Annotab Studio 2.0.0 is now live
Mastering RLHF: Technical Strategies in Human Feedback Reinforcement Learning
Mastering RLHF: Technical Strategies in Human Feedback Reinforcement Learning
Mastering RLHF: Technical Strategies in Human Feedback Reinforcement Learning
Mastering RLHF: Technical Strategies in Human Feedback Reinforcement Learning
Published by

Osama Akhlaq
on
Feb 8, 2024
under
Deep Learning
Published by
Osama Akhlaq
on
Feb 8, 2024
under
Deep Learning
Published by
Osama Akhlaq
on
Feb 8, 2024
under
Deep Learning
Published by
Osama Akhlaq
on
Feb 8, 2024
under
Deep Learning
ON THIS PAGE
Tl;dr
Discover how Reinforcement Learning from Human Feedback (RLHF) merges AI with human insight, driving innovation and ethical AI development across sectors.
Tl;dr
Discover how Reinforcement Learning from Human Feedback (RLHF) merges AI with human insight, driving innovation and ethical AI development across sectors.
Tl;dr
Discover how Reinforcement Learning from Human Feedback (RLHF) merges AI with human insight, driving innovation and ethical AI development across sectors.
Tl;dr
Discover how Reinforcement Learning from Human Feedback (RLHF) merges AI with human insight, driving innovation and ethical AI development across sectors.

Introduction
Reinforcement Learning from Human Feedback (RLHF) marks a significant advancement in training artificial intelligence. In traditional reinforcement learning, AI systems learn from trial and error, shaping their actions based on rewards or penalties. RLHF introduces a novel twist: human insight becomes part of this learning process. Simply put, RLHF blends human feedback into the AI's training regimen, allowing it to learn from its interactions with the environment and human guidance.
Significance in Contemporary AI Landscape
In today's AI landscape, RLHF stands out as a crucial development. Why? Because it bridges a critical gap between human intuition and AI's computational power. Human feedback helps AI understand complex, nuanced tasks that are challenging to quantify with simple reward systems. This fusion of human intelligence and machine efficiency opens doors to more refined, sensitive, and adaptable AI applications. From more innovative chatbots to more intuitive recommendation systems, RLHF is pushing the boundaries of what AI can achieve, making it a game-changer.
Historical Background and Evolution
Journey from Classic Reinforcement Learning to RLHF
The story of Reinforcement Learning from Human Feedback (RLHF) begins with classic reinforcement learning (RL), a method where AI learns by doing. In traditional RL, an AI tries different actions, knowing which leads to the best outcomes or rewards. It's like teaching a child to ride a bike - they fall, get up, and try again until they find balance.
But RL had its limits. It worked well for straightforward tasks, like chess, but struggled with complex, human-like decisions. This is where RLHF stepped in. Imagine now teaching that child not just to ride a bike but to navigate a busy street. You wouldn't just watch; you'd guide them, offer tips, and correct their course. That's what RLHF does. It adds a human touch to the learning process, teaching AI in situations where right and wrong aren't clear-cut.
Key Developments and Influential Research
The evolution to RLHF took time to happen. Key developments and pivotal research fueled it. One landmark moment was when researchers started incorporating human-generated data into AI training, showing that AI could learn from human demonstrations and advice. Another significant advancement came with developing algorithms that could interpret and integrate human feedback effectively, making RL more flexible and adaptive.
Influential research papers have highlighted the success of RLHF in various applications, from language models understanding human nuances to robots learning complex physical tasks. These studies have showcased the potential of RLHF and paved the way for continuous innovation in this field.
In short, the journey from classic RL to RLHF has been about making AI more intelligent and more attuned to the complexities of human thought and behaviour. This evolution marks a significant leap forward in our quest to create AI that can truly understand and interact with the world in a human-like way.
Introduction
Reinforcement Learning from Human Feedback (RLHF) marks a significant advancement in training artificial intelligence. In traditional reinforcement learning, AI systems learn from trial and error, shaping their actions based on rewards or penalties. RLHF introduces a novel twist: human insight becomes part of this learning process. Simply put, RLHF blends human feedback into the AI's training regimen, allowing it to learn from its interactions with the environment and human guidance.
Significance in Contemporary AI Landscape
In today's AI landscape, RLHF stands out as a crucial development. Why? Because it bridges a critical gap between human intuition and AI's computational power. Human feedback helps AI understand complex, nuanced tasks that are challenging to quantify with simple reward systems. This fusion of human intelligence and machine efficiency opens doors to more refined, sensitive, and adaptable AI applications. From more innovative chatbots to more intuitive recommendation systems, RLHF is pushing the boundaries of what AI can achieve, making it a game-changer.
Historical Background and Evolution
Journey from Classic Reinforcement Learning to RLHF
The story of Reinforcement Learning from Human Feedback (RLHF) begins with classic reinforcement learning (RL), a method where AI learns by doing. In traditional RL, an AI tries different actions, knowing which leads to the best outcomes or rewards. It's like teaching a child to ride a bike - they fall, get up, and try again until they find balance.
But RL had its limits. It worked well for straightforward tasks, like chess, but struggled with complex, human-like decisions. This is where RLHF stepped in. Imagine now teaching that child not just to ride a bike but to navigate a busy street. You wouldn't just watch; you'd guide them, offer tips, and correct their course. That's what RLHF does. It adds a human touch to the learning process, teaching AI in situations where right and wrong aren't clear-cut.
Key Developments and Influential Research
The evolution to RLHF took time to happen. Key developments and pivotal research fueled it. One landmark moment was when researchers started incorporating human-generated data into AI training, showing that AI could learn from human demonstrations and advice. Another significant advancement came with developing algorithms that could interpret and integrate human feedback effectively, making RL more flexible and adaptive.
Influential research papers have highlighted the success of RLHF in various applications, from language models understanding human nuances to robots learning complex physical tasks. These studies have showcased the potential of RLHF and paved the way for continuous innovation in this field.
In short, the journey from classic RL to RLHF has been about making AI more intelligent and more attuned to the complexities of human thought and behaviour. This evolution marks a significant leap forward in our quest to create AI that can truly understand and interact with the world in a human-like way.
Introduction
Reinforcement Learning from Human Feedback (RLHF) marks a significant advancement in training artificial intelligence. In traditional reinforcement learning, AI systems learn from trial and error, shaping their actions based on rewards or penalties. RLHF introduces a novel twist: human insight becomes part of this learning process. Simply put, RLHF blends human feedback into the AI's training regimen, allowing it to learn from its interactions with the environment and human guidance.
Significance in Contemporary AI Landscape
In today's AI landscape, RLHF stands out as a crucial development. Why? Because it bridges a critical gap between human intuition and AI's computational power. Human feedback helps AI understand complex, nuanced tasks that are challenging to quantify with simple reward systems. This fusion of human intelligence and machine efficiency opens doors to more refined, sensitive, and adaptable AI applications. From more innovative chatbots to more intuitive recommendation systems, RLHF is pushing the boundaries of what AI can achieve, making it a game-changer.
Historical Background and Evolution
Journey from Classic Reinforcement Learning to RLHF
The story of Reinforcement Learning from Human Feedback (RLHF) begins with classic reinforcement learning (RL), a method where AI learns by doing. In traditional RL, an AI tries different actions, knowing which leads to the best outcomes or rewards. It's like teaching a child to ride a bike - they fall, get up, and try again until they find balance.
But RL had its limits. It worked well for straightforward tasks, like chess, but struggled with complex, human-like decisions. This is where RLHF stepped in. Imagine now teaching that child not just to ride a bike but to navigate a busy street. You wouldn't just watch; you'd guide them, offer tips, and correct their course. That's what RLHF does. It adds a human touch to the learning process, teaching AI in situations where right and wrong aren't clear-cut.
Key Developments and Influential Research
The evolution to RLHF took time to happen. Key developments and pivotal research fueled it. One landmark moment was when researchers started incorporating human-generated data into AI training, showing that AI could learn from human demonstrations and advice. Another significant advancement came with developing algorithms that could interpret and integrate human feedback effectively, making RL more flexible and adaptive.
Influential research papers have highlighted the success of RLHF in various applications, from language models understanding human nuances to robots learning complex physical tasks. These studies have showcased the potential of RLHF and paved the way for continuous innovation in this field.
In short, the journey from classic RL to RLHF has been about making AI more intelligent and more attuned to the complexities of human thought and behaviour. This evolution marks a significant leap forward in our quest to create AI that can truly understand and interact with the world in a human-like way.
Introduction
Reinforcement Learning from Human Feedback (RLHF) marks a significant advancement in training artificial intelligence. In traditional reinforcement learning, AI systems learn from trial and error, shaping their actions based on rewards or penalties. RLHF introduces a novel twist: human insight becomes part of this learning process. Simply put, RLHF blends human feedback into the AI's training regimen, allowing it to learn from its interactions with the environment and human guidance.
