Annotab Studio 2.0.0 is now live
Revolutionizing AI: Advanced Insights into Large Language Models
Revolutionizing AI: Advanced Insights into Large Language Models
Revolutionizing AI: Advanced Insights into Large Language Models
Revolutionizing AI: Advanced Insights into Large Language Models
Published by

Osama Akhlaq
on
Jan 10, 2024
under
AI
Published by
Osama Akhlaq
on
Jan 10, 2024
under
AI
Published by
Osama Akhlaq
on
Jan 10, 2024
under
AI
Published by
Osama Akhlaq
on
Jan 10, 2024
under
AI
ON THIS PAGE
Tl;dr
Imagine an AI that writes your emails, translates languages flawlessly, and even creates poems on demand. Oh, you don't have to because it's no longer science fiction – generative AI models like ChatGPT and Gemini are already weaving their magic into our daily lives. But how do these powerful tools work, and what's their true potential? In this article, we'll break down the essentials of Large Language Models (LLMs) in a way anyone can understand. So, buckle up and get ready to see the future of language.
Tl;dr
Imagine an AI that writes your emails, translates languages flawlessly, and even creates poems on demand. Oh, you don't have to because it's no longer science fiction – generative AI models like ChatGPT and Gemini are already weaving their magic into our daily lives. But how do these powerful tools work, and what's their true potential? In this article, we'll break down the essentials of Large Language Models (LLMs) in a way anyone can understand. So, buckle up and get ready to see the future of language.
Tl;dr
Imagine an AI that writes your emails, translates languages flawlessly, and even creates poems on demand. Oh, you don't have to because it's no longer science fiction – generative AI models like ChatGPT and Gemini are already weaving their magic into our daily lives. But how do these powerful tools work, and what's their true potential? In this article, we'll break down the essentials of Large Language Models (LLMs) in a way anyone can understand. So, buckle up and get ready to see the future of language.
Tl;dr
Imagine an AI that writes your emails, translates languages flawlessly, and even creates poems on demand. Oh, you don't have to because it's no longer science fiction – generative AI models like ChatGPT and Gemini are already weaving their magic into our daily lives. But how do these powerful tools work, and what's their true potential? In this article, we'll break down the essentials of Large Language Models (LLMs) in a way anyone can understand. So, buckle up and get ready to see the future of language.

Introduction
In the swiftly advancing field of Artificial Intelligence (AI), the rise of Large Language Models (LLMs) is a game-changer, reshaping how we use and interact with technology. The story of LLMs isn't just about recent tech trends; it's a long journey that spans many years of research and significant discoveries in how computers understand our language.
Let's rewind to the early days of AI. Back then, the idea of a computer that could understand and speak like us seemed more like science fiction. The first attempts to make this happen were based on set rules. These were impressive for their time, but they couldn't fully understand human language's subtle and complex parts.
As technology got better, so did our approach to teaching computer language. The giant leap came with machine learning and then deep learning. This introduced neural networks, and in particular, types called recurrent neural networks (RNNs) and transformers. They were trained with vast amounts of data and started to get good at handling language. They could understand, respond, and even write quite human-like text. This set the stage for the LLMs we see today.
A significant turning point was the creation of models like OpenAI's GPT series. These were bigger and better at dealing with many different language tasks. They could do things like translation and content creation with astonishing skill levels.
Now, LLMs are leading the charge in AI and are used in many different areas. They help in customer service, aiding scientific research, and much more. They're changing how we interact with machines and opening new possibilities for what AI can do with language.
In this article, we will dive into the world of LLMs. We'll look at how they're being used right now, and I'll even show you some examples and ways you can start using these AI wonders in your projects. The story of LLMs is a sign of human creativity and gives us a glimpse into the future of AI, where language is the key link between our thoughts and machine intelligence.
Introduction
In the swiftly advancing field of Artificial Intelligence (AI), the rise of Large Language Models (LLMs) is a game-changer, reshaping how we use and interact with technology. The story of LLMs isn't just about recent tech trends; it's a long journey that spans many years of research and significant discoveries in how computers understand our language.
Let's rewind to the early days of AI. Back then, the idea of a computer that could understand and speak like us seemed more like science fiction. The first attempts to make this happen were based on set rules. These were impressive for their time, but they couldn't fully understand human language's subtle and complex parts.
As technology got better, so did our approach to teaching computer language. The giant leap came with machine learning and then deep learning. This introduced neural networks, and in particular, types called recurrent neural networks (RNNs) and transformers. They were trained with vast amounts of data and started to get good at handling language. They could understand, respond, and even write quite human-like text. This set the stage for the LLMs we see today.
A significant turning point was the creation of models like OpenAI's GPT series. These were bigger and better at dealing with many different language tasks. They could do things like translation and content creation with astonishing skill levels.
Now, LLMs are leading the charge in AI and are used in many different areas. They help in customer service, aiding scientific research, and much more. They're changing how we interact with machines and opening new possibilities for what AI can do with language.
In this article, we will dive into the world of LLMs. We'll look at how they're being used right now, and I'll even show you some examples and ways you can start using these AI wonders in your projects. The story of LLMs is a sign of human creativity and gives us a glimpse into the future of AI, where language is the key link between our thoughts and machine intelligence.
Introduction
In the swiftly advancing field of Artificial Intelligence (AI), the rise of Large Language Models (LLMs) is a game-changer, reshaping how we use and interact with technology. The story of LLMs isn't just about recent tech trends; it's a long journey that spans many years of research and significant discoveries in how computers understand our language.
Let's rewind to the early days of AI. Back then, the idea of a computer that could understand and speak like us seemed more like science fiction. The first attempts to make this happen were based on set rules. These were impressive for their time, but they couldn't fully understand human language's subtle and complex parts.
As technology got better, so did our approach to teaching computer language. The giant leap came with machine learning and then deep learning. This introduced neural networks, and in particular, types called recurrent neural networks (RNNs) and transformers. They were trained with vast amounts of data and started to get good at handling language. They could understand, respond, and even write quite human-like text. This set the stage for the LLMs we see today.
A significant turning point was the creation of models like OpenAI's GPT series. These were bigger and better at dealing with many different language tasks. They could do things like translation and content creation with astonishing skill levels.
Now, LLMs are leading the charge in AI and are used in many different areas. They help in customer service, aiding scientific research, and much more. They're changing how we interact with machines and opening new possibilities for what AI can do with language.
In this article, we will dive into the world of LLMs. We'll look at how they're being used right now, and I'll even show you some examples and ways you can start using these AI wonders in your projects. The story of LLMs is a sign of human creativity and gives us a glimpse into the future of AI, where language is the key link between our thoughts and machine intelligence.
Introduction
In the swiftly advancing field of Artificial Intelligence (AI), the rise of Large Language Models (LLMs) is a game-changer, reshaping how we use and interact with technology. The story of LLMs isn't just about recent tech trends; it's a long journey that spans many years of research and significant discoveries in how computers understand our language.
Let's rewind to the early days of AI. Back then, the idea of a computer that could understand and speak like us seemed more like science fiction. The first attempts to make this happen were based on set rules. These were impressive for their time, but they couldn't fully understand human language's subtle and complex parts.
As technology got better, so did our approach to teaching computer language. The giant leap came with machine learning and then deep learning. This introduced neural networks, and in particular, types called recurrent neural networks (RNNs) and transformers. They were trained with vast amounts of data and started to get good at handling language. They could understand, respond, and even write quite human-like text. This set the stage for the LLMs we see today.
A significant turning point was the creation of models like OpenAI's GPT series. These were bigger and better at dealing with many different language tasks. They could do things like translation and content creation with astonishing skill levels.
Now, LLMs are leading the charge in AI and are used in many different areas. They help in customer service, aiding scientific research, and much more. They're changing how we interact with machines and opening new possibilities for what AI can do with language.
In this article, we will dive into the world of LLMs. We'll look at how they're being used right now, and I'll even show you some examples and ways you can start using these AI wonders in your projects. The story of LLMs is a sign of human creativity and gives us a glimpse into the future of AI, where language is the key link between our thoughts and machine intelligence.
Understanding Large Language Models
Let's start by looking closely at what makes Large Language Models (LLMs) so special. Imagine LLMs as massive, intricate puzzles, where each piece is a tiny bit of data. These pieces can help a computer understand and even mimic human language when put together correctly. At the heart of LLMs are neural networks, which are like the brain's wiring, helping the model learn and make decisions based on the information it receives.
These neural networks in LLMs are often built using something called transformers. Transformers are great at handling lots of information at once and are particularly good at understanding the context – or the 'why' and 'how' – behind words in a sentence. This helps LLMs not just read the words but also get the meaning and feel behind them.
From Theory to Practice: How LLMs Learn and Operate
How do these LLMs go from a concept to something that can understand and use language? It starts with training. Training an LLM is like teaching it the rules of language, but instead of sitting in a classroom, it learns from massive amounts of text data. This could be anything from books and articles to websites.
During training, LLMs look for patterns and relationships in the data. They learn which words often go together, how sentences are structured, and even different writing styles. Think of it as the model soaking up all this knowledge to use later.
