low-resolution images in the three subsets should be the same (It's not necessary to be precise in the ratio, but it should be closed or nearly closed).
Let's now consider a numerical example in this case:
+ Initially, you have 110,000 high-resolution flower images in the training set and 11,000 low-resolution flower images in the validation and testing sets, with each set containing an equal number of images (5,500 in the validation set and 5,500 in the testing set). The ratio of train-validation-testing is 10:0.5:0.5.
+ After shuffling them and following the ratio mentioned above, you can split them as follows:
Training set: 100000 high-solution images and 10000 low-solution images
Validation set: 5000 high-solution images and 500 low-solution images
Test set: 5000 high-solution images and 500 low-solution images
- Consider finding a way to improve the quality of images in the validation and testing sets or reduce the quality of images in the training set. The decision is up to you.
Another funny example: You can not use the dog detector for detecting cats. Why? Just because the data patterns for dogs and cats are dissimilar! (Difference in distribution).
No leakage
Preventing data leakage is vital for accurate model assessment. Leakage occurs when information from the training set is inappropriately included in validation or testing sets, skewing performance metrics. Common scenarios include leakage via feature engineering or target leakage:
Data leakage via Feature Engineering: Feature engineering involves creating new features or transforming existing ones to improve model performance. Suppose feature engineering is done on the entire dataset (including both the training, validation, and testing sets) before splitting them. In that case, the model may inadvertently learn information from the validation and testing set, leading to leakage. So, make sure the pre-process step or feature engineering is done in the training set first, and then do the same in the validation and testing set.
Target leakage occurs when information from the target variable (the variable you're trying to predict) is used to engineer features or some tasks during the training phase. This can lead to a model that appears highly accurate during training but fails to predict well on new data.
Data splitting in practice
In general, the first step is splitting the data into 2 subsets: train – test. And then, we get the validation set from splitting the training set into 2 subset: train – validation.
Random splitting
Random data splitting involves shuffling the entire dataset and then randomly dividing it into three subsets in a specified ratio. Let's delve into a detailed analysis of this method.
In cases where the dataset is balanced (the number of observations or samples in all classes is nearly equal or not significantly different), random splitting can work well. For example, if you have two classes with a ratio of x:y, when using random splitting to divide the entire dataset into n subsets, the ratio in each subset can vary slightly but not by a significant amount. Therefore, the distribution may not change significantly (compare with the original distribution) and can approximate equality among the n subsets.
In contrast, when dealing with imbalanced data (significant differences in the number of observations among classes), random splitting may not be suitable. This is particularly evident in the worst-case scenario, where the training set lacks examples of minority classes, adversely impacting model performance on those classes. Consider a dataset with 7000 dogs and 3000 cats, using a random splitting ratio of 7:1:2 (train-validation-test). The worst outcome could yield a training set exclusively comprising dogs (7000 dogs), while the validation and testing sets consist solely of cats (1000 cats in validation – 2000 cats in testing). Such a noticeable distribution difference can be problematic.To address this challenge, especially in imbalanced datasets, an alternative method known as Stratified Splitting can be employed.
Stratified Splitting
Stratified splitting is a vital technique, especially when dealing with imbalanced datasets. This method ensures that the distribution of classes in each subset mirrors the original distribution, preserving the ratio among all classes during the data division process.
Process:
Shuffling: Commence by shuffling the entire dataset.
Splitting: Divide the shuffled data into n subsets, with each subset maintaining the original ratio among all classes.
Example: Dog-Cat Dataset
Original Dog-Cat Ratio: 7:3
Train-Validation-Test Ratio: 7:1:2
Desired Stratified Ratio in Each Subset:
Divide 7000 dogs into 10 parts, each containing 700 dogs.
Divide 3000 cats into 10 parts, each containing 300 cats.
Resultant Distribution in Subsets:
Training Set: 7 parts of dogs and 7 parts of cats (4900 dogs, 2100 cats)
Validation Set: 1 part of dogs and 1 part of cats (700 dogs, 300 cats)
Testing Set: 2 parts of dogs and 2 parts of cats (1400 dogs, 600 cats)
Stratified splitting ensures that each subset maintains the original class ratio, allowing the model to learn effectively from all classes, even those with fewer examples.