Significance in Contemporary AI Landscape
In today's AI landscape, RLHF stands out as a crucial development. Why? Because it bridges a critical gap between human intuition and AI's computational power. Human feedback helps AI understand complex, nuanced tasks that are challenging to quantify with simple reward systems. This fusion of human intelligence and machine efficiency opens doors to more refined, sensitive, and adaptable AI applications. From more innovative chatbots to more intuitive recommendation systems, RLHF is pushing the boundaries of what AI can achieve, making it a game-changer.
Historical Background and Evolution
Journey from Classic Reinforcement Learning to RLHF
The story of Reinforcement Learning from Human Feedback (RLHF) begins with classic reinforcement learning (RL), a method where AI learns by doing. In traditional RL, an AI tries different actions, knowing which leads to the best outcomes or rewards. It's like teaching a child to ride a bike - they fall, get up, and try again until they find balance.
But RL had its limits. It worked well for straightforward tasks, like chess, but struggled with complex, human-like decisions. This is where RLHF stepped in. Imagine now teaching that child not just to ride a bike but to navigate a busy street. You wouldn't just watch; you'd guide them, offer tips, and correct their course. That's what RLHF does. It adds a human touch to the learning process, teaching AI in situations where right and wrong aren't clear-cut.
Key Developments and Influential Research
The evolution to RLHF took time to happen. Key developments and pivotal research fueled it. One landmark moment was when researchers started incorporating human-generated data into AI training, showing that AI could learn from human demonstrations and advice. Another significant advancement came with developing algorithms that could interpret and integrate human feedback effectively, making RL more flexible and adaptive.
Influential research papers have highlighted the success of RLHF in various applications, from language models understanding human nuances to robots learning complex physical tasks. These studies have showcased the potential of RLHF and paved the way for continuous innovation in this field.
In short, the journey from classic RL to RLHF has been about making AI more intelligent and more attuned to the complexities of human thought and behaviour. This evolution marks a significant leap forward in our quest to create AI that can truly understand and interact with the world in a human-like way.
Understanding the Fundamentals of RLHF
Core Principles and Terminologies
Fundamental principles and terms that make it tick are at the heart of Reinforcement Learning from Human Feedback (RLHF). Let's break them down into more straightforward concepts.
First, we have Reinforcement Learning (RL). Think of RL like training a pet: when it does something good, it gets a treat; when it doesn't, there is no joy. This is how RL teaches AI to make decisions - actions leading to good outcomes are rewarded, and others are not.
Now, introduce Human Feedback into the mix. This is where RLHF changes the game. Imagine now you're rewarding the pet with treats and guiding it with commands or gestures. In RLHF, humans provide this extra layer of guidance. They can tell the AI, "This is good," or "Try something else," helping it learn more effectively.
Another key term in RLHF is Reward Function. This rulebook tells the AI what's good (gets a reward) and what's not. In RLHF, this rulebook is partly written by human feedback, making it more aligned with how humans think and act.
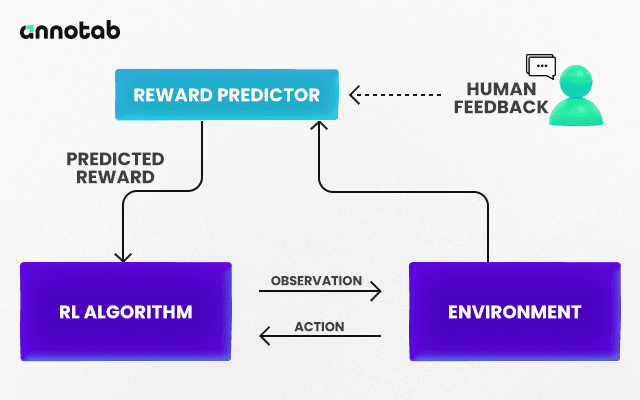
The Integration of Human Feedback
Integrating human feedback into RL is like adding a wise coach to AI training. This coach (the human feedback) doesn't just give rewards but also explains why something is rewarded. It makes the AI's learning process more like how we learn from teachers or mentors.
For instance, instead of the AI just learning to score points in a game, with human feedback, it can learn to play pretty, make strategic moves, or even develop a playing style. Human feedback helps AI understand the nuances and context that pure data can't fully capture in more complex tasks, like moderating online content.
This integration is done through various methods:
Demonstrations: Where humans show the AI how to perform tasks.
Preferences: Humans provide choices between different AI actions.
Annotations: Adding human insights or corrections to AI's decisions.
By blending human insights with AI learning, RLHF creates a powerful synergy. It enables AI to perform tasks and understand and adapt to the complexities of human values and contexts, leading to more innovative and more sensitive AI solutions.
Understanding the Fundamentals of RLHF
Core Principles and Terminologies
Fundamental principles and terms that make it tick are at the heart of Reinforcement Learning from Human Feedback (RLHF). Let's break them down into more straightforward concepts.
First, we have Reinforcement Learning (RL). Think of RL like training a pet: when it does something good, it gets a treat; when it doesn't, there is no joy. This is how RL teaches AI to make decisions - actions leading to good outcomes are rewarded, and others are not.
Now, introduce Human Feedback into the mix. This is where RLHF changes the game. Imagine now you're rewarding the pet with treats and guiding it with commands or gestures. In RLHF, humans provide this extra layer of guidance. They can tell the AI, "This is good," or "Try something else," helping it learn more effectively.
Another key term in RLHF is Reward Function. This rulebook tells the AI what's good (gets a reward) and what's not. In RLHF, this rulebook is partly written by human feedback, making it more aligned with how humans think and act.
The Integration of Human Feedback
Integrating human feedback into RL is like adding a wise coach to AI training. This coach (the human feedback) doesn't just give rewards but also explains why something is rewarded. It makes the AI's learning process more like how we learn from teachers or mentors.
For instance, instead of the AI just learning to score points in a game, with human feedback, it can learn to play pretty, make strategic moves, or even develop a playing style. Human feedback helps AI understand the nuances and context that pure data can't fully capture in more complex tasks, like moderating online content.
This integration is done through various methods:
Demonstrations: Where humans show the AI how to perform tasks.
Preferences: Humans provide choices between different AI actions.
Annotations: Adding human insights or corrections to AI's decisions.
By blending human insights with AI learning, RLHF creates a powerful synergy. It enables AI to perform tasks and understand and adapt to the complexities of human values and contexts, leading to more innovative and more sensitive AI solutions.
Understanding the Fundamentals of RLHF
Core Principles and Terminologies
Fundamental principles and terms that make it tick are at the heart of Reinforcement Learning from Human Feedback (RLHF). Let's break them down into more straightforward concepts.
First, we have Reinforcement Learning (RL). Think of RL like training a pet: when it does something good, it gets a treat; when it doesn't, there is no joy. This is how RL teaches AI to make decisions - actions leading to good outcomes are rewarded, and others are not.
Now, introduce Human Feedback into the mix. This is where RLHF changes the game. Imagine now you're rewarding the pet with treats and guiding it with commands or gestures. In RLHF, humans provide this extra layer of guidance. They can tell the AI, "This is good," or "Try something else," helping it learn more effectively.
Another key term in RLHF is Reward Function. This rulebook tells the AI what's good (gets a reward) and what's not. In RLHF, this rulebook is partly written by human feedback, making it more aligned with how humans think and act.
The Integration of Human Feedback
Integrating human feedback into RL is like adding a wise coach to AI training. This coach (the human feedback) doesn't just give rewards but also explains why something is rewarded. It makes the AI's learning process more like how we learn from teachers or mentors.
For instance, instead of the AI just learning to score points in a game, with human feedback, it can learn to play pretty, make strategic moves, or even develop a playing style. Human feedback helps AI understand the nuances and context that pure data can't fully capture in more complex tasks, like moderating online content.
This integration is done through various methods:
Demonstrations: Where humans show the AI how to perform tasks.
Preferences: Humans provide choices between different AI actions.
Annotations: Adding human insights or corrections to AI's decisions.
By blending human insights with AI learning, RLHF creates a powerful synergy. It enables AI to perform tasks and understand and adapt to the complexities of human values and contexts, leading to more innovative and more sensitive AI solutions.
Understanding the Fundamentals of RLHF
Core Principles and Terminologies
Fundamental principles and terms that make it tick are at the heart of Reinforcement Learning from Human Feedback (RLHF). Let's break them down into more straightforward concepts.
First, we have Reinforcement Learning (RL). Think of RL like training a pet: when it does something good, it gets a treat; when it doesn't, there is no joy. This is how RL teaches AI to make decisions - actions leading to good outcomes are rewarded, and others are not.
Now, introduce Human Feedback into the mix. This is where RLHF changes the game. Imagine now you're rewarding the pet with treats and guiding it with commands or gestures. In RLHF, humans provide this extra layer of guidance. They can tell the AI, "This is good," or "Try something else," helping it learn more effectively.