Once the training is done, LLMs can start doing some amazing things with language. They can write articles, create poetry, or even chat with you. The more they interact and get used to different ways people use language, the better they understand and respond in a natural and human-like way.
Historical Milestones in Language Model Development
The Evolution from Rule-Based Systems to Neural Networks
The journey of language models in AI is quite fascinating. It all started with rule-based systems. These early models followed strict rules set by programmers to understand and use language. Imagine them as basic instruction manuals, telling the computer, "If you see this, then do that." They were suitable for their time but had their limits. They couldn't grasp the full richness and variety of human language.
As technology advanced, so did the way we teach computers about language. Enter neural networks – a giant leap forward. Our brains inspire neural networks. They don't just follow set rules; they learn from examples. This shift from rule-based systems to neural networks was like moving from a simple instruction manual to a dynamic learning experience. Neural networks could process large amounts of data and learn language patterns, making them much more effective at understanding and generating human-like text.
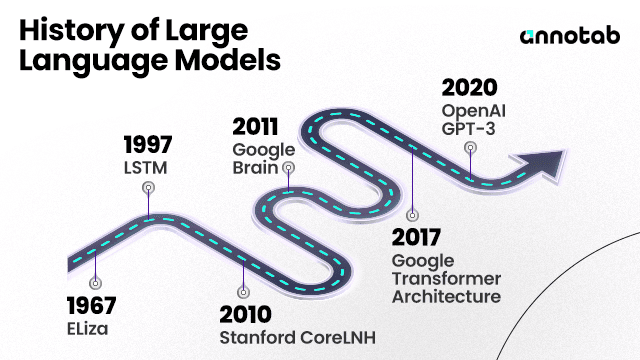
Breakthroughs and Key Players in LLM Progress
The development of language models saw some significant breakthroughs over time. One of the game-changers was the introduction of models like OpenAI's GPT series. These models didn't just learn language; they learned how to use it versatilely. They could do multiple tasks like translating languages, writing stories, and even holding conversations.
Key players in this field, like OpenAI, Google, and others, played a massive role in pushing the boundaries of what these models could do. They invested in research and development, creating models that were not only bigger in terms of data and complexity but also more efficient and capable.
These breakthroughs took time to happen. They resulted from years of hard work, research, and trial and error. Thanks to these advancements, we have Large Language Models that can understand context, nuance, and even the subtleties of different languages. It's a testament to how far we've come from those early rule-based systems to the highly sophisticated AI models we see today.
Current Landscape: Applications and Use Cases
Revolutionizing Business: LLMs in Corporate Settings
Large Language Models (LLMs) are changing the game in the business world. Companies are using LLMs to automate tasks that used to need human brains. Think of writing reports, sorting through data, or answering customer questions. LLMs can handle these tasks quickly and accurately, saving businesses time and money. They're about more than just doing things faster; they also bring new ideas and innovations. For example, they help in brainstorming sessions, generating creative solutions that this is the first time anyone has thought of.
Creative and Content Generation: The New Frontier
Regarding creativity, LLMs are like a breath of fresh air. Writers, artists, and content creators are using these models to push the boundaries of their work. Need a story idea? An LLM can give you one. Are they stuck on a song lyric? An LLM can help with that, too. They're even being used to write entire articles and scripts. The beauty here is in the collaboration between human creativity and AI efficiency, leading to new forms of art and content that we've never seen before.
Enhancing Scientific Research with LLMs
In the world of science, LLMs are proving to be invaluable. They're used to sift through mountains of research papers and data, helping scientists stay up to date and find important information quickly. They're also great at predicting outcomes, like how a new medicine might work or what happens in a complex chemical reaction. This means scientists can explore new ideas and hypotheses with a helping hand from AI, speeding up discoveries and innovations.
The Role of LLMs in Customer Interaction and Service
Finally, in customer service, LLMs are becoming key players. They're powering chatbots and virtual assistants, making them more helpful and conversational. Gone are the days of robotic, unhelpful responses. Now, customers can get quick, accurate help anytime, improving their experience and satisfaction. Plus, these AI assistants can learn and adapt over time, getting better at understanding and solving customer issues.
In all these areas, LLMs are not just tools but partners, working alongside humans to create, innovate, and improve. The current landscape of LLM applications is vast and varied, showing how versatile and powerful these models have become.
Understanding Large Language Models
Let's start by looking closely at what makes Large Language Models (LLMs) so special. Imagine LLMs as massive, intricate puzzles, where each piece is a tiny bit of data. These pieces can help a computer understand and even mimic human language when put together correctly. At the heart of LLMs are neural networks, which are like the brain's wiring, helping the model learn and make decisions based on the information it receives.
These neural networks in LLMs are often built using something called transformers. Transformers are great at handling lots of information at once and are particularly good at understanding the context – or the 'why' and 'how' – behind words in a sentence. This helps LLMs not just read the words but also get the meaning and feel behind them.
From Theory to Practice: How LLMs Learn and Operate
How do these LLMs go from a concept to something that can understand and use language? It starts with training. Training an LLM is like teaching it the rules of language, but instead of sitting in a classroom, it learns from massive amounts of text data. This could be anything from books and articles to websites.
During training, LLMs look for patterns and relationships in the data. They learn which words often go together, how sentences are structured, and even different writing styles. Think of it as the model soaking up all this knowledge to use later.
Once the training is done, LLMs can start doing some amazing things with language. They can write articles, create poetry, or even chat with you. The more they interact and get used to different ways people use language, the better they understand and respond in a natural and human-like way.
Historical Milestones in Language Model Development
The Evolution from Rule-Based Systems to Neural Networks
The journey of language models in AI is quite fascinating. It all started with rule-based systems. These early models followed strict rules set by programmers to understand and use language. Imagine them as basic instruction manuals, telling the computer, "If you see this, then do that." They were suitable for their time but had their limits. They couldn't grasp the full richness and variety of human language.
As technology advanced, so did the way we teach computers about language. Enter neural networks – a giant leap forward. Our brains inspire neural networks. They don't just follow set rules; they learn from examples. This shift from rule-based systems to neural networks was like moving from a simple instruction manual to a dynamic learning experience. Neural networks could process large amounts of data and learn language patterns, making them much more effective at understanding and generating human-like text.
Breakthroughs and Key Players in LLM Progress
The development of language models saw some significant breakthroughs over time. One of the game-changers was the introduction of models like OpenAI's GPT series. These models didn't just learn language; they learned how to use it versatilely. They could do multiple tasks like translating languages, writing stories, and even holding conversations.
Key players in this field, like OpenAI, Google, and others, played a massive role in pushing the boundaries of what these models could do. They invested in research and development, creating models that were not only bigger in terms of data and complexity but also more efficient and capable.
These breakthroughs took time to happen. They resulted from years of hard work, research, and trial and error. Thanks to these advancements, we have Large Language Models that can understand context, nuance, and even the subtleties of different languages. It's a testament to how far we've come from those early rule-based systems to the highly sophisticated AI models we see today.
Current Landscape: Applications and Use Cases
Revolutionizing Business: LLMs in Corporate Settings
Large Language Models (LLMs) are changing the game in the business world. Companies are using LLMs to automate tasks that used to need human brains. Think of writing reports, sorting through data, or answering customer questions. LLMs can handle these tasks quickly and accurately, saving businesses time and money. They're about more than just doing things faster; they also bring new ideas and innovations. For example, they help in brainstorming sessions, generating creative solutions that this is the first time anyone has thought of.
Creative and Content Generation: The New Frontier
Regarding creativity, LLMs are like a breath of fresh air. Writers, artists, and content creators are using these models to push the boundaries of their work. Need a story idea? An LLM can give you one. Are they stuck on a song lyric? An LLM can help with that, too. They're even being used to write entire articles and scripts. The beauty here is in the collaboration between human creativity and AI efficiency, leading to new forms of art and content that we've never seen before.
Enhancing Scientific Research with LLMs
In the world of science, LLMs are proving to be invaluable. They're used to sift through mountains of research papers and data, helping scientists stay up to date and find important information quickly. They're also great at predicting outcomes, like how a new medicine might work or what happens in a complex chemical reaction. This means scientists can explore new ideas and hypotheses with a helping hand from AI, speeding up discoveries and innovations.
The Role of LLMs in Customer Interaction and Service
Finally, in customer service, LLMs are becoming key players. They're powering chatbots and virtual assistants, making them more helpful and conversational. Gone are the days of robotic, unhelpful responses. Now, customers can get quick, accurate help anytime, improving their experience and satisfaction. Plus, these AI assistants can learn and adapt over time, getting better at understanding and solving customer issues.
In all these areas, LLMs are not just tools but partners, working alongside humans to create, innovate, and improve. The current landscape of LLM applications is vast and varied, showing how versatile and powerful these models have become.
Understanding Large Language Models
Let's start by looking closely at what makes Large Language Models (LLMs) so special. Imagine LLMs as massive, intricate puzzles, where each piece is a tiny bit of data. These pieces can help a computer understand and even mimic human language when put together correctly. At the heart of LLMs are neural networks, which are like the brain's wiring, helping the model learn and make decisions based on the information it receives.