K-fold cross validation
K-fold cross-validation is particularly useful in situations where you have a limited amount of data, as it allows you to make the most out of your dataset by using it for both training and validation in multiple iterations. It helps reduce the bias that may arise from a single train-test split and provides a more comprehensive assessment of how well the model generalizes to different subsets of the data.

Figure 3. Illustration of the k-fold splitting process
The basic idea is to divide the dataset into k subsets, or k folds. The model is then trained on k-1 of these folds and validated on the remaining one. This process is repeated k times, each time using a different fold as the validation set and the remaining folds as the training set. In each iteration, we have a trained model and evaluate it on the validation set. The model’s performance (such as accuracy, precision, recall, …) is estimated by averaging over the k iterations.
K-Fold Cross-Validation not only offers a truthful evaluation method but also serves as a powerful tool for fine-tuning. By experimenting with different parameter combinations across the k models, one can identify the optimal model that performs best on the testing set. This selected model then becomes the final choice for real-world applications, ensuring robust performance in diverse scenarios.
In wrapping up, the art of data splitting is pivotal for shaping resilient machine learning models. Whether through random or stratified methods, or the iterative precision of K-Fold Cross-Validation, the chosen approach profoundly impacts a model's adaptability to new data.
Data splitting in practice
In general, the first step is splitting the data into 2 subsets: train – test. And then, we get the validation set from splitting the training set into 2 subset: train – validation.
Random splitting
Random data splitting involves shuffling the entire dataset and then randomly dividing it into three subsets in a specified ratio. Let's delve into a detailed analysis of this method.
In cases where the dataset is balanced (the number of observations or samples in all classes is nearly equal or not significantly different), random splitting can work well. For example, if you have two classes with a ratio of x:y, when using random splitting to divide the entire dataset into n subsets, the ratio in each subset can vary slightly but not by a significant amount. Therefore, the distribution may not change significantly (compare with the original distribution) and can approximate equality among the n subsets.
In contrast, when dealing with imbalanced data (significant differences in the number of observations among classes), random splitting may not be suitable. This is particularly evident in the worst-case scenario, where the training set lacks examples of minority classes, adversely impacting model performance on those classes. Consider a dataset with 7000 dogs and 3000 cats, using a random splitting ratio of 7:1:2 (train-validation-test). The worst outcome could yield a training set exclusively comprising dogs (7000 dogs), while the validation and testing sets consist solely of cats (1000 cats in validation – 2000 cats in testing). Such a noticeable distribution difference can be problematic.To address this challenge, especially in imbalanced datasets, an alternative method known as Stratified Splitting can be employed.
Stratified Splitting
Stratified splitting is a vital technique, especially when dealing with imbalanced datasets. This method ensures that the distribution of classes in each subset mirrors the original distribution, preserving the ratio among all classes during the data division process.
Process:
Shuffling: Commence by shuffling the entire dataset.
Splitting: Divide the shuffled data into n subsets, with each subset maintaining the original ratio among all classes.
Example: Dog-Cat Dataset
Original Dog-Cat Ratio: 7:3
Train-Validation-Test Ratio: 7:1:2
Desired Stratified Ratio in Each Subset:
Divide 7000 dogs into 10 parts, each containing 700 dogs.
Divide 3000 cats into 10 parts, each containing 300 cats.
Resultant Distribution in Subsets:
Training Set: 7 parts of dogs and 7 parts of cats (4900 dogs, 2100 cats)
Validation Set: 1 part of dogs and 1 part of cats (700 dogs, 300 cats)
Testing Set: 2 parts of dogs and 2 parts of cats (1400 dogs, 600 cats)
Stratified splitting ensures that each subset maintains the original class ratio, allowing the model to learn effectively from all classes, even those with fewer examples.
K-fold cross validation
K-fold cross-validation is particularly useful in situations where you have a limited amount of data, as it allows you to make the most out of your dataset by using it for both training and validation in multiple iterations. It helps reduce the bias that may arise from a single train-test split and provides a more comprehensive assessment of how well the model generalizes to different subsets of the data.
Figure 3. Illustration of the k-fold splitting process
The basic idea is to divide the dataset into k subsets, or k folds. The model is then trained on k-1 of these folds and validated on the remaining one. This process is repeated k times, each time using a different fold as the validation set and the remaining folds as the training set. In each iteration, we have a trained model and evaluate it on the validation set. The model’s performance (such as accuracy, precision, recall, …) is estimated by averaging over the k iterations.