Another key term in RLHF is Reward Function. This rulebook tells the AI what's good (gets a reward) and what's not. In RLHF, this rulebook is partly written by human feedback, making it more aligned with how humans think and act.
The Integration of Human Feedback
Integrating human feedback into RL is like adding a wise coach to AI training. This coach (the human feedback) doesn't just give rewards but also explains why something is rewarded. It makes the AI's learning process more like how we learn from teachers or mentors.
For instance, instead of the AI just learning to score points in a game, with human feedback, it can learn to play pretty, make strategic moves, or even develop a playing style. Human feedback helps AI understand the nuances and context that pure data can't fully capture in more complex tasks, like moderating online content.
This integration is done through various methods:
Demonstrations: Where humans show the AI how to perform tasks.
Preferences: Humans provide choices between different AI actions.
Annotations: Adding human insights or corrections to AI's decisions.
By blending human insights with AI learning, RLHF creates a powerful synergy. It enables AI to perform tasks and understand and adapt to the complexities of human values and contexts, leading to more innovative and more sensitive AI solutions.
Technical Strategies and Algorithmic Implementations
Algorithmic Approaches in RLHF
Regarding Reinforcement Learning from Human Feedback (RLHF), several algorithmic approaches play a pivotal role. These algorithms are like the engine under the hood, driving the AI's ability to learn from its experiences and human guidance.
One notable algorithm is Inverse Reinforcement Learning (IRL). Imagine you're trying to learn cooking by watching a skilled chef. You're not just replicating their recipes; you're trying to grasp their techniques and flavour combinations. That's what Inverse Reinforcement Learning (IRL) does in the context of RLHF. It allows AI to observe human actions - in this case, the chef's cooking methods - and infer the underlying principles or 'rules' that guide these actions. The AI learns not just to cook a specific dish but also understands why certain ingredients are paired together, why some spices are used sparingly, and how cooking times vary for different textures and flavors. This understanding enables the AI to apply these principles to new and varied cooking scenarios, like how a skilled chef can create new recipes based on foundational culinary knowledge.
Another key algorithm is Deep Q-Networks (DQN) with human feedback integration. DQN is like a complex maze-solving technique where the AI learns which paths lead to rewards. By adding human feedback, the AI doesn't just find any way to the tip; it finds the best one according to human judgment.
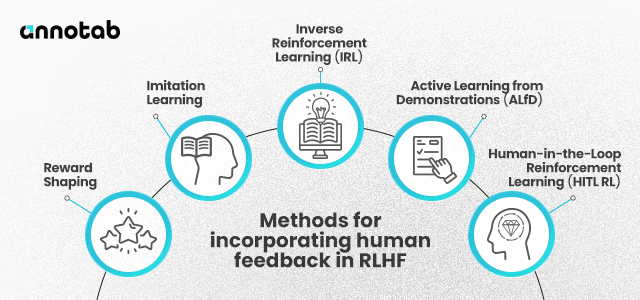
Designing and Modifying Reward Functions
The reward function in RLHF is crucial. It's like a set of instructions that guides the AI on what to aim for. But with RLHF, these instructions are dynamic, evolving with human input. Designing and modifying these reward functions is a delicate balancing act.
One approach is using Preference-Based Reinforcement Learning. Here, the AI is presented with scenarios and learns, which aligns more with human preferences. This method helps fine-tune the AI's decisions, ensuring they're practical and align with human values.
Balancing AI Autonomy and Human Input
Finding the sweet spot between AI making its own decisions and being guided by human feedback is vital in RLHF. It's similar to showing someone how to ride a bike. Initially, you might hold the bike, but eventually, you let go so they can ride independently. Similarly, RLHF aims to strike a balance where the AI is autonomous yet still benefits from human wisdom.
To achieve this, algorithms like Human-In-The-Loop Reinforcement Learning are used. Here, human feedback isn't constant but is provided at crucial learning stages or when the AI faces uncertain situations. This approach ensures the AI is not overly dependent on human input but still benefits from it when necessary.
Thus, the technical strategies in RLHF involve sophisticated algorithms that enable AI to learn from human feedback and ensure that this learning is aligned with human values and intuition. These strategies make AI systems more adaptable, ethical, and effective in handling real-world tasks.
Technical Strategies and Algorithmic Implementations
Algorithmic Approaches in RLHF
Regarding Reinforcement Learning from Human Feedback (RLHF), several algorithmic approaches play a pivotal role. These algorithms are like the engine under the hood, driving the AI's ability to learn from its experiences and human guidance.
One notable algorithm is Inverse Reinforcement Learning (IRL). Imagine you're trying to learn cooking by watching a skilled chef. You're not just replicating their recipes; you're trying to grasp their techniques and flavour combinations. That's what Inverse Reinforcement Learning (IRL) does in the context of RLHF. It allows AI to observe human actions - in this case, the chef's cooking methods - and infer the underlying principles or 'rules' that guide these actions. The AI learns not just to cook a specific dish but also understands why certain ingredients are paired together, why some spices are used sparingly, and how cooking times vary for different textures and flavors. This understanding enables the AI to apply these principles to new and varied cooking scenarios, like how a skilled chef can create new recipes based on foundational culinary knowledge.
Another key algorithm is Deep Q-Networks (DQN) with human feedback integration. DQN is like a complex maze-solving technique where the AI learns which paths lead to rewards. By adding human feedback, the AI doesn't just find any way to the tip; it finds the best one according to human judgment.
Designing and Modifying Reward Functions
The reward function in RLHF is crucial. It's like a set of instructions that guides the AI on what to aim for. But with RLHF, these instructions are dynamic, evolving with human input. Designing and modifying these reward functions is a delicate balancing act.
One approach is using Preference-Based Reinforcement Learning. Here, the AI is presented with scenarios and learns, which aligns more with human preferences. This method helps fine-tune the AI's decisions, ensuring they're practical and align with human values.
Balancing AI Autonomy and Human Input
Finding the sweet spot between AI making its own decisions and being guided by human feedback is vital in RLHF. It's similar to showing someone how to ride a bike. Initially, you might hold the bike, but eventually, you let go so they can ride independently. Similarly, RLHF aims to strike a balance where the AI is autonomous yet still benefits from human wisdom.
To achieve this, algorithms like Human-In-The-Loop Reinforcement Learning are used. Here, human feedback isn't constant but is provided at crucial learning stages or when the AI faces uncertain situations. This approach ensures the AI is not overly dependent on human input but still benefits from it when necessary.
Thus, the technical strategies in RLHF involve sophisticated algorithms that enable AI to learn from human feedback and ensure that this learning is aligned with human values and intuition. These strategies make AI systems more adaptable, ethical, and effective in handling real-world tasks.
Technical Strategies and Algorithmic Implementations
Algorithmic Approaches in RLHF
Regarding Reinforcement Learning from Human Feedback (RLHF), several algorithmic approaches play a pivotal role. These algorithms are like the engine under the hood, driving the AI's ability to learn from its experiences and human guidance.
One notable algorithm is Inverse Reinforcement Learning (IRL). Imagine you're trying to learn cooking by watching a skilled chef. You're not just replicating their recipes; you're trying to grasp their techniques and flavour combinations. That's what Inverse Reinforcement Learning (IRL) does in the context of RLHF. It allows AI to observe human actions - in this case, the chef's cooking methods - and infer the underlying principles or 'rules' that guide these actions. The AI learns not just to cook a specific dish but also understands why certain ingredients are paired together, why some spices are used sparingly, and how cooking times vary for different textures and flavors. This understanding enables the AI to apply these principles to new and varied cooking scenarios, like how a skilled chef can create new recipes based on foundational culinary knowledge.
Another key algorithm is Deep Q-Networks (DQN) with human feedback integration. DQN is like a complex maze-solving technique where the AI learns which paths lead to rewards. By adding human feedback, the AI doesn't just find any way to the tip; it finds the best one according to human judgment.
Designing and Modifying Reward Functions
The reward function in RLHF is crucial. It's like a set of instructions that guides the AI on what to aim for. But with RLHF, these instructions are dynamic, evolving with human input. Designing and modifying these reward functions is a delicate balancing act.
One approach is using Preference-Based Reinforcement Learning. Here, the AI is presented with scenarios and learns, which aligns more with human preferences. This method helps fine-tune the AI's decisions, ensuring they're practical and align with human values.
Balancing AI Autonomy and Human Input
Finding the sweet spot between AI making its own decisions and being guided by human feedback is vital in RLHF. It's similar to showing someone how to ride a bike. Initially, you might hold the bike, but eventually, you let go so they can ride independently. Similarly, RLHF aims to strike a balance where the AI is autonomous yet still benefits from human wisdom.