These neural networks in LLMs are often built using something called transformers. Transformers are great at handling lots of information at once and are particularly good at understanding the context – or the 'why' and 'how' – behind words in a sentence. This helps LLMs not just read the words but also get the meaning and feel behind them.
From Theory to Practice: How LLMs Learn and Operate
How do these LLMs go from a concept to something that can understand and use language? It starts with training. Training an LLM is like teaching it the rules of language, but instead of sitting in a classroom, it learns from massive amounts of text data. This could be anything from books and articles to websites.
During training, LLMs look for patterns and relationships in the data. They learn which words often go together, how sentences are structured, and even different writing styles. Think of it as the model soaking up all this knowledge to use later.
Once the training is done, LLMs can start doing some amazing things with language. They can write articles, create poetry, or even chat with you. The more they interact and get used to different ways people use language, the better they understand and respond in a natural and human-like way.
Historical Milestones in Language Model Development
The Evolution from Rule-Based Systems to Neural Networks
The journey of language models in AI is quite fascinating. It all started with rule-based systems. These early models followed strict rules set by programmers to understand and use language. Imagine them as basic instruction manuals, telling the computer, "If you see this, then do that." They were suitable for their time but had their limits. They couldn't grasp the full richness and variety of human language.
As technology advanced, so did the way we teach computers about language. Enter neural networks – a giant leap forward. Our brains inspire neural networks. They don't just follow set rules; they learn from examples. This shift from rule-based systems to neural networks was like moving from a simple instruction manual to a dynamic learning experience. Neural networks could process large amounts of data and learn language patterns, making them much more effective at understanding and generating human-like text.
Breakthroughs and Key Players in LLM Progress
The development of language models saw some significant breakthroughs over time. One of the game-changers was the introduction of models like OpenAI's GPT series. These models didn't just learn language; they learned how to use it versatilely. They could do multiple tasks like translating languages, writing stories, and even holding conversations.
Key players in this field, like OpenAI, Google, and others, played a massive role in pushing the boundaries of what these models could do. They invested in research and development, creating models that were not only bigger in terms of data and complexity but also more efficient and capable.
These breakthroughs took time to happen. They resulted from years of hard work, research, and trial and error. Thanks to these advancements, we have Large Language Models that can understand context, nuance, and even the subtleties of different languages. It's a testament to how far we've come from those early rule-based systems to the highly sophisticated AI models we see today.
Current Landscape: Applications and Use Cases
Revolutionizing Business: LLMs in Corporate Settings
Large Language Models (LLMs) are changing the game in the business world. Companies are using LLMs to automate tasks that used to need human brains. Think of writing reports, sorting through data, or answering customer questions. LLMs can handle these tasks quickly and accurately, saving businesses time and money. They're about more than just doing things faster; they also bring new ideas and innovations. For example, they help in brainstorming sessions, generating creative solutions that this is the first time anyone has thought of.
Creative and Content Generation: The New Frontier
Regarding creativity, LLMs are like a breath of fresh air. Writers, artists, and content creators are using these models to push the boundaries of their work. Need a story idea? An LLM can give you one. Are they stuck on a song lyric? An LLM can help with that, too. They're even being used to write entire articles and scripts. The beauty here is in the collaboration between human creativity and AI efficiency, leading to new forms of art and content that we've never seen before.
Enhancing Scientific Research with LLMs
In the world of science, LLMs are proving to be invaluable. They're used to sift through mountains of research papers and data, helping scientists stay up to date and find important information quickly. They're also great at predicting outcomes, like how a new medicine might work or what happens in a complex chemical reaction. This means scientists can explore new ideas and hypotheses with a helping hand from AI, speeding up discoveries and innovations.
The Role of LLMs in Customer Interaction and Service
Finally, in customer service, LLMs are becoming key players. They're powering chatbots and virtual assistants, making them more helpful and conversational. Gone are the days of robotic, unhelpful responses. Now, customers can get quick, accurate help anytime, improving their experience and satisfaction. Plus, these AI assistants can learn and adapt over time, getting better at understanding and solving customer issues.
In all these areas, LLMs are not just tools but partners, working alongside humans to create, innovate, and improve. The current landscape of LLM applications is vast and varied, showing how versatile and powerful these models have become.
Understanding Large Language Models
Let's start by looking closely at what makes Large Language Models (LLMs) so special. Imagine LLMs as massive, intricate puzzles, where each piece is a tiny bit of data. These pieces can help a computer understand and even mimic human language when put together correctly. At the heart of LLMs are neural networks, which are like the brain's wiring, helping the model learn and make decisions based on the information it receives.
These neural networks in LLMs are often built using something called transformers. Transformers are great at handling lots of information at once and are particularly good at understanding the context – or the 'why' and 'how' – behind words in a sentence. This helps LLMs not just read the words but also get the meaning and feel behind them.
From Theory to Practice: How LLMs Learn and Operate
How do these LLMs go from a concept to something that can understand and use language? It starts with training. Training an LLM is like teaching it the rules of language, but instead of sitting in a classroom, it learns from massive amounts of text data. This could be anything from books and articles to websites.
During training, LLMs look for patterns and relationships in the data. They learn which words often go together, how sentences are structured, and even different writing styles. Think of it as the model soaking up all this knowledge to use later.
Once the training is done, LLMs can start doing some amazing things with language. They can write articles, create poetry, or even chat with you. The more they interact and get used to different ways people use language, the better they understand and respond in a natural and human-like way.
Historical Milestones in Language Model Development
The Evolution from Rule-Based Systems to Neural Networks
The journey of language models in AI is quite fascinating. It all started with rule-based systems. These early models followed strict rules set by programmers to understand and use language. Imagine them as basic instruction manuals, telling the computer, "If you see this, then do that." They were suitable for their time but had their limits. They couldn't grasp the full richness and variety of human language.
As technology advanced, so did the way we teach computers about language. Enter neural networks – a giant leap forward. Our brains inspire neural networks. They don't just follow set rules; they learn from examples. This shift from rule-based systems to neural networks was like moving from a simple instruction manual to a dynamic learning experience. Neural networks could process large amounts of data and learn language patterns, making them much more effective at understanding and generating human-like text.
Breakthroughs and Key Players in LLM Progress
The development of language models saw some significant breakthroughs over time. One of the game-changers was the introduction of models like OpenAI's GPT series. These models didn't just learn language; they learned how to use it versatilely. They could do multiple tasks like translating languages, writing stories, and even holding conversations.
Key players in this field, like OpenAI, Google, and others, played a massive role in pushing the boundaries of what these models could do. They invested in research and development, creating models that were not only bigger in terms of data and complexity but also more efficient and capable.
These breakthroughs took time to happen. They resulted from years of hard work, research, and trial and error. Thanks to these advancements, we have Large Language Models that can understand context, nuance, and even the subtleties of different languages. It's a testament to how far we've come from those early rule-based systems to the highly sophisticated AI models we see today.
Current Landscape: Applications and Use Cases
Revolutionizing Business: LLMs in Corporate Settings
Large Language Models (LLMs) are changing the game in the business world. Companies are using LLMs to automate tasks that used to need human brains. Think of writing reports, sorting through data, or answering customer questions. LLMs can handle these tasks quickly and accurately, saving businesses time and money. They're about more than just doing things faster; they also bring new ideas and innovations. For example, they help in brainstorming sessions, generating creative solutions that this is the first time anyone has thought of.
Creative and Content Generation: The New Frontier
Regarding creativity, LLMs are like a breath of fresh air. Writers, artists, and content creators are using these models to push the boundaries of their work. Need a story idea? An LLM can give you one. Are they stuck on a song lyric? An LLM can help with that, too. They're even being used to write entire articles and scripts. The beauty here is in the collaboration between human creativity and AI efficiency, leading to new forms of art and content that we've never seen before.
Enhancing Scientific Research with LLMs
In the world of science, LLMs are proving to be invaluable. They're used to sift through mountains of research papers and data, helping scientists stay up to date and find important information quickly. They're also great at predicting outcomes, like how a new medicine might work or what happens in a complex chemical reaction. This means scientists can explore new ideas and hypotheses with a helping hand from AI, speeding up discoveries and innovations.
The Role of LLMs in Customer Interaction and Service
Finally, in customer service, LLMs are becoming key players. They're powering chatbots and virtual assistants, making them more helpful and conversational. Gone are the days of robotic, unhelpful responses. Now, customers can get quick, accurate help anytime, improving their experience and satisfaction. Plus, these AI assistants can learn and adapt over time, getting better at understanding and solving customer issues.
In all these areas, LLMs are not just tools but partners, working alongside humans to create, innovate, and improve. The current landscape of LLM applications is vast and varied, showing how versatile and powerful these models have become.
Technical Mechanics of LLMs
Understanding how Large Language Models (LLMs) work is like peeking inside a complex machine. Let's simplify and explore the technical mechanics that power these AI wonders.
Unraveling Neural Network Architectures: RNNs, CNNs, and Transformers
At the core of LLMs are neural networks, like the brain's way of processing information. There are several types, each with its unique strengths.