K-Fold Cross-Validation not only offers a truthful evaluation method but also serves as a powerful tool for fine-tuning. By experimenting with different parameter combinations across the k models, one can identify the optimal model that performs best on the testing set. This selected model then becomes the final choice for real-world applications, ensuring robust performance in diverse scenarios.
In wrapping up, the art of data splitting is pivotal for shaping resilient machine learning models. Whether through random or stratified methods, or the iterative precision of K-Fold Cross-Validation, the chosen approach profoundly impacts a model's adaptability to new data.
Data splitting in practice
In general, the first step is splitting the data into 2 subsets: train – test. And then, we get the validation set from splitting the training set into 2 subset: train – validation.
Random splitting
Random data splitting involves shuffling the entire dataset and then randomly dividing it into three subsets in a specified ratio. Let's delve into a detailed analysis of this method.
In cases where the dataset is balanced (the number of observations or samples in all classes is nearly equal or not significantly different), random splitting can work well. For example, if you have two classes with a ratio of x:y, when using random splitting to divide the entire dataset into n subsets, the ratio in each subset can vary slightly but not by a significant amount. Therefore, the distribution may not change significantly (compare with the original distribution) and can approximate equality among the n subsets.
In contrast, when dealing with imbalanced data (significant differences in the number of observations among classes), random splitting may not be suitable. This is particularly evident in the worst-case scenario, where the training set lacks examples of minority classes, adversely impacting model performance on those classes. Consider a dataset with 7000 dogs and 3000 cats, using a random splitting ratio of 7:1:2 (train-validation-test). The worst outcome could yield a training set exclusively comprising dogs (7000 dogs), while the validation and testing sets consist solely of cats (1000 cats in validation – 2000 cats in testing). Such a noticeable distribution difference can be problematic.To address this challenge, especially in imbalanced datasets, an alternative method known as Stratified Splitting can be employed.
Stratified Splitting
Stratified splitting is a vital technique, especially when dealing with imbalanced datasets. This method ensures that the distribution of classes in each subset mirrors the original distribution, preserving the ratio among all classes during the data division process.
Process:
Shuffling: Commence by shuffling the entire dataset.
Splitting: Divide the shuffled data into n subsets, with each subset maintaining the original ratio among all classes.
Example: Dog-Cat Dataset
Original Dog-Cat Ratio: 7:3
Train-Validation-Test Ratio: 7:1:2
Desired Stratified Ratio in Each Subset:
Divide 7000 dogs into 10 parts, each containing 700 dogs.
Divide 3000 cats into 10 parts, each containing 300 cats.
Resultant Distribution in Subsets:
Training Set: 7 parts of dogs and 7 parts of cats (4900 dogs, 2100 cats)
Validation Set: 1 part of dogs and 1 part of cats (700 dogs, 300 cats)
Testing Set: 2 parts of dogs and 2 parts of cats (1400 dogs, 600 cats)
Stratified splitting ensures that each subset maintains the original class ratio, allowing the model to learn effectively from all classes, even those with fewer examples.
K-fold cross validation
K-fold cross-validation is particularly useful in situations where you have a limited amount of data, as it allows you to make the most out of your dataset by using it for both training and validation in multiple iterations. It helps reduce the bias that may arise from a single train-test split and provides a more comprehensive assessment of how well the model generalizes to different subsets of the data.
Figure 3. Illustration of the k-fold splitting process
The basic idea is to divide the dataset into k subsets, or k folds. The model is then trained on k-1 of these folds and validated on the remaining one. This process is repeated k times, each time using a different fold as the validation set and the remaining folds as the training set. In each iteration, we have a trained model and evaluate it on the validation set. The model’s performance (such as accuracy, precision, recall, …) is estimated by averaging over the k iterations.
K-Fold Cross-Validation not only offers a truthful evaluation method but also serves as a powerful tool for fine-tuning. By experimenting with different parameter combinations across the k models, one can identify the optimal model that performs best on the testing set. This selected model then becomes the final choice for real-world applications, ensuring robust performance in diverse scenarios.