To achieve this, algorithms like Human-In-The-Loop Reinforcement Learning are used. Here, human feedback isn't constant but is provided at crucial learning stages or when the AI faces uncertain situations. This approach ensures the AI is not overly dependent on human input but still benefits from it when necessary.
Thus, the technical strategies in RLHF involve sophisticated algorithms that enable AI to learn from human feedback and ensure that this learning is aligned with human values and intuition. These strategies make AI systems more adaptable, ethical, and effective in handling real-world tasks.
Technical Strategies and Algorithmic Implementations
Algorithmic Approaches in RLHF
Regarding Reinforcement Learning from Human Feedback (RLHF), several algorithmic approaches play a pivotal role. These algorithms are like the engine under the hood, driving the AI's ability to learn from its experiences and human guidance.
One notable algorithm is Inverse Reinforcement Learning (IRL). Imagine you're trying to learn cooking by watching a skilled chef. You're not just replicating their recipes; you're trying to grasp their techniques and flavour combinations. That's what Inverse Reinforcement Learning (IRL) does in the context of RLHF. It allows AI to observe human actions - in this case, the chef's cooking methods - and infer the underlying principles or 'rules' that guide these actions. The AI learns not just to cook a specific dish but also understands why certain ingredients are paired together, why some spices are used sparingly, and how cooking times vary for different textures and flavors. This understanding enables the AI to apply these principles to new and varied cooking scenarios, like how a skilled chef can create new recipes based on foundational culinary knowledge.
Another key algorithm is Deep Q-Networks (DQN) with human feedback integration. DQN is like a complex maze-solving technique where the AI learns which paths lead to rewards. By adding human feedback, the AI doesn't just find any way to the tip; it finds the best one according to human judgment.
Designing and Modifying Reward Functions
The reward function in RLHF is crucial. It's like a set of instructions that guides the AI on what to aim for. But with RLHF, these instructions are dynamic, evolving with human input. Designing and modifying these reward functions is a delicate balancing act.
One approach is using Preference-Based Reinforcement Learning. Here, the AI is presented with scenarios and learns, which aligns more with human preferences. This method helps fine-tune the AI's decisions, ensuring they're practical and align with human values.
Balancing AI Autonomy and Human Input
Finding the sweet spot between AI making its own decisions and being guided by human feedback is vital in RLHF. It's similar to showing someone how to ride a bike. Initially, you might hold the bike, but eventually, you let go so they can ride independently. Similarly, RLHF aims to strike a balance where the AI is autonomous yet still benefits from human wisdom.
To achieve this, algorithms like Human-In-The-Loop Reinforcement Learning are used. Here, human feedback isn't constant but is provided at crucial learning stages or when the AI faces uncertain situations. This approach ensures the AI is not overly dependent on human input but still benefits from it when necessary.
Thus, the technical strategies in RLHF involve sophisticated algorithms that enable AI to learn from human feedback and ensure that this learning is aligned with human values and intuition. These strategies make AI systems more adaptable, ethical, and effective in handling real-world tasks.
Practical Applications and Modern Use Cases
RLHF in Robotics and Automation
Reinforcement Learning from Human Feedback (RLHF) is making big waves in robotics and automation. Imagine robots in factories or warehouses learning not just to perform tasks but to do them in a way that's safe and efficient, thanks to human guidance. RLHF helps these robots understand not just how to complete a task but how to adapt to new situations – like a robot in a warehouse learning the best paths to take for different types of packages based on human input. This makes robots more innovative, more flexible, and better team players in work environments alongside humans.
Interactive Entertainment and Game AI
In games and entertainment, RLHF is transforming how AI interacts with players. Video game characters and scenarios are becoming more realistic and engaging because they learn from human feedback. This means game AI can adapt to your playing style, making games more challenging and fun. It's like playing chess with a friend who learns your strategies and constantly evolves their game to keep up with you.
Other Innovative Implementations
The impact of RLHF extends beyond robotics and gaming. In educational software, it powers interactive tools that adapt to each student's learning style, using feedback from both students and educators - a concept parallel to how ChatGPT-4 customizes its responses based on the user's input and questions. In healthcare, RLHF aids in developing assistive technologies that learn from patient interactions, much like how ChatGPT-4 knows to provide more accurate information based on user feedback. These examples illustrate how RLHF, a key component in developing AI systems like ChatGPT-4, is not just about enhancing machine intelligence but also about making technology more responsive and attuned to human needs.
Practical Applications and Modern Use Cases
RLHF in Robotics and Automation
Reinforcement Learning from Human Feedback (RLHF) is making big waves in robotics and automation. Imagine robots in factories or warehouses learning not just to perform tasks but to do them in a way that's safe and efficient, thanks to human guidance. RLHF helps these robots understand not just how to complete a task but how to adapt to new situations – like a robot in a warehouse learning the best paths to take for different types of packages based on human input. This makes robots more innovative, more flexible, and better team players in work environments alongside humans.
Interactive Entertainment and Game AI
In games and entertainment, RLHF is transforming how AI interacts with players. Video game characters and scenarios are becoming more realistic and engaging because they learn from human feedback. This means game AI can adapt to your playing style, making games more challenging and fun. It's like playing chess with a friend who learns your strategies and constantly evolves their game to keep up with you.
Other Innovative Implementations
The impact of RLHF extends beyond robotics and gaming. In educational software, it powers interactive tools that adapt to each student's learning style, using feedback from both students and educators - a concept parallel to how ChatGPT-4 customizes its responses based on the user's input and questions. In healthcare, RLHF aids in developing assistive technologies that learn from patient interactions, much like how ChatGPT-4 knows to provide more accurate information based on user feedback. These examples illustrate how RLHF, a key component in developing AI systems like ChatGPT-4, is not just about enhancing machine intelligence but also about making technology more responsive and attuned to human needs.
Practical Applications and Modern Use Cases
RLHF in Robotics and Automation
Reinforcement Learning from Human Feedback (RLHF) is making big waves in robotics and automation. Imagine robots in factories or warehouses learning not just to perform tasks but to do them in a way that's safe and efficient, thanks to human guidance. RLHF helps these robots understand not just how to complete a task but how to adapt to new situations – like a robot in a warehouse learning the best paths to take for different types of packages based on human input. This makes robots more innovative, more flexible, and better team players in work environments alongside humans.
Interactive Entertainment and Game AI
In games and entertainment, RLHF is transforming how AI interacts with players. Video game characters and scenarios are becoming more realistic and engaging because they learn from human feedback. This means game AI can adapt to your playing style, making games more challenging and fun. It's like playing chess with a friend who learns your strategies and constantly evolves their game to keep up with you.
Other Innovative Implementations
The impact of RLHF extends beyond robotics and gaming. In educational software, it powers interactive tools that adapt to each student's learning style, using feedback from both students and educators - a concept parallel to how ChatGPT-4 customizes its responses based on the user's input and questions. In healthcare, RLHF aids in developing assistive technologies that learn from patient interactions, much like how ChatGPT-4 knows to provide more accurate information based on user feedback. These examples illustrate how RLHF, a key component in developing AI systems like ChatGPT-4, is not just about enhancing machine intelligence but also about making technology more responsive and attuned to human needs.
Practical Applications and Modern Use Cases
RLHF in Robotics and Automation
Reinforcement Learning from Human Feedback (RLHF) is making big waves in robotics and automation. Imagine robots in factories or warehouses learning not just to perform tasks but to do them in a way that's safe and efficient, thanks to human guidance. RLHF helps these robots understand not just how to complete a task but how to adapt to new situations – like a robot in a warehouse learning the best paths to take for different types of packages based on human input. This makes robots more innovative, more flexible, and better team players in work environments alongside humans.
Interactive Entertainment and Game AI
In games and entertainment, RLHF is transforming how AI interacts with players. Video game characters and scenarios are becoming more realistic and engaging because they learn from human feedback. This means game AI can adapt to your playing style, making games more challenging and fun. It's like playing chess with a friend who learns your strategies and constantly evolves their game to keep up with you.
Other Innovative Implementations
The impact of RLHF extends beyond robotics and gaming. In educational software, it powers interactive tools that adapt to each student's learning style, using feedback from both students and educators - a concept parallel to how ChatGPT-4 customizes its responses based on the user's input and questions. In healthcare, RLHF aids in developing assistive technologies that learn from patient interactions, much like how ChatGPT-4 knows to provide more accurate information based on user feedback. These examples illustrate how RLHF, a key component in developing AI systems like ChatGPT-4, is not just about enhancing machine intelligence but also about making technology more responsive and attuned to human needs.
Get Hands-on Experience with RLHF
Setting Up a Basic RLHF Environment
Getting started with Reinforcement Learning from Human Feedback (RLHF) involves setting up an essential environment where the AI can learn. This is like preparing a kitchen – you need the right tools and ingredients before you start cooking. In the world of coding, these tools are software libraries like TensorFlow or PyTorch, and the ingredients are your data and algorithms.