Recurrent Neural Networks (RNNs):
Think of RNNs as storytellers. They're great at understanding sequences, like sentences in a book. RNNs process words one after another, remembering previous words to make sense of the next. This makes them ideal for tasks where the order of data is essential.
Convolutional Neural Networks (CNNs):
CNNs are like detectives, excellent at finding patterns. They gained fame in image processing but are also used in language tasks. CNNs scan through data to identify patterns and are especially good at classifying and grouping things.
Transformers:
The stars of the show in recent LLMs are transformers. Imagine them as super-efficient multitaskers. They can look at an entire sentence simultaneously rather than word by word, making them faster and more effective at understanding context. This is why they're a big deal in models like GPT-3.
Training Processes and Data Handling in LLMs
Training an LLM is like teaching it the language. It involves feeding vast amounts of text data into the model. This data could be anything – books, articles, websites. The model looks for patterns in this data: which words often go together, how sentences are structured, etc. The more data it sees, the better it understands and generates language.
Data handling is also vital. LLMs need diverse and accurate data to learn well. This means not only a lot of data but also high-quality data. If the data is biased or flawed, the model's output will be too.
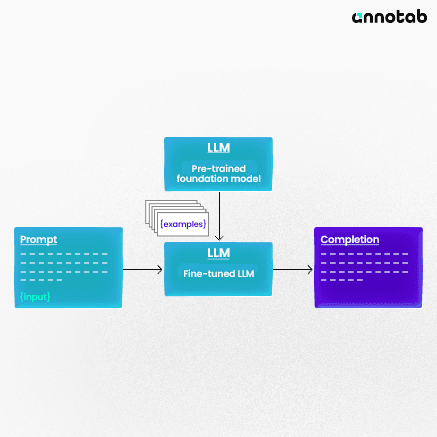
Understanding Pre-training and Fine-tuning in Language Models
Pre-training and fine-tuning are like the two stages of an LLM's education.
Pre-training:
In this phase, the model learns general language skills. It's like going to school where you know a bit of everything. The model is trained on a large, varied dataset to understand language broadly.
Fine-tuning:
This is more like college, where you specialize in a subject. Here, the pre-trained model is further trained on specific types of data. For example, if you want the model to excel in legal documents, you fine-tune it with legal texts. This makes the model an expert in that particular area.
These processes ensure that LLMs are good at understanding language and adaptable to different needs and tasks. They start with a broad understanding and then specialize as needed, like human learning.
In short, the technical mechanics of LLMs involve complex neural network architectures and sophisticated training processes. Understanding these elements helps us appreciate the power and potential of these models in transforming how we interact with AI.
Technical Mechanics of LLMs
Understanding how Large Language Models (LLMs) work is like peeking inside a complex machine. Let's simplify and explore the technical mechanics that power these AI wonders.
Unraveling Neural Network Architectures: RNNs, CNNs, and Transformers
At the core of LLMs are neural networks, like the brain's way of processing information. There are several types, each with its unique strengths.
Recurrent Neural Networks (RNNs):
Think of RNNs as storytellers. They're great at understanding sequences, like sentences in a book. RNNs process words one after another, remembering previous words to make sense of the next. This makes them ideal for tasks where the order of data is essential.
Convolutional Neural Networks (CNNs):
CNNs are like detectives, excellent at finding patterns. They gained fame in image processing but are also used in language tasks. CNNs scan through data to identify patterns and are especially good at classifying and grouping things.
Transformers:
The stars of the show in recent LLMs are transformers. Imagine them as super-efficient multitaskers. They can look at an entire sentence simultaneously rather than word by word, making them faster and more effective at understanding context. This is why they're a big deal in models like GPT-3.
Training Processes and Data Handling in LLMs
Training an LLM is like teaching it the language. It involves feeding vast amounts of text data into the model. This data could be anything – books, articles, websites. The model looks for patterns in this data: which words often go together, how sentences are structured, etc. The more data it sees, the better it understands and generates language.
Data handling is also vital. LLMs need diverse and accurate data to learn well. This means not only a lot of data but also high-quality data. If the data is biased or flawed, the model's output will be too.
Understanding Pre-training and Fine-tuning in Language Models
Pre-training and fine-tuning are like the two stages of an LLM's education.
Pre-training:
In this phase, the model learns general language skills. It's like going to school where you know a bit of everything. The model is trained on a large, varied dataset to understand language broadly.
Fine-tuning:
This is more like college, where you specialize in a subject. Here, the pre-trained model is further trained on specific types of data. For example, if you want the model to excel in legal documents, you fine-tune it with legal texts. This makes the model an expert in that particular area.
These processes ensure that LLMs are good at understanding language and adaptable to different needs and tasks. They start with a broad understanding and then specialize as needed, like human learning.
In short, the technical mechanics of LLMs involve complex neural network architectures and sophisticated training processes. Understanding these elements helps us appreciate the power and potential of these models in transforming how we interact with AI.
Technical Mechanics of LLMs
Understanding how Large Language Models (LLMs) work is like peeking inside a complex machine. Let's simplify and explore the technical mechanics that power these AI wonders.
Unraveling Neural Network Architectures: RNNs, CNNs, and Transformers
At the core of LLMs are neural networks, like the brain's way of processing information. There are several types, each with its unique strengths.
Recurrent Neural Networks (RNNs):
Think of RNNs as storytellers. They're great at understanding sequences, like sentences in a book. RNNs process words one after another, remembering previous words to make sense of the next. This makes them ideal for tasks where the order of data is essential.
Convolutional Neural Networks (CNNs):
CNNs are like detectives, excellent at finding patterns. They gained fame in image processing but are also used in language tasks. CNNs scan through data to identify patterns and are especially good at classifying and grouping things.
Transformers:
The stars of the show in recent LLMs are transformers. Imagine them as super-efficient multitaskers. They can look at an entire sentence simultaneously rather than word by word, making them faster and more effective at understanding context. This is why they're a big deal in models like GPT-3.
Training Processes and Data Handling in LLMs
Training an LLM is like teaching it the language. It involves feeding vast amounts of text data into the model. This data could be anything – books, articles, websites. The model looks for patterns in this data: which words often go together, how sentences are structured, etc. The more data it sees, the better it understands and generates language.
Data handling is also vital. LLMs need diverse and accurate data to learn well. This means not only a lot of data but also high-quality data. If the data is biased or flawed, the model's output will be too.
Understanding Pre-training and Fine-tuning in Language Models
Pre-training and fine-tuning are like the two stages of an LLM's education.
Pre-training:
In this phase, the model learns general language skills. It's like going to school where you know a bit of everything. The model is trained on a large, varied dataset to understand language broadly.
Fine-tuning:
This is more like college, where you specialize in a subject. Here, the pre-trained model is further trained on specific types of data. For example, if you want the model to excel in legal documents, you fine-tune it with legal texts. This makes the model an expert in that particular area.
These processes ensure that LLMs are good at understanding language and adaptable to different needs and tasks. They start with a broad understanding and then specialize as needed, like human learning.
In short, the technical mechanics of LLMs involve complex neural network architectures and sophisticated training processes. Understanding these elements helps us appreciate the power and potential of these models in transforming how we interact with AI.
Technical Mechanics of LLMs
Understanding how Large Language Models (LLMs) work is like peeking inside a complex machine. Let's simplify and explore the technical mechanics that power these AI wonders.
Unraveling Neural Network Architectures: RNNs, CNNs, and Transformers
At the core of LLMs are neural networks, like the brain's way of processing information. There are several types, each with its unique strengths.
Recurrent Neural Networks (RNNs):
Think of RNNs as storytellers. They're great at understanding sequences, like sentences in a book. RNNs process words one after another, remembering previous words to make sense of the next. This makes them ideal for tasks where the order of data is essential.
Convolutional Neural Networks (CNNs):
CNNs are like detectives, excellent at finding patterns. They gained fame in image processing but are also used in language tasks. CNNs scan through data to identify patterns and are especially good at classifying and grouping things.
Transformers:
The stars of the show in recent LLMs are transformers. Imagine them as super-efficient multitaskers. They can look at an entire sentence simultaneously rather than word by word, making them faster and more effective at understanding context. This is why they're a big deal in models like GPT-3.
Training Processes and Data Handling in LLMs
Training an LLM is like teaching it the language. It involves feeding vast amounts of text data into the model. This data could be anything – books, articles, websites. The model looks for patterns in this data: which words often go together, how sentences are structured, etc. The more data it sees, the better it understands and generates language.
Data handling is also vital. LLMs need diverse and accurate data to learn well. This means not only a lot of data but also high-quality data. If the data is biased or flawed, the model's output will be too.
Understanding Pre-training and Fine-tuning in Language Models
Pre-training and fine-tuning are like the two stages of an LLM's education.
Pre-training:
In this phase, the model learns general language skills. It's like going to school where you know a bit of everything. The model is trained on a large, varied dataset to understand language broadly.
Fine-tuning:
This is more like college, where you specialize in a subject. Here, the pre-trained model is further trained on specific types of data. For example, if you want the model to excel in legal documents, you fine-tune it with legal texts. This makes the model an expert in that particular area.
These processes ensure that LLMs are good at understanding language and adaptable to different needs and tasks. They start with a broad understanding and then specialize as needed, like human learning.