In wrapping up, the art of data splitting is pivotal for shaping resilient machine learning models. Whether through random or stratified methods, or the iterative precision of K-Fold Cross-Validation, the chosen approach profoundly impacts a model's adaptability to new data.
Data splitting in practice
In general, the first step is splitting the data into 2 subsets: train – test. And then, we get the validation set from splitting the training set into 2 subset: train – validation.
Random splitting
Random data splitting involves shuffling the entire dataset and then randomly dividing it into three subsets in a specified ratio. Let's delve into a detailed analysis of this method.
In cases where the dataset is balanced (the number of observations or samples in all classes is nearly equal or not significantly different), random splitting can work well. For example, if you have two classes with a ratio of x:y, when using random splitting to divide the entire dataset into n subsets, the ratio in each subset can vary slightly but not by a significant amount. Therefore, the distribution may not change significantly (compare with the original distribution) and can approximate equality among the n subsets.
In contrast, when dealing with imbalanced data (significant differences in the number of observations among classes), random splitting may not be suitable. This is particularly evident in the worst-case scenario, where the training set lacks examples of minority classes, adversely impacting model performance on those classes. Consider a dataset with 7000 dogs and 3000 cats, using a random splitting ratio of 7:1:2 (train-validation-test). The worst outcome could yield a training set exclusively comprising dogs (7000 dogs), while the validation and testing sets consist solely of cats (1000 cats in validation – 2000 cats in testing). Such a noticeable distribution difference can be problematic.To address this challenge, especially in imbalanced datasets, an alternative method known as Stratified Splitting can be employed.
Stratified Splitting
Stratified splitting is a vital technique, especially when dealing with imbalanced datasets. This method ensures that the distribution of classes in each subset mirrors the original distribution, preserving the ratio among all classes during the data division process.
Process:
Shuffling: Commence by shuffling the entire dataset.
Splitting: Divide the shuffled data into n subsets, with each subset maintaining the original ratio among all classes.
Example: Dog-Cat Dataset
Original Dog-Cat Ratio: 7:3
Train-Validation-Test Ratio: 7:1:2
Desired Stratified Ratio in Each Subset:
Divide 7000 dogs into 10 parts, each containing 700 dogs.
Divide 3000 cats into 10 parts, each containing 300 cats.
Resultant Distribution in Subsets:
Training Set: 7 parts of dogs and 7 parts of cats (4900 dogs, 2100 cats)
Validation Set: 1 part of dogs and 1 part of cats (700 dogs, 300 cats)
Testing Set: 2 parts of dogs and 2 parts of cats (1400 dogs, 600 cats)
Stratified splitting ensures that each subset maintains the original class ratio, allowing the model to learn effectively from all classes, even those with fewer examples.
K-fold cross validation
K-fold cross-validation is particularly useful in situations where you have a limited amount of data, as it allows you to make the most out of your dataset by using it for both training and validation in multiple iterations. It helps reduce the bias that may arise from a single train-test split and provides a more comprehensive assessment of how well the model generalizes to different subsets of the data.
Figure 3. Illustration of the k-fold splitting process
The basic idea is to divide the dataset into k subsets, or k folds. The model is then trained on k-1 of these folds and validated on the remaining one. This process is repeated k times, each time using a different fold as the validation set and the remaining folds as the training set. In each iteration, we have a trained model and evaluate it on the validation set. The model’s performance (such as accuracy, precision, recall, …) is estimated by averaging over the k iterations.
K-Fold Cross-Validation not only offers a truthful evaluation method but also serves as a powerful tool for fine-tuning. By experimenting with different parameter combinations across the k models, one can identify the optimal model that performs best on the testing set. This selected model then becomes the final choice for real-world applications, ensuring robust performance in diverse scenarios.
In wrapping up, the art of data splitting is pivotal for shaping resilient machine learning models. Whether through random or stratified methods, or the iterative precision of K-Fold Cross-Validation, the chosen approach profoundly impacts a model's adaptability to new data.
Dao Pham
Product Developer
#TechEnthusiast #AIProductDeveloper
Dao Pham
Product Developer
#TechEnthusiast #AIProductDeveloper
Dao Pham
Product Developer
#TechEnthusiast #AIProductDeveloper
Dao Pham
Product Developer
#TechEnthusiast #AIProductDeveloper