The first step is to choose a problem for your AI to solve – anything from navigating a maze to playing a simple game. Then, you set up a simulation environment using a platform like OpenAI Gym, which provides various scenarios for training AI models.
Implementing Human Feedback Mechanisms
Once your environment is ready, the next step is to incorporate human feedback. This is where RLHF differs from traditional reinforcement learning. You introduce mechanisms for a human to interact with the AI, providing guidance and corrections.
One way to do this is through a reward-shaping interface, where the human trainer adjusts the rewards based on the AI's actions. For example, if the AI plays a game, the trainer can give extra points for smart moves or deduct points for mistakes. This feedback helps the AI understand not just how to win but how to play well.
Advanced Coding Techniques and Optimization Strategies
Advanced coding techniques and optimization strategies come into play to refine your RLHF model further. These are like the secret spices in a recipe that make the dish stand out.
Use algorithms like Proximal Policy Optimization (PPO) or Deep Deterministic Policy Gradient (DDPG) to improve the efficiency and stability of learning. Additionally, batch normalization and experience replay can enhance the learning process, making it faster and more consistent.
Illustrating a Current Application of RLHF
Let's take the example of a chatbot, which is similar to how ChatGPT-4 functions. In this scenario, the RLHF model would start by learning from a dataset of conversations. The human feedback comes into play by having trainers evaluate the chatbot's responses. They might reward more engaging, relevant, and coherent replies while penalizing off-topic or inappropriate responses.
This feedback is then used to adjust the chatbot's learning process, ensuring it responds accurately and in a way that is more aligned with human conversational norms. Over time, the chatbot becomes more adept at handling a wide range of interactions, providing responses that are not just correct but also contextually appropriate and engaging.
In short, coding in RLHF involves:
Setting up a learning environment.
Incorporating human feedback.
Using advanced techniques to optimize the learning process.
Through examples like chatbot development, we can see how RLHF is used to create AI that is not just functional but also resonates better with human expectations and behaviors.
Example
Let us explore the basics of Reinforcement Learning from Human Feedback (RLHF) by creating a simple AI agent in a Python environment. Our goal is to illustrate how an AI can learn to perform a task with the guidance of human feedback, which is a fundamental aspect of RLHF. We'll use the 'MountainCarContinuous-v0' environment from OpenAI's Gym toolkit, a popular platform for developing and comparing reinforcement learning algorithms.
In our scenario, the AI agent's task is to control a car in a one-dimensional track, aiming to reach a specific target position. The twist here is the incorporation of human feedback into the learning process. We'll simulate human feedback by adjusting the rewards based on the car's position, guiding the AI towards the desired behavior. This example will provide hands-on experience in setting up an essential RLHF environment, implementing human feedback mechanisms, and understanding the interaction between an AI agent and its learning environment.
Steps to Perform the Task
Install Python: Make sure Python is set up on your computer. Or you can use google colab for an amazing experience and create a Python script.
Install Required Libraries: Open your command line interface and install Gym and PyTorch by running:
pip install gym torchSet Up the Environment. We'll use an essential Gym environment for our example. This script creates an environment where an agent moves in a one-dimensional space.
import gym
import numpy as np
env = gym.make('MountainCarContinuous-v0', new_step_api=True)
# This function represents a step taken by the agent
def step(action):
observation, reward, done, truncated, info = env.step(action)
return observation, reward, done, truncatedNow, define a Basic Agent. Here, we'll define a simple agent that makes random moves. In a more advanced setup, this would be replaced with a neural network.
def basic_agent(observation):
return [np.random.uniform(-1, 1)]Implement Human Feedback. For simplicity, our "human feedback" will be a function that adjusts the reward based on the agent's position.
def human_feedback(observation, reward):
# Increase reward if the agent is closer to the target position
target_position = 0.45
if observation[0] > target_position:
reward += 10
return rewardRun the Training Loop. Now, let's put it all together in a training loop. Usually, this would involve learning from the environment, but our agent will just make random moves for simplicity.
max_timesteps_per_episode = 200 # Set a limit to the number of timesteps per episode
for episode in range(10):
observation = env.reset()
total_reward = 0
for t in range(max_timesteps_per_episode):
action = basic_agent(observation)
observation, reward, done, truncated = step(action)
reward = human_feedback(observation, reward)
total_reward += reward
if done or truncated:
print(f"Episode {episode + 1} finished after {t + 1} timesteps, total reward: {total_reward}")
break
if t == max_timesteps_per_episode - 1:
print(f"Episode {episode + 1} reached the maximum timesteps, total reward: {total_reward}")Run this script in your Python environment. You should see output for each episode indicating how the agent performed. It will give you output like this one:
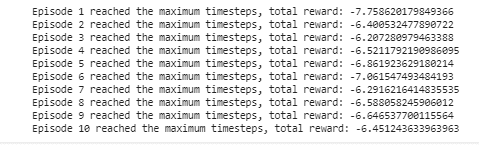
There is no need to worry about these negative values. In the MountainCarContinuous-v0 environment from OpenAI Gym, the reward structure can result in negative values, especially with how the environment and tasks are designed. This environment is unique compared to others because of its reward system. Here are a few key points about its reward structure:
Goal of the Environment: The primary objective in the MountainCarContinuous-v0 environment is to reach the top of a hill. However, the car's engine isn't strong enough to climb the mountain in a straight line, so it must build momentum by going back and forth.
Default Reward System: The reward in this environment is usually structured to encourage reaching the goal with minimal action. A typical reward structure is to give a small negative bonus (penalty) for each time step until the goal is reached. This means the longer it takes to reach the plan, the more negative the total reward will be.
Impact of Human Feedback: In the context of RLHF, you can adjust this reward system. For instance, you might give additional positive rewards (or reduce penalties) when the car moves in the right direction or achieves intermediate goals, like reaching a certain height on the hill.
Possibility of Negative Rewards: Due to the nature of the task and the default reward system, it's common to see negative rewards in this environment. The key is to reduce the number of steps (and thus negative tips) needed to reach the goal or to adjust the reward system to guide the learning process better.
Get Hands-on Experience with RLHF
Setting Up a Basic RLHF Environment
Getting started with Reinforcement Learning from Human Feedback (RLHF) involves setting up an essential environment where the AI can learn. This is like preparing a kitchen – you need the right tools and ingredients before you start cooking. In the world of coding, these tools are software libraries like TensorFlow or PyTorch, and the ingredients are your data and algorithms.
The first step is to choose a problem for your AI to solve – anything from navigating a maze to playing a simple game. Then, you set up a simulation environment using a platform like OpenAI Gym, which provides various scenarios for training AI models.
Implementing Human Feedback Mechanisms
Once your environment is ready, the next step is to incorporate human feedback. This is where RLHF differs from traditional reinforcement learning. You introduce mechanisms for a human to interact with the AI, providing guidance and corrections.
One way to do this is through a reward-shaping interface, where the human trainer adjusts the rewards based on the AI's actions. For example, if the AI plays a game, the trainer can give extra points for smart moves or deduct points for mistakes. This feedback helps the AI understand not just how to win but how to play well.
Advanced Coding Techniques and Optimization Strategies
Advanced coding techniques and optimization strategies come into play to refine your RLHF model further. These are like the secret spices in a recipe that make the dish stand out.
Use algorithms like Proximal Policy Optimization (PPO) or Deep Deterministic Policy Gradient (DDPG) to improve the efficiency and stability of learning. Additionally, batch normalization and experience replay can enhance the learning process, making it faster and more consistent.
Illustrating a Current Application of RLHF
Let's take the example of a chatbot, which is similar to how ChatGPT-4 functions. In this scenario, the RLHF model would start by learning from a dataset of conversations. The human feedback comes into play by having trainers evaluate the chatbot's responses. They might reward more engaging, relevant, and coherent replies while penalizing off-topic or inappropriate responses.
This feedback is then used to adjust the chatbot's learning process, ensuring it responds accurately and in a way that is more aligned with human conversational norms. Over time, the chatbot becomes more adept at handling a wide range of interactions, providing responses that are not just correct but also contextually appropriate and engaging.
In short, coding in RLHF involves:
Setting up a learning environment.
Incorporating human feedback.
Using advanced techniques to optimize the learning process.
Through examples like chatbot development, we can see how RLHF is used to create AI that is not just functional but also resonates better with human expectations and behaviors.
Example
Let us explore the basics of Reinforcement Learning from Human Feedback (RLHF) by creating a simple AI agent in a Python environment. Our goal is to illustrate how an AI can learn to perform a task with the guidance of human feedback, which is a fundamental aspect of RLHF. We'll use the 'MountainCarContinuous-v0' environment from OpenAI's Gym toolkit, a popular platform for developing and comparing reinforcement learning algorithms.