In short, the technical mechanics of LLMs involve complex neural network architectures and sophisticated training processes. Understanding these elements helps us appreciate the power and potential of these models in transforming how we interact with AI.
Technical Insight: Implementing LLMs
This section will implement a text generation model using GPT-2, a renowned Large Language Model (LLM) developed by OpenAI. The code demonstrates integrating GPT-2 into a Python project to generate coherent and contextually relevant text based on a given input prompt. It includes steps for loading the GPT-2 model and tokenizer, configuring the necessary parameters for text generation (such as padding and truncation), and executing the model to produce a response. This example is a practical illustration of utilizing LLMs like GPT-2 for natural language processing tasks, showcasing their ability to understand and generate human-like text.
Follow these steps to execute it:
Import Required Libraries as shown below:
from transformers import GPT2Tokenizer, GPT2LMHeadModelGPT2Tokenizer: This converts input text into a format (tokens) that the model can understand.
GPT2LMHeadModel: This is the actual GPT-2 model which will generate the text.
Define the Text generation Method. The function, generate_text, is designed to take a prompt (input text) and generate a response based on this prompt.
model_name specifies which model to use, defaulting to 'gpt2'.
max_length controls the maximum length of the generated response, including the prompt length.
Load the model and tokenizer as shown below:
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)Set padding and truncation as shown below:
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenThe tokenizer is configured to pad on the left side. This is important for decoder-only models like GPT-2.
The end-of-sequence token (eos_token) is used as the padding token if no pad token is set.
Encode the prompt. The prompt is encoded with encode_plus, which prepares it for the model.
return_tensors='pt' ensures the output is a PyTorch tensor, suitable for the model.
attention_mask is used to inform the model which parts of the input are actual words and which are padding.
It is shown below:
inputs = tokenizer.encode_plus(prompt, return_tensors='pt', max_length=max_length,
pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']Generate the response.
Decode the generated text.
This code can be run smoothly on Google Colab. The complete code is as follows:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
def generate_text(prompt, model_name='gpt2', max_length=100):
# Load pre-trained model tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# Set padding side and pad token
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = GPT2LMHeadModel.from_pretrained(model_name)
# Encode text input with truncation and left padding
inputs = tokenizer.encode_plus(prompt, return_tensors='pt',
max_length=max_length, pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']
# Calculate new max_length for generation (prompt length +
max_new_tokens)
prompt_length = len(tokenizer.encode(prompt))
max_new_tokens = max_length - prompt_length
# Generate response
outputs = model.generate(inputs['input_ids'],
attention_mask=attention_mask, max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id, num_return_sequences=1)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
prompt = "What is the distance between the Earth and the Moon?"
generated_text = generate_text(prompt)
print(f"Generated Text: {generated_text}")It will generate output like the following:
Technical Insight: Implementing LLMs
This section will implement a text generation model using GPT-2, a renowned Large Language Model (LLM) developed by OpenAI. The code demonstrates integrating GPT-2 into a Python project to generate coherent and contextually relevant text based on a given input prompt. It includes steps for loading the GPT-2 model and tokenizer, configuring the necessary parameters for text generation (such as padding and truncation), and executing the model to produce a response. This example is a practical illustration of utilizing LLMs like GPT-2 for natural language processing tasks, showcasing their ability to understand and generate human-like text.
Follow these steps to execute it:
Import Required Libraries as shown below:
from transformers import GPT2Tokenizer, GPT2LMHeadModelGPT2Tokenizer: This converts input text into a format (tokens) that the model can understand.
GPT2LMHeadModel: This is the actual GPT-2 model which will generate the text.
Define the Text generation Method. The function, generate_text, is designed to take a prompt (input text) and generate a response based on this prompt.
model_name specifies which model to use, defaulting to 'gpt2'.
max_length controls the maximum length of the generated response, including the prompt length.
Load the model and tokenizer as shown below:
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)Set padding and truncation as shown below:
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenThe tokenizer is configured to pad on the left side. This is important for decoder-only models like GPT-2.
The end-of-sequence token (eos_token) is used as the padding token if no pad token is set.
Encode the prompt. The prompt is encoded with encode_plus, which prepares it for the model.
return_tensors='pt' ensures the output is a PyTorch tensor, suitable for the model.
attention_mask is used to inform the model which parts of the input are actual words and which are padding.
It is shown below:
inputs = tokenizer.encode_plus(prompt, return_tensors='pt', max_length=max_length,
pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']Generate the response.
Decode the generated text.
This code can be run smoothly on Google Colab. The complete code is as follows:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
def generate_text(prompt, model_name='gpt2', max_length=100):
# Load pre-trained model tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# Set padding side and pad token
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = GPT2LMHeadModel.from_pretrained(model_name)
# Encode text input with truncation and left padding
inputs = tokenizer.encode_plus(prompt, return_tensors='pt',
max_length=max_length, pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']
# Calculate new max_length for generation (prompt length +
max_new_tokens)
prompt_length = len(tokenizer.encode(prompt))
max_new_tokens = max_length - prompt_length
# Generate response
outputs = model.generate(inputs['input_ids'],
attention_mask=attention_mask, max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id, num_return_sequences=1)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
prompt = "What is the distance between the Earth and the Moon?"
generated_text = generate_text(prompt)
print(f"Generated Text: {generated_text}")It will generate output like the following:
Technical Insight: Implementing LLMs
This section will implement a text generation model using GPT-2, a renowned Large Language Model (LLM) developed by OpenAI. The code demonstrates integrating GPT-2 into a Python project to generate coherent and contextually relevant text based on a given input prompt. It includes steps for loading the GPT-2 model and tokenizer, configuring the necessary parameters for text generation (such as padding and truncation), and executing the model to produce a response. This example is a practical illustration of utilizing LLMs like GPT-2 for natural language processing tasks, showcasing their ability to understand and generate human-like text.
Follow these steps to execute it:
Import Required Libraries as shown below:
from transformers import GPT2Tokenizer, GPT2LMHeadModelGPT2Tokenizer: This converts input text into a format (tokens) that the model can understand.
GPT2LMHeadModel: This is the actual GPT-2 model which will generate the text.
Define the Text generation Method. The function, generate_text, is designed to take a prompt (input text) and generate a response based on this prompt.
model_name specifies which model to use, defaulting to 'gpt2'.
max_length controls the maximum length of the generated response, including the prompt length.
Load the model and tokenizer as shown below:
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)Set padding and truncation as shown below:
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenThe tokenizer is configured to pad on the left side. This is important for decoder-only models like GPT-2.
The end-of-sequence token (eos_token) is used as the padding token if no pad token is set.
Encode the prompt. The prompt is encoded with encode_plus, which prepares it for the model.
return_tensors='pt' ensures the output is a PyTorch tensor, suitable for the model.
attention_mask is used to inform the model which parts of the input are actual words and which are padding.
It is shown below:
inputs = tokenizer.encode_plus(prompt, return_tensors='pt', max_length=max_length,
pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']Generate the response.
Decode the generated text.
This code can be run smoothly on Google Colab. The complete code is as follows:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
def generate_text(prompt, model_name='gpt2', max_length=100):
# Load pre-trained model tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# Set padding side and pad token
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = GPT2LMHeadModel.from_pretrained(model_name)
# Encode text input with truncation and left padding
inputs = tokenizer.encode_plus(prompt, return_tensors='pt',
max_length=max_length, pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']
# Calculate new max_length for generation (prompt length +
max_new_tokens)
prompt_length = len(tokenizer.encode(prompt))
max_new_tokens = max_length - prompt_length
# Generate response
outputs = model.generate(inputs['input_ids'],
attention_mask=attention_mask, max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id, num_return_sequences=1)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
prompt = "What is the distance between the Earth and the Moon?"
generated_text = generate_text(prompt)
print(f"Generated Text: {generated_text}")It will generate output like the following:
Technical Insight: Implementing LLMs
This section will implement a text generation model using GPT-2, a renowned Large Language Model (LLM) developed by OpenAI. The code demonstrates integrating GPT-2 into a Python project to generate coherent and contextually relevant text based on a given input prompt. It includes steps for loading the GPT-2 model and tokenizer, configuring the necessary parameters for text generation (such as padding and truncation), and executing the model to produce a response. This example is a practical illustration of utilizing LLMs like GPT-2 for natural language processing tasks, showcasing their ability to understand and generate human-like text.
Follow these steps to execute it:
Import Required Libraries as shown below:
from transformers import GPT2Tokenizer, GPT2LMHeadModelGPT2Tokenizer: This converts input text into a format (tokens) that the model can understand.
GPT2LMHeadModel: This is the actual GPT-2 model which will generate the text.
Define the Text generation Method. The function, generate_text, is designed to take a prompt (input text) and generate a response based on this prompt.
model_name specifies which model to use, defaulting to 'gpt2'.
max_length controls the maximum length of the generated response, including the prompt length.
Load the model and tokenizer as shown below:
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)Set padding and truncation as shown below:
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_tokenThe tokenizer is configured to pad on the left side. This is important for decoder-only models like GPT-2.