In our scenario, the AI agent's task is to control a car in a one-dimensional track, aiming to reach a specific target position. The twist here is the incorporation of human feedback into the learning process. We'll simulate human feedback by adjusting the rewards based on the car's position, guiding the AI towards the desired behavior. This example will provide hands-on experience in setting up an essential RLHF environment, implementing human feedback mechanisms, and understanding the interaction between an AI agent and its learning environment.
Steps to Perform the Task
Install Python: Make sure Python is set up on your computer. Or you can use google colab for an amazing experience and create a Python script.
Install Required Libraries: Open your command line interface and install Gym and PyTorch by running:
pip install gym torchSet Up the Environment. We'll use an essential Gym environment for our example. This script creates an environment where an agent moves in a one-dimensional space.
import gym
import numpy as np
env = gym.make('MountainCarContinuous-v0', new_step_api=True)
# This function represents a step taken by the agent
def step(action):
observation, reward, done, truncated, info = env.step(action)
return observation, reward, done, truncatedNow, define a Basic Agent. Here, we'll define a simple agent that makes random moves. In a more advanced setup, this would be replaced with a neural network.
def basic_agent(observation):
return [np.random.uniform(-1, 1)]Implement Human Feedback. For simplicity, our "human feedback" will be a function that adjusts the reward based on the agent's position.
def human_feedback(observation, reward):
# Increase reward if the agent is closer to the target position
target_position = 0.45
if observation[0] > target_position:
reward += 10
return rewardRun the Training Loop. Now, let's put it all together in a training loop. Usually, this would involve learning from the environment, but our agent will just make random moves for simplicity.
max_timesteps_per_episode = 200 # Set a limit to the number of timesteps per episode
for episode in range(10):
observation = env.reset()
total_reward = 0
for t in range(max_timesteps_per_episode):
action = basic_agent(observation)
observation, reward, done, truncated = step(action)
reward = human_feedback(observation, reward)
total_reward += reward
if done or truncated:
print(f"Episode {episode + 1} finished after {t + 1} timesteps, total reward: {total_reward}")
break
if t == max_timesteps_per_episode - 1:
print(f"Episode {episode + 1} reached the maximum timesteps, total reward: {total_reward}")Run this script in your Python environment. You should see output for each episode indicating how the agent performed. It will give you output like this one:
There is no need to worry about these negative values. In the MountainCarContinuous-v0 environment from OpenAI Gym, the reward structure can result in negative values, especially with how the environment and tasks are designed. This environment is unique compared to others because of its reward system. Here are a few key points about its reward structure:
Goal of the Environment: The primary objective in the MountainCarContinuous-v0 environment is to reach the top of a hill. However, the car's engine isn't strong enough to climb the mountain in a straight line, so it must build momentum by going back and forth.
Default Reward System: The reward in this environment is usually structured to encourage reaching the goal with minimal action. A typical reward structure is to give a small negative bonus (penalty) for each time step until the goal is reached. This means the longer it takes to reach the plan, the more negative the total reward will be.
Impact of Human Feedback: In the context of RLHF, you can adjust this reward system. For instance, you might give additional positive rewards (or reduce penalties) when the car moves in the right direction or achieves intermediate goals, like reaching a certain height on the hill.
Possibility of Negative Rewards: Due to the nature of the task and the default reward system, it's common to see negative rewards in this environment. The key is to reduce the number of steps (and thus negative tips) needed to reach the goal or to adjust the reward system to guide the learning process better.
Get Hands-on Experience with RLHF
Setting Up a Basic RLHF Environment
Getting started with Reinforcement Learning from Human Feedback (RLHF) involves setting up an essential environment where the AI can learn. This is like preparing a kitchen – you need the right tools and ingredients before you start cooking. In the world of coding, these tools are software libraries like TensorFlow or PyTorch, and the ingredients are your data and algorithms.
The first step is to choose a problem for your AI to solve – anything from navigating a maze to playing a simple game. Then, you set up a simulation environment using a platform like OpenAI Gym, which provides various scenarios for training AI models.
Implementing Human Feedback Mechanisms
Once your environment is ready, the next step is to incorporate human feedback. This is where RLHF differs from traditional reinforcement learning. You introduce mechanisms for a human to interact with the AI, providing guidance and corrections.
One way to do this is through a reward-shaping interface, where the human trainer adjusts the rewards based on the AI's actions. For example, if the AI plays a game, the trainer can give extra points for smart moves or deduct points for mistakes. This feedback helps the AI understand not just how to win but how to play well.
Advanced Coding Techniques and Optimization Strategies
Advanced coding techniques and optimization strategies come into play to refine your RLHF model further. These are like the secret spices in a recipe that make the dish stand out.
Use algorithms like Proximal Policy Optimization (PPO) or Deep Deterministic Policy Gradient (DDPG) to improve the efficiency and stability of learning. Additionally, batch normalization and experience replay can enhance the learning process, making it faster and more consistent.
Illustrating a Current Application of RLHF
Let's take the example of a chatbot, which is similar to how ChatGPT-4 functions. In this scenario, the RLHF model would start by learning from a dataset of conversations. The human feedback comes into play by having trainers evaluate the chatbot's responses. They might reward more engaging, relevant, and coherent replies while penalizing off-topic or inappropriate responses.
This feedback is then used to adjust the chatbot's learning process, ensuring it responds accurately and in a way that is more aligned with human conversational norms. Over time, the chatbot becomes more adept at handling a wide range of interactions, providing responses that are not just correct but also contextually appropriate and engaging.
In short, coding in RLHF involves:
Setting up a learning environment.
Incorporating human feedback.
Using advanced techniques to optimize the learning process.
Through examples like chatbot development, we can see how RLHF is used to create AI that is not just functional but also resonates better with human expectations and behaviors.
Example
Let us explore the basics of Reinforcement Learning from Human Feedback (RLHF) by creating a simple AI agent in a Python environment. Our goal is to illustrate how an AI can learn to perform a task with the guidance of human feedback, which is a fundamental aspect of RLHF. We'll use the 'MountainCarContinuous-v0' environment from OpenAI's Gym toolkit, a popular platform for developing and comparing reinforcement learning algorithms.
In our scenario, the AI agent's task is to control a car in a one-dimensional track, aiming to reach a specific target position. The twist here is the incorporation of human feedback into the learning process. We'll simulate human feedback by adjusting the rewards based on the car's position, guiding the AI towards the desired behavior. This example will provide hands-on experience in setting up an essential RLHF environment, implementing human feedback mechanisms, and understanding the interaction between an AI agent and its learning environment.
Steps to Perform the Task
Install Python: Make sure Python is set up on your computer. Or you can use google colab for an amazing experience and create a Python script.
Install Required Libraries: Open your command line interface and install Gym and PyTorch by running:
pip install gym torchSet Up the Environment. We'll use an essential Gym environment for our example. This script creates an environment where an agent moves in a one-dimensional space.
import gym
import numpy as np
env = gym.make('MountainCarContinuous-v0', new_step_api=True)
# This function represents a step taken by the agent
def step(action):
observation, reward, done, truncated, info = env.step(action)
return observation, reward, done, truncatedNow, define a Basic Agent. Here, we'll define a simple agent that makes random moves. In a more advanced setup, this would be replaced with a neural network.
def basic_agent(observation):
return [np.random.uniform(-1, 1)]Implement Human Feedback. For simplicity, our "human feedback" will be a function that adjusts the reward based on the agent's position.
def human_feedback(observation, reward):
# Increase reward if the agent is closer to the target position
target_position = 0.45
if observation[0] > target_position:
reward += 10
return rewardRun the Training Loop. Now, let's put it all together in a training loop. Usually, this would involve learning from the environment, but our agent will just make random moves for simplicity.
max_timesteps_per_episode = 200 # Set a limit to the number of timesteps per episode
for episode in range(10):
observation = env.reset()
total_reward = 0
for t in range(max_timesteps_per_episode):
action = basic_agent(observation)
observation, reward, done, truncated = step(action)
reward = human_feedback(observation, reward)
total_reward += reward
if done or truncated:
print(f"Episode {episode + 1} finished after {t + 1} timesteps, total reward: {total_reward}")
break
if t == max_timesteps_per_episode - 1:
print(f"Episode {episode + 1} reached the maximum timesteps, total reward: {total_reward}")Run this script in your Python environment. You should see output for each episode indicating how the agent performed. It will give you output like this one:
There is no need to worry about these negative values. In the MountainCarContinuous-v0 environment from OpenAI Gym, the reward structure can result in negative values, especially with how the environment and tasks are designed. This environment is unique compared to others because of its reward system. Here are a few key points about its reward structure:
Goal of the Environment: The primary objective in the MountainCarContinuous-v0 environment is to reach the top of a hill. However, the car's engine isn't strong enough to climb the mountain in a straight line, so it must build momentum by going back and forth.
Default Reward System: The reward in this environment is usually structured to encourage reaching the goal with minimal action. A typical reward structure is to give a small negative bonus (penalty) for each time step until the goal is reached. This means the longer it takes to reach the plan, the more negative the total reward will be.
Impact of Human Feedback: In the context of RLHF, you can adjust this reward system. For instance, you might give additional positive rewards (or reduce penalties) when the car moves in the right direction or achieves intermediate goals, like reaching a certain height on the hill.
Possibility of Negative Rewards: Due to the nature of the task and the default reward system, it's common to see negative rewards in this environment. The key is to reduce the number of steps (and thus negative tips) needed to reach the goal or to adjust the reward system to guide the learning process better.
Get Hands-on Experience with RLHF
Setting Up a Basic RLHF Environment
Getting started with Reinforcement Learning from Human Feedback (RLHF) involves setting up an essential environment where the AI can learn. This is like preparing a kitchen – you need the right tools and ingredients before you start cooking. In the world of coding, these tools are software libraries like TensorFlow or PyTorch, and the ingredients are your data and algorithms.
The first step is to choose a problem for your AI to solve – anything from navigating a maze to playing a simple game. Then, you set up a simulation environment using a platform like OpenAI Gym, which provides various scenarios for training AI models.
Implementing Human Feedback Mechanisms
Once your environment is ready, the next step is to incorporate human feedback. This is where RLHF differs from traditional reinforcement learning. You introduce mechanisms for a human to interact with the AI, providing guidance and corrections.
One way to do this is through a reward-shaping interface, where the human trainer adjusts the rewards based on the AI's actions. For example, if the AI plays a game, the trainer can give extra points for smart moves or deduct points for mistakes. This feedback helps the AI understand not just how to win but how to play well.
Advanced Coding Techniques and Optimization Strategies
Advanced coding techniques and optimization strategies come into play to refine your RLHF model further. These are like the secret spices in a recipe that make the dish stand out.
Use algorithms like Proximal Policy Optimization (PPO) or Deep Deterministic Policy Gradient (DDPG) to improve the efficiency and stability of learning. Additionally, batch normalization and experience replay can enhance the learning process, making it faster and more consistent.
Illustrating a Current Application of RLHF
Let's take the example of a chatbot, which is similar to how ChatGPT-4 functions. In this scenario, the RLHF model would start by learning from a dataset of conversations. The human feedback comes into play by having trainers evaluate the chatbot's responses. They might reward more engaging, relevant, and coherent replies while penalizing off-topic or inappropriate responses.
This feedback is then used to adjust the chatbot's learning process, ensuring it responds accurately and in a way that is more aligned with human conversational norms. Over time, the chatbot becomes more adept at handling a wide range of interactions, providing responses that are not just correct but also contextually appropriate and engaging.
In short, coding in RLHF involves:
Setting up a learning environment.
Incorporating human feedback.
Using advanced techniques to optimize the learning process.
Through examples like chatbot development, we can see how RLHF is used to create AI that is not just functional but also resonates better with human expectations and behaviors.
Example
Let us explore the basics of Reinforcement Learning from Human Feedback (RLHF) by creating a simple AI agent in a Python environment. Our goal is to illustrate how an AI can learn to perform a task with the guidance of human feedback, which is a fundamental aspect of RLHF. We'll use the 'MountainCarContinuous-v0' environment from OpenAI's Gym toolkit, a popular platform for developing and comparing reinforcement learning algorithms.
In our scenario, the AI agent's task is to control a car in a one-dimensional track, aiming to reach a specific target position. The twist here is the incorporation of human feedback into the learning process. We'll simulate human feedback by adjusting the rewards based on the car's position, guiding the AI towards the desired behavior. This example will provide hands-on experience in setting up an essential RLHF environment, implementing human feedback mechanisms, and understanding the interaction between an AI agent and its learning environment.
Steps to Perform the Task
Install Python: Make sure Python is set up on your computer. Or you can use google colab for an amazing experience and create a Python script.
Install Required Libraries: Open your command line interface and install Gym and PyTorch by running:
pip install gym torchSet Up the Environment. We'll use an essential Gym environment for our example. This script creates an environment where an agent moves in a one-dimensional space.
import gym
import numpy as np
env = gym.make('MountainCarContinuous-v0', new_step_api=True)
# This function represents a step taken by the agent
def step(action):
observation, reward, done, truncated, info = env.step(action)
return observation, reward, done, truncatedNow, define a Basic Agent. Here, we'll define a simple agent that makes random moves. In a more advanced setup, this would be replaced with a neural network.
def basic_agent(observation):
return [np.random.uniform(-1, 1)]Implement Human Feedback. For simplicity, our "human feedback" will be a function that adjusts the reward based on the agent's position.
def human_feedback(observation, reward):
# Increase reward if the agent is closer to the target position
target_position = 0.45
if observation[0] > target_position:
reward += 10
return rewardRun the Training Loop. Now, let's put it all together in a training loop. Usually, this would involve learning from the environment, but our agent will just make random moves for simplicity.
max_timesteps_per_episode = 200 # Set a limit to the number of timesteps per episode
for episode in range(10):
observation = env.reset()
total_reward = 0
for t in range(max_timesteps_per_episode):
action = basic_agent(observation)
observation, reward, done, truncated = step(action)
reward = human_feedback(observation, reward)
total_reward += reward
if done or truncated:
print(f"Episode {episode + 1} finished after {t + 1} timesteps, total reward: {total_reward}")
break
if t == max_timesteps_per_episode - 1:
print(f"Episode {episode + 1} reached the maximum timesteps, total reward: {total_reward}")Run this script in your Python environment. You should see output for each episode indicating how the agent performed. It will give you output like this one:
There is no need to worry about these negative values. In the MountainCarContinuous-v0 environment from OpenAI Gym, the reward structure can result in negative values, especially with how the environment and tasks are designed. This environment is unique compared to others because of its reward system. Here are a few key points about its reward structure:
Goal of the Environment: The primary objective in the MountainCarContinuous-v0 environment is to reach the top of a hill. However, the car's engine isn't strong enough to climb the mountain in a straight line, so it must build momentum by going back and forth.
Default Reward System: The reward in this environment is usually structured to encourage reaching the goal with minimal action. A typical reward structure is to give a small negative bonus (penalty) for each time step until the goal is reached. This means the longer it takes to reach the plan, the more negative the total reward will be.
Impact of Human Feedback: In the context of RLHF, you can adjust this reward system. For instance, you might give additional positive rewards (or reduce penalties) when the car moves in the right direction or achieves intermediate goals, like reaching a certain height on the hill.
Possibility of Negative Rewards: Due to the nature of the task and the default reward system, it's common to see negative rewards in this environment. The key is to reduce the number of steps (and thus negative tips) needed to reach the goal or to adjust the reward system to guide the learning process better.
Overcoming Challenges and Ethical Considerations
Addressing Bias and Scalability Issues
When we bring together humans and AI, especially in Reinforcement Learning from Human Feedback (RLHF), two significant challenges often come up: bias and scalability.
Bias is like adding too much salt to a recipe; it can spoil the whole dish. In RLHF, discrimination happens when the human feedback AI learns from isn't fair or balanced. For example, if the people giving feedback have specific preferences or prejudices, the AI might learn these too. To fix this, we need a mix of different people giving feedback, much like getting many taste-testers for a new recipe. This way, the AI learns from various perspectives, making it more balanced and fairer.
Scalability is about how well our RLHF setup can grow. Imagine teaching one student to cook is manageable, but teaching a hundred all at once is a different story. Teaching AI to handle simple tasks is more accessible than complex ones involving lots of data or decisions. To overcome this, we need innovative ways to scale up, like using more powerful computers or more intelligent algorithms, so our AI can learn from large and complex situations without getting overwhelmed.
Ethical Implications of Human-AI Interaction
Ethical concerns in human-AI interaction are like kitchen safety rules; they keep everyone safe and happy. When AI learns from humans, we need to think about how this affects the AI's decisions and the people it interacts with.
One big concern is responsibility. If an AI trained by humans makes a mistake, who is responsible? Is it the people who designed it, those who taught it, or the AI itself? It's like if someone follows a recipe and it doesn't turn out right, who's to blame – the recipe writer, the cook, or the recipe itself? We need clear rules about this in the world of AI.
Another concern is privacy. When AI learns from human feedback, it often needs access to personal data. It's like needing to know someone's food allergies before cooking for them. We must ensure this information is kept safe and used respectfully, respecting people's privacy and consent.
In short, overcoming challenges in RLHF involves:
Addressing biases to ensure fairness.
Scaling the technology responsibly.
Considering the ethical implications of how AI interacts with and learns from humans.
These steps are crucial to creating AI that is not only smart but also respectful and safe for everyone.
Overcoming Challenges and Ethical Considerations
Addressing Bias and Scalability Issues
When we bring together humans and AI, especially in Reinforcement Learning from Human Feedback (RLHF), two significant challenges often come up: bias and scalability.