The end-of-sequence token (eos_token) is used as the padding token if no pad token is set.
Encode the prompt. The prompt is encoded with encode_plus, which prepares it for the model.
return_tensors='pt' ensures the output is a PyTorch tensor, suitable for the model.
attention_mask is used to inform the model which parts of the input are actual words and which are padding.
It is shown below:
inputs = tokenizer.encode_plus(prompt, return_tensors='pt', max_length=max_length,
pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']Generate the response.
Decode the generated text.
This code can be run smoothly on Google Colab. The complete code is as follows:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
def generate_text(prompt, model_name='gpt2', max_length=100):
# Load pre-trained model tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# Set padding side and pad token
tokenizer.padding_side = 'left'
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = GPT2LMHeadModel.from_pretrained(model_name)
# Encode text input with truncation and left padding
inputs = tokenizer.encode_plus(prompt, return_tensors='pt',
max_length=max_length, pad_to_max_length=True, truncation=True)
attention_mask = inputs['attention_mask']
# Calculate new max_length for generation (prompt length +
max_new_tokens)
prompt_length = len(tokenizer.encode(prompt))
max_new_tokens = max_length - prompt_length
# Generate response
outputs = model.generate(inputs['input_ids'],
attention_mask=attention_mask, max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id, num_return_sequences=1)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
prompt = "What is the distance between the Earth and the Moon?"
generated_text = generate_text(prompt)
print(f"Generated Text: {generated_text}")It will generate output like the following:
Advanced Technical Challenges in LLMs
Large Language Models (LLMs) like GPT-3 have revolutionized how we interact with AI, but they also come with their own challenges. Let's dive into some of these advanced issues.
Tackling Computational Complexity and Efficiency
One of the biggest challenges with LLMs is their computational complexity. They have billions of parameters (the parts of the model that get adjusted during learning) and require significant computational power. Training such models is not just time-consuming but also incredibly expensive. It demands extensive hardware resources, typically involving powerful GPUs or TPUs. This limits who can work with these models – often only large organizations with substantial resources.
Moreover, the environmental impact of training and running these models must be addressed. The energy consumption is substantial, contributing to a larger carbon footprint. Researchers are continuously working on making these models more efficient. This includes efforts to compress the model without losing its effectiveness or developing new algorithms that can achieve the same results with less computational power.
Overcoming Data Scarcity and Quality Issues
Data is the fuel for LLMs. However, finding high-quality, diverse, and unbiased data is a significant challenge. Many LLMs are trained on data from the internet, which can include biased or inaccurate information. This means the model could generate outputs that are misleading or offensive. Moreover, for less common languages or specialized fields, there might need to be more data available for the model to learn effectively.
To combat this, LLM developers must diligently curate their datasets. They need to ensure a diverse and balanced range of data sources. Additionally, techniques like data augmentation (creating new data based on existing data) or transfer learning can help in scarce data.
Addressing Scalability and Maintenance Challenges
As LLMs grow in size and complexity, scalability becomes a significant concern. How do you ensure that the model can handle an increasing number of requests without performance degradation? Scalability is not just about hardware capabilities; it's also about the model's architecture. The model should be able to manage and process large amounts of data and requests efficiently.
Moreover, maintaining these models is a significant feat. They need to be continuously updated with new data to stay relevant. This is incredibly challenging in fast-changing fields like news or popular culture. There's also the challenge of monitoring the model's outputs to ensure they remain accurate and unbiased over time. This requires a combination of automated systems and human oversight.
Advanced Technical Challenges in LLMs
Large Language Models (LLMs) like GPT-3 have revolutionized how we interact with AI, but they also come with their own challenges. Let's dive into some of these advanced issues.
Tackling Computational Complexity and Efficiency
One of the biggest challenges with LLMs is their computational complexity. They have billions of parameters (the parts of the model that get adjusted during learning) and require significant computational power. Training such models is not just time-consuming but also incredibly expensive. It demands extensive hardware resources, typically involving powerful GPUs or TPUs. This limits who can work with these models – often only large organizations with substantial resources.
Moreover, the environmental impact of training and running these models must be addressed. The energy consumption is substantial, contributing to a larger carbon footprint. Researchers are continuously working on making these models more efficient. This includes efforts to compress the model without losing its effectiveness or developing new algorithms that can achieve the same results with less computational power.
Overcoming Data Scarcity and Quality Issues
Data is the fuel for LLMs. However, finding high-quality, diverse, and unbiased data is a significant challenge. Many LLMs are trained on data from the internet, which can include biased or inaccurate information. This means the model could generate outputs that are misleading or offensive. Moreover, for less common languages or specialized fields, there might need to be more data available for the model to learn effectively.
To combat this, LLM developers must diligently curate their datasets. They need to ensure a diverse and balanced range of data sources. Additionally, techniques like data augmentation (creating new data based on existing data) or transfer learning can help in scarce data.
Addressing Scalability and Maintenance Challenges
As LLMs grow in size and complexity, scalability becomes a significant concern. How do you ensure that the model can handle an increasing number of requests without performance degradation? Scalability is not just about hardware capabilities; it's also about the model's architecture. The model should be able to manage and process large amounts of data and requests efficiently.
Moreover, maintaining these models is a significant feat. They need to be continuously updated with new data to stay relevant. This is incredibly challenging in fast-changing fields like news or popular culture. There's also the challenge of monitoring the model's outputs to ensure they remain accurate and unbiased over time. This requires a combination of automated systems and human oversight.
Advanced Technical Challenges in LLMs
Large Language Models (LLMs) like GPT-3 have revolutionized how we interact with AI, but they also come with their own challenges. Let's dive into some of these advanced issues.
Tackling Computational Complexity and Efficiency
One of the biggest challenges with LLMs is their computational complexity. They have billions of parameters (the parts of the model that get adjusted during learning) and require significant computational power. Training such models is not just time-consuming but also incredibly expensive. It demands extensive hardware resources, typically involving powerful GPUs or TPUs. This limits who can work with these models – often only large organizations with substantial resources.
Moreover, the environmental impact of training and running these models must be addressed. The energy consumption is substantial, contributing to a larger carbon footprint. Researchers are continuously working on making these models more efficient. This includes efforts to compress the model without losing its effectiveness or developing new algorithms that can achieve the same results with less computational power.
Overcoming Data Scarcity and Quality Issues
Data is the fuel for LLMs. However, finding high-quality, diverse, and unbiased data is a significant challenge. Many LLMs are trained on data from the internet, which can include biased or inaccurate information. This means the model could generate outputs that are misleading or offensive. Moreover, for less common languages or specialized fields, there might need to be more data available for the model to learn effectively.
To combat this, LLM developers must diligently curate their datasets. They need to ensure a diverse and balanced range of data sources. Additionally, techniques like data augmentation (creating new data based on existing data) or transfer learning can help in scarce data.
Addressing Scalability and Maintenance Challenges
As LLMs grow in size and complexity, scalability becomes a significant concern. How do you ensure that the model can handle an increasing number of requests without performance degradation? Scalability is not just about hardware capabilities; it's also about the model's architecture. The model should be able to manage and process large amounts of data and requests efficiently.
Moreover, maintaining these models is a significant feat. They need to be continuously updated with new data to stay relevant. This is incredibly challenging in fast-changing fields like news or popular culture. There's also the challenge of monitoring the model's outputs to ensure they remain accurate and unbiased over time. This requires a combination of automated systems and human oversight.
Advanced Technical Challenges in LLMs
Large Language Models (LLMs) like GPT-3 have revolutionized how we interact with AI, but they also come with their own challenges. Let's dive into some of these advanced issues.
Tackling Computational Complexity and Efficiency
One of the biggest challenges with LLMs is their computational complexity. They have billions of parameters (the parts of the model that get adjusted during learning) and require significant computational power. Training such models is not just time-consuming but also incredibly expensive. It demands extensive hardware resources, typically involving powerful GPUs or TPUs. This limits who can work with these models – often only large organizations with substantial resources.
Moreover, the environmental impact of training and running these models must be addressed. The energy consumption is substantial, contributing to a larger carbon footprint. Researchers are continuously working on making these models more efficient. This includes efforts to compress the model without losing its effectiveness or developing new algorithms that can achieve the same results with less computational power.
Overcoming Data Scarcity and Quality Issues
Data is the fuel for LLMs. However, finding high-quality, diverse, and unbiased data is a significant challenge. Many LLMs are trained on data from the internet, which can include biased or inaccurate information. This means the model could generate outputs that are misleading or offensive. Moreover, for less common languages or specialized fields, there might need to be more data available for the model to learn effectively.
To combat this, LLM developers must diligently curate their datasets. They need to ensure a diverse and balanced range of data sources. Additionally, techniques like data augmentation (creating new data based on existing data) or transfer learning can help in scarce data.
Addressing Scalability and Maintenance Challenges
As LLMs grow in size and complexity, scalability becomes a significant concern. How do you ensure that the model can handle an increasing number of requests without performance degradation? Scalability is not just about hardware capabilities; it's also about the model's architecture. The model should be able to manage and process large amounts of data and requests efficiently.
Moreover, maintaining these models is a significant feat. They need to be continuously updated with new data to stay relevant. This is incredibly challenging in fast-changing fields like news or popular culture. There's also the challenge of monitoring the model's outputs to ensure they remain accurate and unbiased over time. This requires a combination of automated systems and human oversight.
Ethical Considerations and Challenges
As we embrace the advancements in Large Language Models (LLMs), navigating the ethical landscape that comes with them is crucial. Understanding and addressing the ethical challenges is critical to responsibly ensuring these technologies benefit society.
Navigating the Ethical Terrain of AI-Language Models
The development and use of AI language models bring up several ethical questions. One primary concern is privacy. LLMs are often trained on vast amounts of data, some of which can contain personal information. Ensuring this data is used responsibly and doesn't infringe on individual privacy rights is paramount. Additionally, there's the issue of transparency. Users need to understand how these models work and the basis of their decisions or outputs. Transparency is crucial in establishing trust.and accountability.
Another critical area is the potential misuse of these models. From generating fake news to creating realistic but false narratives, the power of LLMs can be exploited for unethical purposes. Therefore, setting robust guidelines and safeguards against such misuse is necessary.
Addressing Bias and Limitations in LLMs
Bias in AI reflects human bias. Since LLMs learn from existing data, they can inadvertently learn and perpetuate the biases present in that data. This might result in biased or prejudiced results, like stereotyping or discrimination. For example, suppose an LLM is trained predominantly on texts from a particular region or demographic. In that case, it might perform poorly for users outside that group, or worse, it could generate biased content.
Combating this requires a two-pronged approach. First, the data used to train these models must be as diverse and inclusive as possible. This involves including texts from different demographics and viewpoints and ensuring that underrepresented groups are adequately reflected.
Second, continuous monitoring and auditing of these models are crucial for detecting and correcting biases that might emerge over time. This could involve dedicated teams assessing the model outputs and user feedback to ensure fairness and inclusivity.
Finally, there are limitations in the technology itself. While LLMs are incredibly advanced, they need to truly 'understand' language or context in the human sense. They can generate plausible-sounding but factually incorrect or nonsensical content. Users must be aware of these limitations, especially in critical applications like healthcare or education, where false information could have serious consequences.
Ethical Considerations and Challenges
As we embrace the advancements in Large Language Models (LLMs), navigating the ethical landscape that comes with them is crucial. Understanding and addressing the ethical challenges is critical to responsibly ensuring these technologies benefit society.
Navigating the Ethical Terrain of AI-Language Models
The development and use of AI language models bring up several ethical questions. One primary concern is privacy. LLMs are often trained on vast amounts of data, some of which can contain personal information. Ensuring this data is used responsibly and doesn't infringe on individual privacy rights is paramount. Additionally, there's the issue of transparency. Users need to understand how these models work and the basis of their decisions or outputs. Transparency is crucial in establishing trust.and accountability.
Another critical area is the potential misuse of these models. From generating fake news to creating realistic but false narratives, the power of LLMs can be exploited for unethical purposes. Therefore, setting robust guidelines and safeguards against such misuse is necessary.
Addressing Bias and Limitations in LLMs
Bias in AI reflects human bias. Since LLMs learn from existing data, they can inadvertently learn and perpetuate the biases present in that data. This might result in biased or prejudiced results, like stereotyping or discrimination. For example, suppose an LLM is trained predominantly on texts from a particular region or demographic. In that case, it might perform poorly for users outside that group, or worse, it could generate biased content.
Combating this requires a two-pronged approach. First, the data used to train these models must be as diverse and inclusive as possible. This involves including texts from different demographics and viewpoints and ensuring that underrepresented groups are adequately reflected.
Second, continuous monitoring and auditing of these models are crucial for detecting and correcting biases that might emerge over time. This could involve dedicated teams assessing the model outputs and user feedback to ensure fairness and inclusivity.
Finally, there are limitations in the technology itself. While LLMs are incredibly advanced, they need to truly 'understand' language or context in the human sense. They can generate plausible-sounding but factually incorrect or nonsensical content. Users must be aware of these limitations, especially in critical applications like healthcare or education, where false information could have serious consequences.
Ethical Considerations and Challenges
As we embrace the advancements in Large Language Models (LLMs), navigating the ethical landscape that comes with them is crucial. Understanding and addressing the ethical challenges is critical to responsibly ensuring these technologies benefit society.
Navigating the Ethical Terrain of AI-Language Models
The development and use of AI language models bring up several ethical questions. One primary concern is privacy. LLMs are often trained on vast amounts of data, some of which can contain personal information. Ensuring this data is used responsibly and doesn't infringe on individual privacy rights is paramount. Additionally, there's the issue of transparency. Users need to understand how these models work and the basis of their decisions or outputs. Transparency is crucial in establishing trust.and accountability.
Another critical area is the potential misuse of these models. From generating fake news to creating realistic but false narratives, the power of LLMs can be exploited for unethical purposes. Therefore, setting robust guidelines and safeguards against such misuse is necessary.
Addressing Bias and Limitations in LLMs
Bias in AI reflects human bias. Since LLMs learn from existing data, they can inadvertently learn and perpetuate the biases present in that data. This might result in biased or prejudiced results, like stereotyping or discrimination. For example, suppose an LLM is trained predominantly on texts from a particular region or demographic. In that case, it might perform poorly for users outside that group, or worse, it could generate biased content.
Combating this requires a two-pronged approach. First, the data used to train these models must be as diverse and inclusive as possible. This involves including texts from different demographics and viewpoints and ensuring that underrepresented groups are adequately reflected.
Second, continuous monitoring and auditing of these models are crucial for detecting and correcting biases that might emerge over time. This could involve dedicated teams assessing the model outputs and user feedback to ensure fairness and inclusivity.
Finally, there are limitations in the technology itself. While LLMs are incredibly advanced, they need to truly 'understand' language or context in the human sense. They can generate plausible-sounding but factually incorrect or nonsensical content. Users must be aware of these limitations, especially in critical applications like healthcare or education, where false information could have serious consequences.
Ethical Considerations and Challenges
As we embrace the advancements in Large Language Models (LLMs), navigating the ethical landscape that comes with them is crucial. Understanding and addressing the ethical challenges is critical to responsibly ensuring these technologies benefit society.
Navigating the Ethical Terrain of AI-Language Models
The development and use of AI language models bring up several ethical questions. One primary concern is privacy. LLMs are often trained on vast amounts of data, some of which can contain personal information. Ensuring this data is used responsibly and doesn't infringe on individual privacy rights is paramount. Additionally, there's the issue of transparency. Users need to understand how these models work and the basis of their decisions or outputs. Transparency is crucial in establishing trust.and accountability.
Another critical area is the potential misuse of these models. From generating fake news to creating realistic but false narratives, the power of LLMs can be exploited for unethical purposes. Therefore, setting robust guidelines and safeguards against such misuse is necessary.
Addressing Bias and Limitations in LLMs
Bias in AI reflects human bias. Since LLMs learn from existing data, they can inadvertently learn and perpetuate the biases present in that data. This might result in biased or prejudiced results, like stereotyping or discrimination. For example, suppose an LLM is trained predominantly on texts from a particular region or demographic. In that case, it might perform poorly for users outside that group, or worse, it could generate biased content.
Combating this requires a two-pronged approach. First, the data used to train these models must be as diverse and inclusive as possible. This involves including texts from different demographics and viewpoints and ensuring that underrepresented groups are adequately reflected.
Second, continuous monitoring and auditing of these models are crucial for detecting and correcting biases that might emerge over time. This could involve dedicated teams assessing the model outputs and user feedback to ensure fairness and inclusivity.
Finally, there are limitations in the technology itself. While LLMs are incredibly advanced, they need to truly 'understand' language or context in the human sense. They can generate plausible-sounding but factually incorrect or nonsensical content. Users must be aware of these limitations, especially in critical applications like healthcare or education, where false information could have serious consequences.
Future Prospects and Technical Innovations
As we look ahead, the future of Large Language Models (LLMs) is brimming with exciting possibilities and groundbreaking innovations. Let's explore what's on the horizon for these powerful artificial intelligence tools.
Beyond the Present: Predicting the Future of LLMs
The future of LLMs is likely to be marked by even more advanced capabilities. We can expect these models to become better at understanding and replicating human-like conversations, making interactions with AI more natural and intuitive. This means that virtual assistants and chatbots will become more helpful and lifelike, capable of offering sophisticated support and companionship.
Another area of growth could be in personalized content creation. LLMs might soon be able to create highly customized books, articles, or learning materials tailored to an individual's interests and learning style. This could revolutionize education, making it more engaging and effective.
Emerging Trends and Potential Breakthroughs in LLM Technology
One of the most exciting trends in developing LLMs is their increasing ability to understand context and nuance. This means they'll be better at grasping the subtleties of language, including sarcasm, humor, and cultural references. This advancement will make AI-generated content more accurate and relatable.
We're also likely to see LLMs used more in research and development. They can help scientists and researchers by summarizing vast amounts of data, generating new hypotheses, or even writing research papers. This could accelerate scientific discovery in fields ranging from medicine to climate science.