Bias is like adding too much salt to a recipe; it can spoil the whole dish. In RLHF, discrimination happens when the human feedback AI learns from isn't fair or balanced. For example, if the people giving feedback have specific preferences or prejudices, the AI might learn these too. To fix this, we need a mix of different people giving feedback, much like getting many taste-testers for a new recipe. This way, the AI learns from various perspectives, making it more balanced and fairer.
Scalability is about how well our RLHF setup can grow. Imagine teaching one student to cook is manageable, but teaching a hundred all at once is a different story. Teaching AI to handle simple tasks is more accessible than complex ones involving lots of data or decisions. To overcome this, we need innovative ways to scale up, like using more powerful computers or more intelligent algorithms, so our AI can learn from large and complex situations without getting overwhelmed.
Ethical Implications of Human-AI Interaction
Ethical concerns in human-AI interaction are like kitchen safety rules; they keep everyone safe and happy. When AI learns from humans, we need to think about how this affects the AI's decisions and the people it interacts with.
One big concern is responsibility. If an AI trained by humans makes a mistake, who is responsible? Is it the people who designed it, those who taught it, or the AI itself? It's like if someone follows a recipe and it doesn't turn out right, who's to blame – the recipe writer, the cook, or the recipe itself? We need clear rules about this in the world of AI.
Another concern is privacy. When AI learns from human feedback, it often needs access to personal data. It's like needing to know someone's food allergies before cooking for them. We must ensure this information is kept safe and used respectfully, respecting people's privacy and consent.
In short, overcoming challenges in RLHF involves:
Addressing biases to ensure fairness.
Scaling the technology responsibly.
Considering the ethical implications of how AI interacts with and learns from humans.
These steps are crucial to creating AI that is not only smart but also respectful and safe for everyone.
Overcoming Challenges and Ethical Considerations
Addressing Bias and Scalability Issues
When we bring together humans and AI, especially in Reinforcement Learning from Human Feedback (RLHF), two significant challenges often come up: bias and scalability.
Bias is like adding too much salt to a recipe; it can spoil the whole dish. In RLHF, discrimination happens when the human feedback AI learns from isn't fair or balanced. For example, if the people giving feedback have specific preferences or prejudices, the AI might learn these too. To fix this, we need a mix of different people giving feedback, much like getting many taste-testers for a new recipe. This way, the AI learns from various perspectives, making it more balanced and fairer.
Scalability is about how well our RLHF setup can grow. Imagine teaching one student to cook is manageable, but teaching a hundred all at once is a different story. Teaching AI to handle simple tasks is more accessible than complex ones involving lots of data or decisions. To overcome this, we need innovative ways to scale up, like using more powerful computers or more intelligent algorithms, so our AI can learn from large and complex situations without getting overwhelmed.
Ethical Implications of Human-AI Interaction
Ethical concerns in human-AI interaction are like kitchen safety rules; they keep everyone safe and happy. When AI learns from humans, we need to think about how this affects the AI's decisions and the people it interacts with.
One big concern is responsibility. If an AI trained by humans makes a mistake, who is responsible? Is it the people who designed it, those who taught it, or the AI itself? It's like if someone follows a recipe and it doesn't turn out right, who's to blame – the recipe writer, the cook, or the recipe itself? We need clear rules about this in the world of AI.
Another concern is privacy. When AI learns from human feedback, it often needs access to personal data. It's like needing to know someone's food allergies before cooking for them. We must ensure this information is kept safe and used respectfully, respecting people's privacy and consent.
In short, overcoming challenges in RLHF involves:
Addressing biases to ensure fairness.
Scaling the technology responsibly.
Considering the ethical implications of how AI interacts with and learns from humans.
These steps are crucial to creating AI that is not only smart but also respectful and safe for everyone.
Overcoming Challenges and Ethical Considerations
Addressing Bias and Scalability Issues
When we bring together humans and AI, especially in Reinforcement Learning from Human Feedback (RLHF), two significant challenges often come up: bias and scalability.
Bias is like adding too much salt to a recipe; it can spoil the whole dish. In RLHF, discrimination happens when the human feedback AI learns from isn't fair or balanced. For example, if the people giving feedback have specific preferences or prejudices, the AI might learn these too. To fix this, we need a mix of different people giving feedback, much like getting many taste-testers for a new recipe. This way, the AI learns from various perspectives, making it more balanced and fairer.
Scalability is about how well our RLHF setup can grow. Imagine teaching one student to cook is manageable, but teaching a hundred all at once is a different story. Teaching AI to handle simple tasks is more accessible than complex ones involving lots of data or decisions. To overcome this, we need innovative ways to scale up, like using more powerful computers or more intelligent algorithms, so our AI can learn from large and complex situations without getting overwhelmed.
Ethical Implications of Human-AI Interaction
Ethical concerns in human-AI interaction are like kitchen safety rules; they keep everyone safe and happy. When AI learns from humans, we need to think about how this affects the AI's decisions and the people it interacts with.
One big concern is responsibility. If an AI trained by humans makes a mistake, who is responsible? Is it the people who designed it, those who taught it, or the AI itself? It's like if someone follows a recipe and it doesn't turn out right, who's to blame – the recipe writer, the cook, or the recipe itself? We need clear rules about this in the world of AI.
Another concern is privacy. When AI learns from human feedback, it often needs access to personal data. It's like needing to know someone's food allergies before cooking for them. We must ensure this information is kept safe and used respectfully, respecting people's privacy and consent.
In short, overcoming challenges in RLHF involves:
Addressing biases to ensure fairness.
Scaling the technology responsibly.
Considering the ethical implications of how AI interacts with and learns from humans.
These steps are crucial to creating AI that is not only smart but also respectful and safe for everyone.
Conclusion
In conclusion, Reinforcement Learning from Human Feedback (RLHF) represents a significant leap forward in AI, blending machines' computational prowess with the nuanced understanding of humans. Throughout this exploration, we've seen how RLHF is evolving from its foundational concepts and technical strategies to its practical applications in diverse fields like robotics, gaming, and beyond. Incorporating human feedback into AI learning not only addresses challenges like bias and ethical considerations but also opens up exciting avenues for future research and development. As we stand at the brink of this technological evolution, RLHF promises a future where AI is a tool and a collaborative partner, enhancing human capabilities and driving innovation across various sectors. This journey into RLHF showcases the transformative potential of human-guided AI in creating more innovative, more responsive, and ethically aware technologies for the betterment of society.
Conclusion
In conclusion, Reinforcement Learning from Human Feedback (RLHF) represents a significant leap forward in AI, blending machines' computational prowess with the nuanced understanding of humans. Throughout this exploration, we've seen how RLHF is evolving from its foundational concepts and technical strategies to its practical applications in diverse fields like robotics, gaming, and beyond. Incorporating human feedback into AI learning not only addresses challenges like bias and ethical considerations but also opens up exciting avenues for future research and development. As we stand at the brink of this technological evolution, RLHF promises a future where AI is a tool and a collaborative partner, enhancing human capabilities and driving innovation across various sectors. This journey into RLHF showcases the transformative potential of human-guided AI in creating more innovative, more responsive, and ethically aware technologies for the betterment of society.
Conclusion
In conclusion, Reinforcement Learning from Human Feedback (RLHF) represents a significant leap forward in AI, blending machines' computational prowess with the nuanced understanding of humans. Throughout this exploration, we've seen how RLHF is evolving from its foundational concepts and technical strategies to its practical applications in diverse fields like robotics, gaming, and beyond. Incorporating human feedback into AI learning not only addresses challenges like bias and ethical considerations but also opens up exciting avenues for future research and development. As we stand at the brink of this technological evolution, RLHF promises a future where AI is a tool and a collaborative partner, enhancing human capabilities and driving innovation across various sectors. This journey into RLHF showcases the transformative potential of human-guided AI in creating more innovative, more responsive, and ethically aware technologies for the betterment of society.
Conclusion
In conclusion, Reinforcement Learning from Human Feedback (RLHF) represents a significant leap forward in AI, blending machines' computational prowess with the nuanced understanding of humans. Throughout this exploration, we've seen how RLHF is evolving from its foundational concepts and technical strategies to its practical applications in diverse fields like robotics, gaming, and beyond. Incorporating human feedback into AI learning not only addresses challenges like bias and ethical considerations but also opens up exciting avenues for future research and development. As we stand at the brink of this technological evolution, RLHF promises a future where AI is a tool and a collaborative partner, enhancing human capabilities and driving innovation across various sectors. This journey into RLHF showcases the transformative potential of human-guided AI in creating more innovative, more responsive, and ethically aware technologies for the betterment of society.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.
Osama Akhlaq
Technical Writer
A passionate Computer Scientist exploring different domains of technology and applying technical knowledge to resolve real-world problems.