Additionally, we can expect significant strides in making LLMs more efficient and less resource-intensive. This will make them more accessible, enabling smaller companies and individual developers to harness their power.
The Role of Quantum Computing in Advancing LLMs
Quantum computing promises to take LLMs to the next level. With their immense processing power, Quantum computers could drastically reduce the time and resources needed to train these models. They might enable LLMs to analyze data sets that are currently too large and complex to handle.
Furthermore, quantum computing could enhance the ability of LLMs to find patterns and make predictions, potentially leading to breakthroughs in how we use AI for problem-solving and decision-making. This could open new frontiers in personalized medicine, financial modeling, and more.
Future Prospects and Technical Innovations
As we look ahead, the future of Large Language Models (LLMs) is brimming with exciting possibilities and groundbreaking innovations. Let's explore what's on the horizon for these powerful artificial intelligence tools.
Beyond the Present: Predicting the Future of LLMs
The future of LLMs is likely to be marked by even more advanced capabilities. We can expect these models to become better at understanding and replicating human-like conversations, making interactions with AI more natural and intuitive. This means that virtual assistants and chatbots will become more helpful and lifelike, capable of offering sophisticated support and companionship.
Another area of growth could be in personalized content creation. LLMs might soon be able to create highly customized books, articles, or learning materials tailored to an individual's interests and learning style. This could revolutionize education, making it more engaging and effective.
Emerging Trends and Potential Breakthroughs in LLM Technology
One of the most exciting trends in developing LLMs is their increasing ability to understand context and nuance. This means they'll be better at grasping the subtleties of language, including sarcasm, humor, and cultural references. This advancement will make AI-generated content more accurate and relatable.
We're also likely to see LLMs used more in research and development. They can help scientists and researchers by summarizing vast amounts of data, generating new hypotheses, or even writing research papers. This could accelerate scientific discovery in fields ranging from medicine to climate science.
Additionally, we can expect significant strides in making LLMs more efficient and less resource-intensive. This will make them more accessible, enabling smaller companies and individual developers to harness their power.
The Role of Quantum Computing in Advancing LLMs
Quantum computing promises to take LLMs to the next level. With their immense processing power, Quantum computers could drastically reduce the time and resources needed to train these models. They might enable LLMs to analyze data sets that are currently too large and complex to handle.
Furthermore, quantum computing could enhance the ability of LLMs to find patterns and make predictions, potentially leading to breakthroughs in how we use AI for problem-solving and decision-making. This could open new frontiers in personalized medicine, financial modeling, and more.
Future Prospects and Technical Innovations
As we look ahead, the future of Large Language Models (LLMs) is brimming with exciting possibilities and groundbreaking innovations. Let's explore what's on the horizon for these powerful artificial intelligence tools.
Beyond the Present: Predicting the Future of LLMs
The future of LLMs is likely to be marked by even more advanced capabilities. We can expect these models to become better at understanding and replicating human-like conversations, making interactions with AI more natural and intuitive. This means that virtual assistants and chatbots will become more helpful and lifelike, capable of offering sophisticated support and companionship.
Another area of growth could be in personalized content creation. LLMs might soon be able to create highly customized books, articles, or learning materials tailored to an individual's interests and learning style. This could revolutionize education, making it more engaging and effective.
Emerging Trends and Potential Breakthroughs in LLM Technology
One of the most exciting trends in developing LLMs is their increasing ability to understand context and nuance. This means they'll be better at grasping the subtleties of language, including sarcasm, humor, and cultural references. This advancement will make AI-generated content more accurate and relatable.
We're also likely to see LLMs used more in research and development. They can help scientists and researchers by summarizing vast amounts of data, generating new hypotheses, or even writing research papers. This could accelerate scientific discovery in fields ranging from medicine to climate science.
Additionally, we can expect significant strides in making LLMs more efficient and less resource-intensive. This will make them more accessible, enabling smaller companies and individual developers to harness their power.
The Role of Quantum Computing in Advancing LLMs
Quantum computing promises to take LLMs to the next level. With their immense processing power, Quantum computers could drastically reduce the time and resources needed to train these models. They might enable LLMs to analyze data sets that are currently too large and complex to handle.
Furthermore, quantum computing could enhance the ability of LLMs to find patterns and make predictions, potentially leading to breakthroughs in how we use AI for problem-solving and decision-making. This could open new frontiers in personalized medicine, financial modeling, and more.
Future Prospects and Technical Innovations
As we look ahead, the future of Large Language Models (LLMs) is brimming with exciting possibilities and groundbreaking innovations. Let's explore what's on the horizon for these powerful artificial intelligence tools.
Beyond the Present: Predicting the Future of LLMs
The future of LLMs is likely to be marked by even more advanced capabilities. We can expect these models to become better at understanding and replicating human-like conversations, making interactions with AI more natural and intuitive. This means that virtual assistants and chatbots will become more helpful and lifelike, capable of offering sophisticated support and companionship.
Another area of growth could be in personalized content creation. LLMs might soon be able to create highly customized books, articles, or learning materials tailored to an individual's interests and learning style. This could revolutionize education, making it more engaging and effective.
Emerging Trends and Potential Breakthroughs in LLM Technology
One of the most exciting trends in developing LLMs is their increasing ability to understand context and nuance. This means they'll be better at grasping the subtleties of language, including sarcasm, humor, and cultural references. This advancement will make AI-generated content more accurate and relatable.
We're also likely to see LLMs used more in research and development. They can help scientists and researchers by summarizing vast amounts of data, generating new hypotheses, or even writing research papers. This could accelerate scientific discovery in fields ranging from medicine to climate science.
Additionally, we can expect significant strides in making LLMs more efficient and less resource-intensive. This will make them more accessible, enabling smaller companies and individual developers to harness their power.
The Role of Quantum Computing in Advancing LLMs
Quantum computing promises to take LLMs to the next level. With their immense processing power, Quantum computers could drastically reduce the time and resources needed to train these models. They might enable LLMs to analyze data sets that are currently too large and complex to handle.
Furthermore, quantum computing could enhance the ability of LLMs to find patterns and make predictions, potentially leading to breakthroughs in how we use AI for problem-solving and decision-making. This could open new frontiers in personalized medicine, financial modeling, and more.
Conclusion
In conclusion, the journey of Large Language Models (LLMs) has been remarkable, showcasing a significant evolution from basic rule-based systems to advanced neural network architectures like RNNs, CNNs, and Transformers. These powerful models have revolutionized various sectors by enhancing business operations, creative content generation, scientific research, and customer interactions. While they offer immense potential, LLMs also pose technical challenges related to computational efficiency, data handling, scalability, and maintenance. Moreover, ethical considerations like addressing biases and ensuring privacy and transparency remain crucial. The incorporation of cutting-edge technologies, like quantum computing, promises to advance the capabilities of LLMs further. As we refine these models, the quest for AI language excellence is set to unlock unprecedented possibilities, shaping the future of how we interact and benefit from artificial intelligence.
Conclusion
In conclusion, the journey of Large Language Models (LLMs) has been remarkable, showcasing a significant evolution from basic rule-based systems to advanced neural network architectures like RNNs, CNNs, and Transformers. These powerful models have revolutionized various sectors by enhancing business operations, creative content generation, scientific research, and customer interactions. While they offer immense potential, LLMs also pose technical challenges related to computational efficiency, data handling, scalability, and maintenance. Moreover, ethical considerations like addressing biases and ensuring privacy and transparency remain crucial. The incorporation of cutting-edge technologies, like quantum computing, promises to advance the capabilities of LLMs further. As we refine these models, the quest for AI language excellence is set to unlock unprecedented possibilities, shaping the future of how we interact and benefit from artificial intelligence.
Conclusion
In conclusion, the journey of Large Language Models (LLMs) has been remarkable, showcasing a significant evolution from basic rule-based systems to advanced neural network architectures like RNNs, CNNs, and Transformers. These powerful models have revolutionized various sectors by enhancing business operations, creative content generation, scientific research, and customer interactions. While they offer immense potential, LLMs also pose technical challenges related to computational efficiency, data handling, scalability, and maintenance. Moreover, ethical considerations like addressing biases and ensuring privacy and transparency remain crucial. The incorporation of cutting-edge technologies, like quantum computing, promises to advance the capabilities of LLMs further. As we refine these models, the quest for AI language excellence is set to unlock unprecedented possibilities, shaping the future of how we interact and benefit from artificial intelligence.
Conclusion
In conclusion, the journey of Large Language Models (LLMs) has been remarkable, showcasing a significant evolution from basic rule-based systems to advanced neural network architectures like RNNs, CNNs, and Transformers. These powerful models have revolutionized various sectors by enhancing business operations, creative content generation, scientific research, and customer interactions. While they offer immense potential, LLMs also pose technical challenges related to computational efficiency, data handling, scalability, and maintenance. Moreover, ethical considerations like addressing biases and ensuring privacy and transparency remain crucial. The incorporation of cutting-edge technologies, like quantum computing, promises to advance the capabilities of LLMs further. As we refine these models, the quest for AI language excellence is set to unlock unprecedented possibilities, shaping the future of how we interact and benefit from artificial intelligence.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.